Figure 1 - paper forms

Since I first started in the software industry in the late 1970s I have worked on enterprise applications. In those days, which was well before personal computers became readily available, computer hardware was large, slow and very expensive, and it was only enterprises that could afford such items. In time both the size and the cost of computers became smaller, the processing speed became faster, and the range of software applications has expanded to include the requirements of individuals and is no longer limited to large organisations with big budgets.
What distinguishes an enterprise application from other pieces of software? In his article Enterprise Application, the author Martin Fowler, who is also the author of Patterns of Enterprise Application Architecture (PoEAA) identifies the main characteristics as follows:
This article in webopedia.com provides the following description:
An enterprise application is the phrase used to describe applications (or software) that a business would use to assist the organization in solving enterprise problems. When the word "enterprise" is combined with "application," it usually refers to a software platform that is too large and too complex for individual or small business use.
Although an organisation may have a website which is open to members of the public, I consider the website to be separate from the enterprise application for the reasons explained in Web Site vs Web Application. Pay particular attention to the Comparison Matrix.
In the pre-internet days all enterprise applications were developed for the desktop. A significant number of these applications are still running for the simple reason that they are too large, too complex or too expensive to replace. When the internet arrived most organisations left their back-end enterprise application alone and built an entirely separate front-end web site, possibly using a different team of programmers who used a different programming language. Some organisations have gradually rewritten their aging applications to take advantage of the latest languages, possibly stirred on by the fact that programmers with expertise in the old languages are becoming a dying breed. Some organisations develop new enterprise applications entirely from scratch so as not to become encumbered by archaic architectures and practices.
If you are thinking of building your own enterprise application then you should be aware that it is a large and complex task that will require many man-years of effort. You should not think of it as a single system but a collection of several integrated subsystems each of which covers a different aspect of the business. To avoid data duplication the information which is maintained in one subsystem should be readily available to any of the others. So how do you tackle such a task? Do you adopt a top-down or bottom-up approach? Do you have a separate team of developers for each subsystem? Do you allow each team of programmers to develop their particular subsystem in isolation and tackle integration separately later? Do you get each team to build their subsystem components on a common framework which would avoid such integration issues?
The purpose of this article is to describe the steps which I took when I began developing an enterprise application in 2007 which is now marketed as the GM-X Application Suite. This is a multi-module system that was developed specifically as a pure web application. It was not developed for the desktop with a web interface bolted on at a later date. It currently contains 17 subsystems of which 4 are mandatory while the rest are optional. All these subsystems were developed using the RADICORE framework which provides a great deal of common functionality and which makes integration a complete non-issue.
Before you start any complex task you should be aware of the "big picture" before you attempt to bog yourself down with details. This picture should start by identifying the boundaries of the task in question so that you know what needs to be included and what needs to be excluded. In the pre-computer days the procedures followed by organisations to keep track of their business dealings were completely manual, as shown in Figure 1. The post-computer replacement is shown in Figure 2.
Figure 1 - paper forms
In a world without computers everything is paper-based. A person sits at a desk, fills in the paper form that is appropriate to that activity, then stores the form in a filing cabinet. This has obvious disadvantages:
Now compare this with the modern alternative:
Figure 2 - electronic forms

A computerised system operates slightly differently - a person sits at a desk, fills in an electronic form on a computer screen, then presses a button to store the data in an electronic filing cabinet called a database. This may seem very similar to the old fashioned way, but the differences are quite significant:
While the pre-computer system relies on the availability of a supply of paper forms, the modern version has a different vulnerability - if the computer system goes down, either through a hardware failure or a cut in the electricity supply, then you are well and truly stuffed. Fortunately most enterprises recognise this vulnerability and have built-in redundancy and backups so that if one piece of hardware fails it can switch to a backup. Some may even have backup generators in case of a failure with the power supply.
Now that you have the big picture it is now time to expand this to show the various types of component that are usually provided in an enterprise application.
While an enterprise application such as GM-X can be regarded as a single piece of software it is actually a collection of independent yet integrated subsystems. Each of these subsystems has its own database and its own collection of transactions within a separate directory on the file system. While a minimum subset of modules is required, such as MENU, AUDIT, WORKFLOW and PARTY, all the rest are optional. This means that clients need only install those subsystems which they actually need. It also means that new subsystems can be developed and installed as and when necessary.
In some organisations it is possible for these subsystems to be provided by different vendors, perhaps written in different programming languages and using different DBMS servers. This leads to a problem when trying to treat these separate parts as a integrated whole as certain pieces of data, such as names and addresses, may be duplicated, which leads to synchronisation issues. Special software may need to be written to act as a bridge between one subsystem and another. One way to reduce such issues would be to have as many subsystems as possible provided by the same vendor and using the same framework.
Some organisations like to put all their database tables into a single database, but modern Database Management Systems (DBMS), such as MySQL, Postgresql, Oracle and SQL Server, employ a concept known as a database server. Once a connection to a database server has been made it is then possible to create one or more databases in that server, and for each database to have its own set of tables. This structure is shown in Figure 3:
Figure 3 - Server -> Database -> Table

Each table (relation) then has its own set of columns, keys and relationships.
After connecting to a database server it is possible to make any database the default, which means that its tables can be referenced without being qualified with their database name, and it is also possible to construct SQL queries which reference tables from several different databases at the same time. Any tables which are not in the current default database must be qualified with their database name.
Each of the subsystems in GM-X is a separate entity, so only those databases for active subsystems need be installed. This prevents the single central database from having sets of unused tables.
By this I mean a User Transaction, not a Database Transaction. The application must have a task component for each activity that a user may require in order to carry out their daily duties. Some of these tasks may be simple enquiries or more complex reports, while others could involve updating the database. Some of these updates may trigger other activities within the application, possibly involving other members of staff. For example, when a Sales Order is authorised it may create a Pick List, and when a Pick List is processed it generates a Shipment.
Each task requires the design of a form or screen (known as the User Interface or UI) specific for that task, and a database design which is capable of storing the relevant data in an efficient structure. The software for that task then needs to handle the transfer of data between the form and the database, including all data validation and the processing of business rules.
It is not uncommon for a large enterprise application to have thousands of tasks, usually divided into smaller subsystems, as shown in Figure 4:
Figure 4 - Application -> Subsystem -> Task

It is also usual in large applications to have these details stored in a database. In the RADICORE framework this information is stored in the MNU_SUBSYSTEM and MNU_TASK tables.
In my early days it was common practice to have a single task to handle all the operations that could be performed on a database table. For simple tables this would result in all the operations shown in Figure 5.
