17th June 2005
Amended 1st November 2022
As of 10th April 2006 the software discussed in this article can be downloaded from www.radicore.org
What is a Data Dictionary? In some languages it may go by another name, such as Catalog, Repository or Application Model. The Data Dictionary does not contain any application data, it contains information which describes what data the application requires and how it is structured. This information may include table names and characteristics, field names and characteristics, relationship information, et cetera. It is therefore data-about-data, or metadata.
Many of the modern RDBMS products have facilities for holding and viewing meta-data (also known as a dictionary, catalog or information schema), so why not use that instead of going to the trouble of re-inventing the wheel? Simply because the RDBMS dictionary is designed for use by the RDBMS and does not have enough information to service other parts of the application. If you consider that an application is divided into 3 Tiers, then the RDBMS dictionary/catalog is limited to the data access layer. It cannot provide information for use in the business layer nor the presentation layer. The purpose of this particular data dictionary is to fill those gaps.
To utilise this data dictionary there are the following distinct stages:
Note that if a table's structure is amended after these two files have been created then the structure can simply be re-imported and re-exported. This will only cause the <tablename>.dict.inc file to be overwritten - the <tablename>.class.inc file will not be touched as there are no properties or methods for individual table columns.
Note that the only way to keep the dictionary and the database synchronised is to make changes within the database (using whatever administration tool is available) then import the modified details into the dictionary. It is not possible to make modifications within the dictionary then export them to the database.
The Entity-Relationship (E-R) Diagram for my dictionary database is as shown in figure 1:
Figure 1 - E-R Diagram
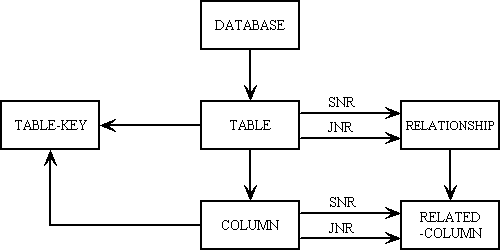
| DATABASE | This identifies all the different databases which are available in the application. |
| TABLE | This identifies all the tables that exist within each database. |
| COLUMN | This identifies the columns that exist within each table. |
| TABLE-KEY | This identifies all the keys (primary, candidate and non-unique) that have been defined for each table. |
| RELATIONSHIP | This identifies where two tables are joined in a one-to-many (parent-to-child, senior-to-junior) relationship. This data is defined manually, and not assumed from any foreign key constraints. |
| RELATED-COLUMN | For each relationship this identifies which field (column) in the primary key of the parent table is related to which foreign key field in the child table. This data is defined manually. |
The structure of this table is as follows:
CREATE TABLE `dict_database` ( `database_id` varchar(64) NOT NULL default '', `database_name` varchar(80) NOT NULL default '', `database_desc` text, `subsys_id` varchar(8) NOT NULL default '', `created_date` datetime NOT NULL default '2000-01-01 00:00:00', `created_user` varchar(16) default NULL, `revised_date` datetime default NULL, `revised_user` varchar(16) default NULL, PRIMARY KEY (`database_id`) ) TYPE=MyISAM;
| Field | Type | Description |
|---|---|---|
| database_id | STRING | The database identity. |
| database_name | STRING | A user-defined name for the database. |
| database_desc | TEXT | A user-defined description for the database. |
| subsys_id | STRING | The identity of a SUBSYSTEM within the MENU database. This provides the name of the directory in which the export files will be written. |
| The following fields are set automatically by the system: | ||
| created_date | DATE+TIME | The date and time on which this record was created. |
| created_user | STRING | The identity of the user who created this record. |
| revised_date | DATE+TIME | The date and time on which this record was last changed. |
| revised_user | STRING | The identity of the user who last changed this record. |
The structure of this table is as follows:
CREATE TABLE `dict_table` ( `database_id` varchar(64) NOT NULL default '', `table_id` varchar(64) NOT NULL default '', `table_name` varchar(80) NOT NULL default '', `table_desc` text, `audit_logging` char(1) NOT NULL default 'Y', `default_orderby` varchar(64) default NULL, `alt_language_table` varchar(64) default NULL, `alt_language_cols` text, `nameof_start_date` varchar(40) default NULL, `nameof_end_date` varchar(40) default NULL, `created_date` datetime NOT NULL default '2000-01-01 00:00:00', `created_user` varchar(16) default NULL, `revised_date` datetime default NULL, `revised_user` varchar(16) default NULL, PRIMARY KEY (`database_id`,`table_id`) ) TYPE=MyISAM;
| Field | Type | Description |
|---|---|---|
| database_id | STRING | The database identity. Links to an entry on the DICT_DATABASE table. |
| table_id | STRING | The table identity. |
| table_name | STRING | A user-defined name for the table. |
| table_desc | TEXT | A user-defined description for the table. |
| audit_logging | BOOLEAN | A YES/NO switch which identifies if updates to this table should be written to the Audit Log. |
| default_orderby | STRING | Optional. The contents of this string will be used as the ORDER BY clause on an sql SELECT statement in a LIST screen if no other sort sequence