Figure 5 - a family of forms
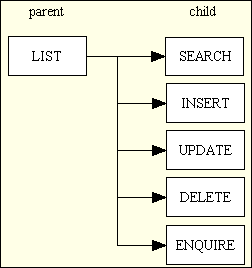
However, when I built my first framework in 1985 I abandoned this idea in favour of having a separate task for each of those operations. This idea is discussed in Component Design - Large and Complex vs. Small and Simple. I then recognised that in an application with many database tables it is common to want to perform identical operations on different database tables. When you identify large numbers of "things" which have something in common then if you are able to isolate and encapsulate that which is shared from that which is unique you should be able write reusable components to provide shared code so that you only need to write new code which identifies that which is unique. The ability to identify repeating patterns of behaviour is one thing that separates a good programmer from a code monkey. Another even rarer thing is the ability to write code which implements those patterns because once you have written a piece of code which implements a pattern that code should be reusable when you come to implement another instance of that pattern. The more times you can reuse an existing piece of code then the less code you have to write, and while it is a programmer's job to write code the ability to achieve results by writing less code is something that separates the men from the boys.
When an application has thousands of tasks a user needs a quick method of identifying and activating the particular task he wishes to run. Many years ago I worked on systems where the user had to type the task identity on the command line in order to run that task's program. This was later replaced by a form with a text box into which the task identity could be entered. This primitive mechanism required that the user know precisely what to enter to call up the correct task, and the larger the system became the more difficult it became to remember each task's identity.
The next logical step was to build a collection of menus into the application. Just as in a restaurant a menu is a list of meal options, in a software application a menu is a list of task options. Each item in this list provides a meaningful description of a particular task, and the user simply has to pick an item to run that task. In the pre-internet days each item had a number, and the user had to enter that number into a text box, while in modern web applications each menu item is a separate hyperlink.
In a large application with thousands of tasks it would not be user-friendly to have a single menu list as it would take ages to find the desired task on that list. Instead of having a single menu page the application therefore has a large collection of smaller menu pages, each with its own unique identity, and the items on each menu page could point to either a sub-menu or an actual task. It is therefore possible to construct a hierarchy of menus and sub-menus which can be as deep as is necessary. An example is shown in Figure 6:
Figure 6 - a hierarchy of menus and sub-menus
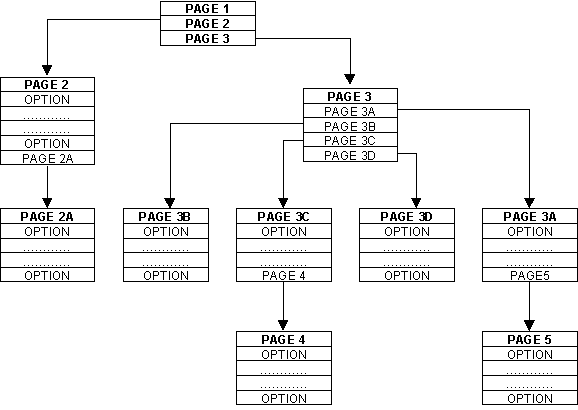
In this hierarchy the top-level menu would simply be a list of the available subsystems, and each subsystem menu would then provide access to the tasks within that particular subsystem in another collection of sub-menus. This arrangement then allows the user to start at the top menu, then drill down to the relevant sub-menu which shows the desired task so that it can be selected. This is much easier than trying to scroll down a list of several thousand entries.
In the first applications on which I worked this menu hierarchy was hard-coded into a separate menu component, with a separate sub-component for each sub-menu. This was a tedious task as it meant that the menu hierarchy had to be designed up front before it could be coded, and could not be amended without changing the code. I abandoned this idea in 1985 when I developed my first framework in favour of having the menu structure defined on a database table. All I had to do was build a collection of tasks to maintain the contents of this database table and all future menus could be created or amended by running an online task instead of having to write or amend pieces of program code.
While developing my enterprise applications I also identified two different types of menu:
For example, in the forms family shown in Figure 5 the parent task will have a button in the Menu Bar while all the child tasks will have buttons in the Navigation Bar when their parent is the current task. This means that you have to select the parent task before the buttons for any of the child tasks become visible.
In the RADICORE framework this information is stored in the MNU_TASK, MNU_MENU and MNU_NAV_BUTTON tables.
When a person accesses an enterprise application it is usual for them to identify themselves via some sort of LOGON screen so that the system knows who they are. The concept of an anonymous user does not exist. Each user will require a unique identity and a password, and probably an email address for web applications. There may also be a company policy regarding password formats and the interval after which they must be changed.
This information is usually in addition to other security features.
When an application has a large number of transactions and a large number of users it is not usual to allow each user to have complete access to each and every transaction. This requires the creation of some sort of Access Control List (ACL) which identifies who is allowed to access what. Any combination of user and transaction which is not in this list will therefore not be allowed. This ability can be supplied in a variety of ways. One way is to have a separate ACL for each user, but when you have a large number of users this could result in a lot of duplication when several people have the same capabilities. Another method would be to grant access to User Roles, then assign each user to one or more of these roles. A list of possible options can be found in A Role-Based Access Control (RBAC) system.
The current design in the RADICORE framework has task access assigned to roles, and each user can be linked with any number of roles. This information is also used to filter out those Menu Buttons and Navigation buttons to which the current does not have access so the only buttons which are visible are those for tasks which the user can actually use. All those tasks which are not accessible are not visible and therefore cannot be selected. This mechanism means that all access control is performed within the framework and not within each task. This is in contrast to earlier systems I encountered where the entire forms family was within a single component which then required internal code to check the accessibility of any sub-component before that sub-component could be executed.
Other security features are documented in The RADICORE Security Model.
In some applications, probably those which hold sensitive data, it may be a requirement to keep a log of any changes made to that data. This log, known as an Audit Trail, identifies who changed what and when, and can be implemented in several ways. The first system I encountered early on in my career required a separate table in the audit database for each table in the live database, and this audit table was populated by a database trigger. This had several problems:
I never liked this method, so when the opportunity arose for me to implement an audit logging system in my own application I came up with a totally different approach which is discussed in Creating an Audit Log with an online viewing facility. This implementation can be summarised as follows:
I have actually found this type of audit log to be quite beneficial in testing as I can run a task and immediately view all the updates it made to any database tables in order to verify that the correct updates were made.
This is where, having identified its essential components, you actually build your enterprise application. So where do you start? The approach that I took was to start at the top with the Big Picture and gradually work my way down filling in more and more levels of detail.
Although our profession now uses the name of Information Technology when I joined it in the 1970s it used the name Data Processing and the software applications that we wrote were known as Data Processing Systems. Those three words provide the most succinct description of an enterprise application, so let us start by examining those words in more detail.
What is a system? It is something which transforms input into output, as shown in Figure 7:
Figure 7 - a system
")
Software is a system as data goes in, is processed, and data comes out. The data input is usually performed by a human, the data output is usually viewed by a human, and the processing in the middle is performed by software and usually involves the use of a database as a persistent storage mechanism. The software therefor has two phases, one for input and another for output, as shown in Figure 8:
Figure 8 - a data processing system
")
In this way the software can be seen as nothing more than a mechanism to transport data between the user interface and the database. In simple applications there is one data entry form for each table in the database, but in more complex systems the data may need to be stored in or retrieved from multiple tables. There may also be complex business rules in which an event can trigger a more complex process, such as the approval of a sales order can trigger the generation of an invoice which is converted into a PDF document so that it can be emailed to the customer. The approval may also trigger the generation of a pick list which identifies which products need to be picked from inventory and assembled into a shipment.
Writing code to move data between the user interface and the database is relatively straightforward, which means that the real value in any application is the processing of the business rules. The aim of software development should therefore be to create an environment in which a programmer can devote more of his time to the tricky business rules and less of his time to the straightforward and boring aspects of the application.
As can be seen in Figure 2 each and every component in the application, with extremely limited exceptions, will have electronic forms at the front end, a database at the back end, and some software in the middle which links the two. Another way of representing this is shown in Figure 9:
Figure 9 - User Interface, Software, Database Interface
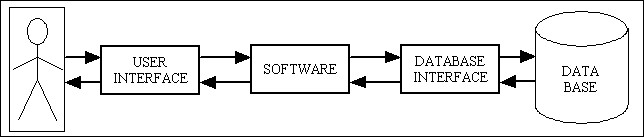
While the user interface is a collection of (mostly) HTML documents, these are not free standing and have to be generated within the software. Similarly the database interface is required in order to generate the SQL queries and send them to the database server using API calls which are specific to that particular DBMS.
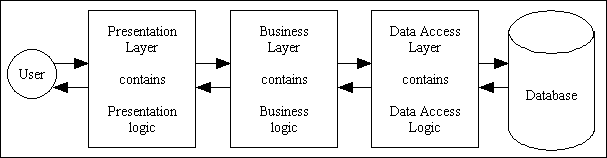
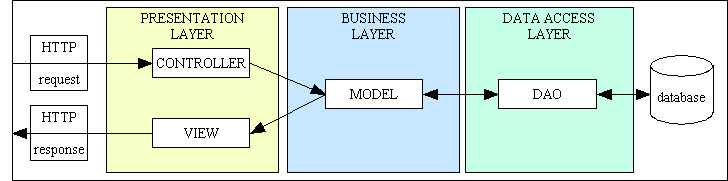
These three areas - user interface, software and database interface - correspond very nicely to the layers in the 3-Tier Architecture with its Presentation/UI layer, Business layer and Data Access layer as shown in Figure 10:
Figure 10 - the 3-Tier Hierarchy
Another popular pattern in the OO world is that of the Model-View-Controller which has the basic structure as shown in Figure 11:
Figure 11 - the Model-View-Controller design pattern
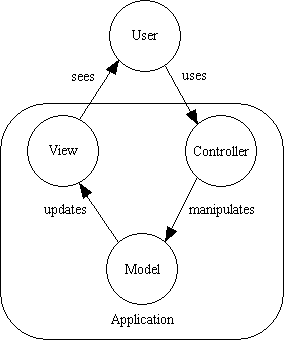
Some people regard these two as alternatives, but they can actually be combined to form the structure shown in Figure 12:
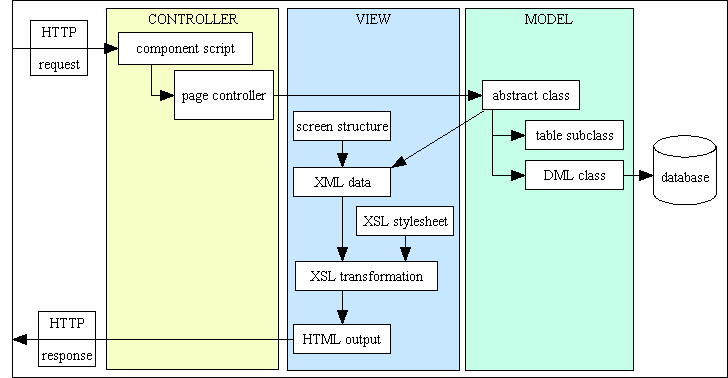
Figure 12 - 3TA and MVC combined
All I have done here is split the Presentation layer into two components, a Controller and a View. I have separate variations of the View which produce output as either HTML, PDF, CSV or XML. Note also that a Controller cannot switch between these Views - each type of View requires its own dedicated Controller. Note also that my Controllers (which are Page Controllers, not Front Controllers) are not capable of performing different actions - each Controller is hard-coded to perform a single action on an unspecified table.
I have also extracted all database access from the Model and put it into a separate Data Access Object (DAO). I have a separate DAO for each supported DBMS (MySQL, Postgresql, Oracle and SQL Server) so that I can switch from one DBMS to another simply by changing a single line in my configuration file. Some people regard this ability as overkill as organisations rarely perform such a switch, but they are missing an important point. While it is true that once an application has been built it is rare to switch that application to another DBMS, but with which DBMS is the application originally built? If you are in the business, as I am, of supplying an open source framework or a packaged application you do not want your customers to be forced to use a DBMS of your choosing. Instead you give then a choice up front, and it does not matter if they stick with that choice for the entire lifetime of that application.
Every task within the application will therefore require the use of components within each of these layers, some of which may be unique while others can be shared. It is important that each of these components should communicate with each other using standard protocols otherwise you will do nothing but make a rod for your own back.
After adding in some other components my final application structure was that as shown in Figure 13:
Figure 13 - Final application structure
There are not many applications which can have their entire structure depicted in a single diagram.
Before you can start building your enterprise application you have to start with some sort of design, so where do you start? In my several decades of experience the following steps became the standard pattern for each new application:
Note here that the Logical Design is always a precursor to the Physical Design. The Logical Design identifies what needs to be done whereas the later Physical Design identifies How it will be done. Although coding is usually reserved for the Implementation phase, it may be necessary before the Logical Design is signed off to include a Proof of Concept (POC) or a small prototype so that the client has an idea of what the final product will look like and is confident that it will achieve his objectives.
This is also the place where different people have different views on which design process to use. Some like to start with Object Oriented Design (OOD) in which they design their software components first and leave the database design till last as they consider it to be nothing more than an "implementation detail". However, when they come to design the database they should do so using the rules of Data Normalisation. If two different design methodologies are used, one for the software and one for the database, the two designs will more often than not be out of step with each other, which leads to a condition known as Object-Relational Impedance Mismatch. The usual solution to this mismatch is to build a component called an Object Relational Mapper (ORM) which sits between these two different implementations and which deals with the differences between the two structures. I do not like this idea, as I discuss further in Object Relational Mappers are EVIL, so instead of using two design methodologies which produce mismatched results I prefer to use a single proven and less ambiguous methodology and apply this single structure to both the database and the software. This removes the mismatch as well as the need for an extra component to deal with the mismatch. This is why I always design my database first, then build my application using a collection of components which do various things to various database tables.
This erroneous theory that OO design is superior to database design when writing a database application is being propagated by articles such as Doctrine ORM and DDD aggregates in which the author states the following:
But while designing, you should not let the fact that you're using a relational database get in the way.
Excuse me? Writing an application which deliberately disguises the fact that it has to communicate with a database by generating SQL queries is, to me, as nonsensical as writing a web application while deliberately disguising the fact that it has to communicate with the user by generating HTML forms. I programmed in COBOL for over 16 years where I learned that, courtesy of a Jackson Structured Programming course, best results could be obtained by creating a software structure which mirrored the database structure. I programmed in UNIFACE for over 10 years where it was impossible not to follow the database structure as all form components had to be constructed using the Application Model which was was a perfect representation of the database schema. In fact, in UNIFACE you use the application model (originally called the Conceptual Schema from the Three Schema Architecture) to generate the CREATE TABLE script (originally called the Physical Schema) which created the database using the chosen DBMS. So instead of writing code which disguises the fact that it is communicating with a database I do the complete opposite by writing code which embraces that fact. That is why I have a separate class for each database table, and each class has methods for each of the CRUD operations which are inherited from a single abstract class. The reasoning behind this different approach is discussed in the following articles:
The idea of creating a separate class for each database table is actually recommended in the principle of Information Expert (GRASP) which states the following:
Assign responsibility to the class that has the information needed to fulfill it.
I interpret "responsibility" to mean code and "information" to mean data, so because each database table is responsible for a different set of data it follows that I should have a separate class to control access to that data, and that class should also contain all the methods which can act upon that data.
This is also where a large number of OO programmers make a fundamental mistake - they take the idea of modelling the real world too seriously. When they design software in an e-commerce application which has to interact with entities called Customer, Product and Order they assume that they require operations which are relevant to those objects in the real world. They fail to realise the simple fact that their software will never interact with objects in the real world at all, only their representations in a database. As anyone who understands how databases work will tell you, objects in a database are called tables where each table has a unique name and a collection of columns, and operations never have to be defined separately for each table as they are all subject to the same global set of CRUD operations which are invoked by generating SQL queries.
Another common mistake that OO programmers make, probably because of bad information passed down to them by misguided teachers, is that OO programming requires a totally different mindset from procedural programming. I have debunked this idea in What is the difference between Procedural and OO programming? in which I state that the only difference is that one of these paradigms supports Encapsulation, Inheritance and Polymorphism while the other does not. There are more similarities than there are differences - the low-level commands are the same, and to write "good code" you need to aim for high cohesion, loose coupling and the elimination of redundancies. The low-level commands that you write to "do stuff" are basically the same with the only difference being the way in which that code is packaged. In a procedural language you organise that code into a collection of functions, subprograms or subroutines, but in OO you have classes with properties and methods, but you need to design your classes in such a way as to maximise inheritance which in turn leads to more opportunities for polymorphism. This theme is documented in Designing Reusable Classes which was published in 1988 by Ralph Johnson & Brian Foote. I discuss this further in The meaning of "abstraction".
When in 2002 I made the switch from my previous non-OO languages to PHP I wanted to find out what was so special about OOP and how to make use of its capabilities, and I started with this simple definition:
Object Oriented Programming is programming which is oriented around objects, thus taking advantage of Encapsulation, Polymorphism, and Inheritance to increase code reuse and decrease code maintenance.
Having written development frameworks in each of my two previous language, where each framework provided a significant increase in developer productivity, I sought to develop a new version of the same frameworks in PHP which provided the scope for even more reusability by utilising the additional features that OOP provided. Note that PHP is a multi-paradigm language in that it supports both a procedural and an OO style of coding, so it is possible to switch between the two in the same program. There was absolutely zero documentation at the time which said that to be a good OO programmer you had to switch to a totally different mindset, so all I did was start with my proven design methodology but organise my code into collections of classes instead of plain functions.
The only preparation which I did before starting my new framework was to see how easy it was to extract data from a database, put it into an XML document, then transform that document into HTML by using an XSL transformation. I had encountered XML and XSLT in my last UNIFACE project, but it's method of creating HTML pages was so clunky that I decided to drop that language completely and switch to one which offered better facilities. That language that I chose was PHP.
In his article How to write testable code the author identifies three distinct categories of object:
| Entities | An object whose job is to hold state and associated behavior. The state (data) can be persisted to and retrieved from a database. Examples of this might be Account, Product or User. In my framework each database table has its own Model class. |
| Services | An object which performs an operation. It encapsulates an activity but has no encapsulated state (that is, it is stateless). Examples of Services could include a parser, an authenticator, a validator or a transformer (such as transforming raw data into HTML, CSV or PDF). In my framework all Controllers, Views and DAOs are services. |
| Value objects | An immutable object whose responsibility is mainly holding state but may have some behavior. Examples of Value Objects might be Color, Temperature, Price and Size. PHP does not support value objects, so I do not use them. I have written more on the topic in Value objects are worthless. |
This is also discussed in When to inject: the distinction between newables and injectables.
The PHP language does not have value objects so I shall ignore them.
When building an application using OO techniques you should therefore concentrate on the entities with which the application is supposed to interface and which will exist in the Business/Domain layer. You then identify the properties (data) of each entity and the methods (operations) which can be performed on that data. You then create a separate class for each entity which encapsulates (creates a "capsule" or container for) both the properties and the methods. It would be advisable to avoid the temptation to create Anemic Domain Models which contain data but no processing. This goes against the whole idea of OO which is to create objects which contain both data and processing.
To find out the different types of object which I eventually created please refer to What objects do I use?
The first thing that you should recognise when developing using OOP is that at a bare minimum you must have two components:
Note that, for reasons which should be obvious, the second component cannot be a class.
As with OOP we are supposed to be modelling the real world I shall call the first component a Model. The second component controls the first component's instantiation and method activation, so I shall call this a Controller. The fact that these names correspond with similar objects in the Model-View-Controller (MVC) design pattern is sheer coincidence. Or is it?
One of the immediate advantages of deciding to have all the HTML output generated by an XSL transformation was that I could put all that processing into a single function which could then be called by any number of Controllers. It was later pointed out to me that this arrangement followed the description of the View part of the Model-View-Controller design pattern.
Before I could start building my first enterprise application with PHP I had to build my framework, or more precisely rebuild the same framework that I had built in my previous languages. Both of these frameworks used information contained in a database, so I duplicated the same structure in MySQL then began writing code to maintain the contents of these database tables. Note that at this point I had zero reusable code - no classes, no functions, no libraries - so I was effectively starting with a blank canvas.
I chose one of these database tables and began writing the components to perform each of the operations shown in the forms family in Figure 5. Although some programmers would build a single Controller to perform all of those 6 operations I had learned decades earlier of the benefits of having a separate component for each of those operations, so I built 6 separate Controllers which performed just one operation each. Each of these 6 Controllers called a different combination of methods on the same Model:
$model->getData($where) method to retrieve multiple rows from the database. The $where argument is empty at this point. This displayed up to 10 rows to a page, with options for pagination.$model->getInitialData() method to build the initial (usually empty) screen, then when the SUBMIT button was pressed it called the $model->insertRecord($_POST) method to add the contents of the $_POST array to the database.$model->getData($where) method using the primary key of the selected record and displayed that data on the screen.$model->getData($where) method using the primary key of the selected record, displayed that data on the screen, then when the SUBMIT button was pressed called the $model->updateRecord($_POST) method to update that record with whatever values were changed by the user.$model->getData($where) method using the primary key of the selected record and displayed that data on the screen. When the SUBMIT button was pressed it called the $model->deleteRecord($_POST) method to remove that record from the database.$where argument. This provided a standard mechanism for including in the LIST screen only those records which matched these values.As I have stated previously the parent LIST Controller is available on the MENU bar while its 6 children are available on the NAVIGATION bar when that parent is the current form.
You should also note the following:
SELECT ... WHERE ... statement where the WHERE clause can cater for a multitude of possibilities, so all these possibilities can be covered with a single $model->getData($where) method.$fieldarray variable which could contain any number of columns from any number of rows. This meant that I did not have to bother with separate getters and setters for each column as I could pass all the relevant data from one component to another as a single argument on a method call. This to me was a no-brainer as every $_GET or $_POST request supplied to the Presentation layer arrives in the form of an associative array, and all data passed back from the Data Access layer via mysqli_fetch is also supplied in the form of an associative array. It therefore made sense to me to preserve this entire array within the Business layer instead of unpicking it into its individual components.$model->getData($where) could return any number of rows. The idea of having a separate object for each row never entered my head. The output from any SELECT query gets put into a single array called $fieldarray, and this array can contain any number of columns from any number of rows. The facilities for processing arrays in PHP are very powerful, so this did not present any difficulties.$fieldspec which identified the column names and the data type for each column within that table. This then made it possible to write a function which compared each column's value in the $fieldarray variable with its corresponding data type in the $fieldspec array to verify that the column's value was consistent with its data type. Any errors would cause the insert/update to be aborted and a suitable error message to be displayed on the screen. Note that originally this $fieldspec array had to be hard-coded into each Model class, but later I found a way to automate this by reading the table's structure directly from the database schema.$fieldarray variable which could hold as many rows and columns of data as was necessary made it very easy to write a component which transferred the contents of that array to an XML document prior to calling an XSL transformation to produce the HTML output. The ability to iterate through an array with unknown contents using foreach construct in the language thus avoided the need for separate getters for each individual column.At the end of this exercise I had a single Model and six Controllers which between them handled all the basic operations which could be performed on a specific database table. The next step was to create a similar set of Model and Controllers for a different database table.
I initially created this second set of components by creating copies of the first set with different names. I then went through and manually changed all the table references from 'table#1' to 'table#2'. The result was a set of components which operated on different tables but which had a huge amount of duplicated code. Although I had used encapsulation to create my Model classes my next step was to see how I could reduce this level of duplication using these new-fangled ideas called inheritance and polymorphism.
With inheritance you have a set of methods in a superclass which you can share with a subclass by using the keyword extends. I therefore created a superclass which I initially called a generic table class as the keyword abstract was not supported in PHP4. This is what it contained initially:
File: std.table.class.inc <?php class Default_Table { var $dbname = ''; // database name var $tablename = ''; // table name var $errors = array(); // contains any error messages var $messages = array(); // contains any non-error messages var $fieldarray = array(); // contains data in rows and columns var $fieldspec = array(); // contains field specifications var $pageno = 1; // page number for pagination var $rows_per_page = 0; // page size for LIST screens function getData ($where=null) { $fieldarray = $this->_dml_getData($where); return $fieldarray; } // getData function insertRecord ($fieldarray) { $this->errors = array(); $fieldarray = $this->_validateInsert($fieldarray, $this->fieldspec); if (!empty($this->errors) { return $fieldarray; } // if $fieldarray = $this->_dml_insertRecord($fieldarray); return $fieldarray; } // insertRecord function updateRecord ($fieldarray) { $this->errors = array(); $fieldarray = $this->_validateUpdate($fieldarray, $this->fieldspec); if (!empty($this->errors) { return $fieldarray; } // if $fieldarray = $this->_dml_updateRecord($fieldarray); return $fieldarray; } // updateRecord function deleteRecord ($fieldarray) { $this->errors = array(); $fieldarray = $this->_validateDelete($fieldarray, $this->fieldspec); if (!empty($this->errors) { return $fieldarray; } // if $fieldarray = $this->_dml_deleteRecord($fieldarray); return $fieldarray; } // deleteRecord function setPageNo ($pageno) { if (empty($pageno)) { $this->pageno = 1; } else { $this->pageno = abs((int)$pageno); } // if } // setPageNo function setRowsPerPage ($rows_per_page) { $this->rows_per_page = abs((int)$rows_per_page); } // setRowsPerPage } // Default_Table ?>
Notice the following:
$model->errors array to find out if that call was successful or not.While this arrangement provided all the standard and common processing I recognised that there would be some circumstances when I wanted to perform some additional processing. I wanted to provide the ability to interrupt the standard flow of control with pieces of ad-hoc code, and having read somewhere about pre- and post-conditions I decided to create a pair of "_cm_pre_XXX" and "_cm_post_XXX" methods around each "_dml_XXX" method, as in the following example:
function insertRecord ($fieldarray)
{
$this->errors = array();
$fieldarray = $this->_validateInsert($fieldarray, $this->fieldspec);
if (!empty($this->errors) {
return $fieldarray;
} // if
$fieldarray = $this->_cm_pre_insertRecord($fieldarray);
if (!empty($this->errors) {
return $fieldarray;
} // if
$fieldarray = $this->_dml_insertRecord($fieldarray);
$fieldarray = $this->_cm_post_insertRecord($fieldarray);
return $fieldarray;
} // insertRecord
Note that I do not perform any error checking after calling the "_dml_XXX" method because any errors with the execution of any SQL query will cause the program to immediately abort, which would cause details of the error to be sent to the system administrator. There would be no point in returning to the user with an error message as there would be nothing the user could do to correct it.
Each of these methods with a "_cm_" prefix, which I call Customisable Methods, is defined within the generic class but without any implementation so that when called it does nothing by default. In order to use this functionality it is simply a matter of copying the empty method from the generic class to the table class, then inserting code into that copy. At run-time the copy in the table class will be executed instead of the empty original in the generic class. This is called Method Overriding and is a standard technique in OOP. Note that these are NOT defined as abstract methods so they do not need to be defined in the table class unless an implementation is actually required. Note also that it is only those methods with a "_cm_" prefix which can be overridden in this way.
Each of the two Model classes had contents which were similar to the generic class but with the addition of a class constructor similar to the following:
File: mnu_task.class.inc <?php class mnu_task { function mnu_task () { $this->dbname = 'menu'; $this->tablename = 'mnu_task'; $this->fieldspec['column1'] = 'string'; $this->fieldspec['column2'] = 'string'; $this->fieldspec['column3'] = 'string'; .... } // mnu_task } // mnu_task ?>
Notice that the constructor identifies the characteristics of a particular table, that which separates one table from another.
There then followed a process whereby I removed code from each Model class to an equivalent place in the generic class so that the same code could be inherited instead of duplicated. I eventually reached the point where everything except the class constructor had been moved. This left a very large superclass and very small subclasses. This to me was a shining example of how to maximise the power of inheritance as I now had a large amount of code which was defined in a single superclass which could be shared by any number of table classes. As my enterprise application now has over 400 tables you have to agree that that is a lot of inheritance.
Next I turned my attention to the Controllers. Each of them originally contained code similar to the following:
File: mnu_task(list).php <?php require('classes/mnu_task.class.inc'); $dbobject = new mnu_task; $fieldarray = $dbobject->getData(); $errors = $dbobject->errors; $messages = $dbobject->messages; $xsl_file = 'xsl/mnu_task.list.xsl'; buildXML($dbobject, $xsl_file, $errors, $messages); ?>
I quickly discovered that I could use variables instead of strings to instantiate the object, so I moved the creation of these strings to a separate script which then passed control to a Controller. This then produced something like the following:
File: mnu_task(list).php (called a component script) <?php $table_id = 'mnu_task'; $xsl_file = 'xsl/mnu_task.list.xsl'; require('std.list.inc'); ?>and ...
File: std.list.inc (called a controller script) <?php require("classes/$table_id.class.inc"); $dbobject = new $table_id; $fieldarray = $dbobject->getData(); $errors = $dbobject->errors; $messages = $dbobject->messages; buildXML($dbobject, $xsl_file, $errors, $messages); ?>
Each and every user transaction in the application therefore requires its very own component script which immediately identifies those parts of the application that it actually uses. Each of these scripts can be directly referenced in a URL, which then removes the need for a Front Controller. Note that the same table class can be referenced by more than one component script as can any of the Controllers.
As you can see the Controller now calls a fixed series of methods on a database table object without knowing the identity of that table. All the methods which it calls are defined within the generic table class, and as all the database table classes inherit from the same generic class it means that any Controller can be used with any table class. This to me is a shining example of polymorphism in action. My enterprise application currently has 40 Controllers and 450 database tables, so that produces 40 x 450 = 18,000 (yes, EIGHTEEN THOUSAND) opportunities for polymorphism. The number of Controllers has increased from 6 to 40 (refer to Transaction Patterns for details) as I have encountered more complicated user transactions which require different screen structures and different processing. My enterprise application currently has 4,000+ user transactions which all use one of those Controllers.
You should also notice that the Controller does not mention any column names when calling any of the Model's methods. This is a direct product of using a single $fieldarray variable to hold all the data. This was initially prompted by the fact that when the user presses the SUBMIT button in an HTML form within a PHP application the entire contents of that form is passed in as the $_POST array. This is an associative array of 'name=value' pairs, and the PHP language makes it very easy to iterate through the contents of this array using the foreach command, as in the following:
foreach ($fieldarray as $fieldname => $fieldvalue) { echo 'name=' .$fieldname .', value=' .$fieldvalue .'<br>'; } // foreach
When this array is fed into the View component it may contain more than one row, which means that $fieldarray then becomes and indexed array of associative arrays, and can be processed with code similar to the following:
foreach ($rowdata as $rownum => $fieldarray) { foreach ($fieldarray as $fieldname => $fieldvalue) { echo 'row=' .$rownum .', name=' .$fieldname .', value=' .$fieldvalue .'<br>'; } // foreach } // foreach
Imagine my surprise when I later came across articles on the internet which said that using a single $fieldarray argument was considered wrong as the "proper" OO way was to use a separate setter and getter for each column. This to me is a glaring example of tight coupling and is the total opposite of loose coupling which is supposed to be better.
In my original implementation I had separate XSL stylesheets for each database table as each one had a hard-coded list of column names plus the relevant HTML tags to provide the desired control (text box, radio button, checkbox, dropdown list, et cetera). I quickly discovered that I could put the code for each of these controls into a template in a separate file which I could then call from any number of stylesheets as required. That cut out a lot of duplicated code, but I wanted to take this even further. After some experimenting I discovered that I could actually put into the XML document enough information for the XSL stylesheet to build the screen with each column in the correct place with the correct HTML control. Here is an example:
<structure>
<main id="person">
<columns>
<column width="150"/>
<column width="*"/>
</columns>
<row>
<cell label="Id"/>
<cell field="user_id"/>
</row>
<row>
<cell label="Name"/>
<cell field="user_name"/>
</row>
</structure>
This tells the XSL stylesheet to produce an HTML table in the zone called "main" as follows:
This information is provided in a separate PHP script known as a screen structure file which has a format similar to the following:
<?php $structure['xsl_file'] = 'std.detail1.xsl'; $structure['tables']['main'] = 'person'; $structure['main']['columns'][] = array('width' => 150); $structure['main']['columns'][] = array('width' => '*'); $structure['main']['fields'][] = array('person_id' => 'ID'); $structure['main']['fields'][] = array('first_name' => 'First Name'); $structure['main']['fields'][] = array('last_name' => 'Last Name'); $structure['main']['fields'][] = array('initials' => 'Initials'); $structure['main']['fields'][] = array('nat_ins_no' => 'Nat. Ins. No.'); $structure['main']['fields'][] = array('pers_type_id' => 'Person Type'); $structure['main']['fields'][] = array('star_sign' => 'Star Sign'); $structure['main']['fields'][] = array('email_addr' => 'E-mail'); $structure['main']['fields'][] = array('value1' => 'Value 1'); $structure['main']['fields'][] = array('value2' => 'Value 2'); $structure['main']['fields'][] = array('start_date' => 'Start Date'); $structure['main']['fields'][] = array('end_date' => 'End Date'); $structure['main']['fields'][] = array('selected' => 'Selected'); ?>
The contents of this file is then inserted into the XML document along with the contents the the Model's $fieldarray plus various data provided by the framework, such as the menu bar, screen title, navigation bar and action bar,
As an indication of the level of reusability I have managed to achieve from my efforts, my enterprise application has over 2,700 HTML forms which are built from just 12 (yes, TWELVE) stylesheets.
For a full description of how my reusable XSL stylesheets work please read Reusable XSL Stylesheets and Templates.
After a short while of manually typing almost the same code for each and every new table class I decided to try and automate it so that I could generate the class file by selecting a table and pressing a button. UNIFACE, my previous language, did not have class files, instead it had service components which were built by accessing the Application Model, an internal database which described every table, column and relationship in the application. This had the facility to export each table's structure in the form of DDL statements from which the physical database could be built. I decided to build a similar mechanism, but with a few alterations:
My version of the Application Model is called a Data Dictionary. In between the import and export process I decided to allow an edit phase so that the data could be enhanced in order to make available additional information which was not available in the information schema but which could be useful to the application, such as forcing a string value to be converted to either upper or lower case.
When a table is first exported it will produce a class file called <table>.class.inc which is based on the following template:
<?php require_once 'std.table.class.inc'; class #tablename# extends Default_Table { // **************************************************************************** // class constructor // **************************************************************************** function __construct () { // save directory name of current script $this->dirname = dirname(__file__); $this->dbname = '#dbname#'; $this->tablename = '#tablename#'; // call this method to get original field specifications // (note that they may be modified at runtime) $this->fieldspec = $this->getFieldSpec_original(); } // __construct // **************************************************************************** } // end class // **************************************************************************** ?>
You will notice here that instead of containing code to provide the contents of the $fieldspec array it actually calls a method which loads in that data from a separate <table>.class.inc file which makes that data available in a series of class variables. Additional data concerning that table is provided in variables such as $primary_key, $unique_keys, $child_relations, $parent_relations, $audit_logging and $default_orderby. This provides the ability to regenerate the contents of the <table>.dict.inc at any time without overwriting the contents of an existing <table>.class.inc file which may have been modified to include some customisable methods. During the life of a database application it is quite common to modify the structure of various tables now and then, so I made this process as easy as possible by allowing the import process to be run after any change to the database schema so that any changes could be recorded in the Data Dictionary. By following this with an export which overwrites the <table>.dict.inc file but does not touch the <table>.class.inc it is possible to ensure that the application's knowledge of the physical database structure is always in sync.
Being able to generate the <table>.class.inc and <table>.dict.inc files at the touch of a button certainly saved a lot of manual effort, I then turned my attention to the generation of user transactions which had a lot of manual steps:
Steps such as these which follow a set pattern are always ripe for automation, so I then modified my Data Dictionary to include the ability to perform all these steps automatically at the touch of a button. This is actually a 3-step process:
After this you can immediately select the newly-generated tasks on a menu and run them without having to write a single line of code - no PHP, no SQL, no HTML. The manual procedure used to take me 1 hour, but automation reduced this to 5 minutes. How's that for Rapid Application Development? That is why there is a "RAD" in RADICORE.
You may have noticed in my original generic table class that it included methods with a "_dml_" prefix which accessed the database directly. This situation is invalid in the 3-Tier Architecture which requires that all database access be handled in a separate Data Access Object. Fortunately it was a relatively easy process to copy all these methods to a separate MySQL class, then update the original methods to use this MySQL class to access the database instead of doing it directly. This was put to the test when MySQL version 4.1 was released as it used a different set of "improved" API calls. I then created a second MySQLi class which contained these API calls, then changed the code in the generic table class which identified which class was needed to be instantiated into an object so that it could load the right one. When other DBMS vendors made it possible to download and install versions of their software for free it was then possible for me to write and test new classes for each DBMS. I can now switch my application so that it uses one of four DBMS engines - MySQL, Postgresql, Oracle or SQL Server - simply by changing a single line in a configuration file.
This follows on from What objects should I create? My framework contains a mixture of entities and services as follows:
Note here that all application/domain knowledge is confined to the Models (the Business layer). These may also be called Domain Objects as they exist in the Domain/Business layer. There is absolutely no application knowledge in any of the services which are built into the framework. This means that the services (Controllers, Views and DAOs) are application-agnostic while the Models are framework-agnostic.
Novice OO programmers are taught that Design Patterns are crucial in order to write "good" code. They are told that these patterns were designed by experts, so in order to produce code on a par with these experts they should litter their code with as many patterns as possible. Unfortunately this often leads to a condition known as Cargo Cult Programming where emulating the steps that experts follow does not produce a result that is anywhere near as good. Instead of making a list of patterns which I expect to appear in my code I prefer to follow the advice of Erich Gamma, one of the authors of the Gang of Four book who, in this interview, said the following:
Do not start immediately throwing patterns into a design, but use them as you go and understand more of the problem. Because of this I really like to use patterns after the fact, refactoring to patterns.
Before I started redeveloping my framework in PHP the only pattern that I had in mind was the 3-Tier Architecture. I had encountered this while using UNIFACE, and I could immediately see its benefits.
It was only after I had refactored my code that a colleague pointed out that because I had created a separate component for the View I had actually created an implementation of the Model-View-Controller design pattern. This is a case where I used a design pattern by accident and not by design.
Among other patterns which I found later in my code were the following:
This is described as follows:
Intent
Define the skeleton of an algorithm in an operation, deferring some steps to subclasses. Template Method lets subclasses redefine certain steps of an algorithm without changing the algorithm's structure.Applicability
The Template Method pattern should be used
- to implement the invariant parts of an algorithm once and leave it up to subclasses to implement the behaviour that can vary.
- when common behaviour among the subclasses should be factored and localized in a common class to avoid code duplication.
- to control subclass extensions. You can define a template method that calls "hook" operations at specific points, thereby permitting extensions only at these points.
Consequences
Template methods are a fundamental technique for code reuse. They are particularly important in class libraries because they are the means for factoring out common behaviour in library classes.Template methods lead to an inverted control structure that's sometimes referred to as "the Hollywood Principle", that is "Don't call us, we'll call you". This refers to how a parent class calls the operations of a subclass and not the other way around.
The Template Methods call the following kinds of operations:
- concrete operations (either on the ConcreteClass or on client classes).
- concrete AbstractClass operations (i.e., operations that are generally useful to subclasses).
- primitive operations (i.e., abstract operations).
- hook operations, which provide default behaviour that subclasses can extend if necessary. A hook operation often does nothing by default.
The provision of such "hooks" is described further in How Radicore's Hook System Works.
Notice also that it refers to concrete (non-abstract) methods in an AbstractClass which are generally useful to subclasses. This means that my use of a single generic/abstract class which provides all the possible operations which may be performed on an unspecified database table, then having this inherited by every concrete table class which changes unspecified to a specific database table, is not as crazy as some people would have you believe.
A Table Module organizes domain logic with one class per table in the database, and a single instance of a class contains the various procedures that will act on the data. The primary distinction with Domain Model is that, if you have many orders, a Domain Model will have one order object per order while a Table Module will have one object to handle all orders.
Class Table Inheritance represents an inheritance hierarchy of classes with one table for each class.
Concrete Table Inheritance represents an inheritance hierarchy of classes with one table per concrete class in the hierarchy.
A view that processes domain data element by element and transforms it into HTML.
...
Using Transform View means thinking of this as a transformation where you have the model's data as input and its HTML as output.
This description is a perfect fit for my usage of XSL Transformations to produce all HTML output. The View component extracts the raw (unformatted) data from the Model, inserts that data into an XML document, then transforms it using a nominated XSL stylesheet.
The only pattern that I had ever read about before adding it my code was the Singleton, but due to my heretical nature I came up with a unique implementation.
I have a low opinion of design patterns in general simply because they do not provide reusable code. Every time you wish to implement one of these patterns you have to write a fresh piece of code. It is not possible to say "Take this entity, that design pattern, now generate the necessary code to marry the two". I have obtained far more reusability by creating my own library of Transaction Patterns which actually provide reusable code for each pattern. It is now possible for me to say "Take this entity, that transaction pattern, now generate the task which allows me to perform that pattern on that entity" all without having to write a single line of code.
As you develop more and more components within an application you may notice yourself writing similar or even identical blocks of code more than once, sometimes many times. When requiring another instance of that code the novice developer will often use the most primitive form of code reuse which is copy-and-paste. This is quickest in the short term, but in the long term it causes problems because if you ever have to change that code, either to fix a bug or add an enhancement, you then have multiple copies spread all over your code base which is a maintenance nightmare. A better method would be to put that code into a central library, then when you wanted to use that code you would simply call the library function. The advantage of this method is that should you ever wish to change the code within that function you only ever have to change it in one place, the central library, and all users of that library will always get the latest version. The disadvantage of this method is that you have to have a central library which can be accessed by all components, you need the ability to add new functions to this library, and you need the ability to change the original code into a library function with the correct arguments to deal with any differences with the calling components. This last operation is not something that can usually be done by a novice, and as it takes longer than the copy-and-paste method it is something that they tend to avoid because of time constraints.
The next step up from a library is a framework, but what exactly is the difference between the two? Basically it boils down to who calls what:
A framework also provides you with the following abilities:
A framework therefore provides more reusable components than a simple library, but takes correspondingly more effort to develop.
This is described in more detail in What is a Framework?
Having been involved in the development of enterprise applications for more than 2 decades before I switched to PHP in 2002 it should be obvious that I am not a novice who does not know what he is talking about. I also designed and built development frameworks for those applications in 2 of those previous programming languages which my employer praised for boosting the productivity of the entire development team. I switched to PHP as I wanted to develop such applications in a language that was purpose-built for web development and did not have it as a bolt-on extension. PHP was also the first language I used which had OO capabilities, so I gauged the success of my implementation with how well it fulfilled the objectives that OO was supposed to deliver according to all those snake oil salesmen. My working description of OOP, and its supposed benefits, was as follows:
Object Oriented Programming is programming which is oriented around objects, thus taking advantage of Encapsulation, Polymorphism, and Inheritance to increase code reuse and decrease code maintenance.
What's so special about code reuse? The more reusable code you have then the less code you have to write, test, debug and maintain. This means that, in theory, you should be able to develop applications quicker, and therefore cheaper, than your rivals. The success of my implementation can be judged by the amount of code which I don't have to write such as the following:
An enterprise application is primarily concerned with moving data into and out of a relational database, and that data is distributed across hundreds of database tables. The ability to work easily with database tables should therefore be considered as being of paramount importance. This is why I have a separate concrete class for each table in the database which inherits vast amounts of common code from an abstract table class. Using my framework I can take the definition of a table in the database then generate a working family of forms in 5 minutes without having to write any code - no PHP, no SQL, no HTML. While these forms are basic in their operation, it is easy to add flesh to the bones by inserting additional code into the hook methods which are defined in the framework's abstract table class.
Another great advantage I have found by having a set of 40 pre-written page controllers which communicate with all my concrete table classes through the methods which are defined in a single abstract table class, and having all HTML output generated from just 12 XSL stylesheets, is that I can easily make changes to this standard code and have those changes automatically inherited by all the relevant tasks. This has allowed me to make sweeping changes to large numbers of components without having to change every one of those components.
The following articles describe aspects of my framework:
The following articles express my heretical views on the topic of OOP:
These are reasons why I consider some ideas on how to do OOP "properly" to be complete rubbish:
Here are my views on changes to the PHP language and Backwards Compatibility:
The following are responses to criticisms of my methods:
Here are some miscellaneous articles: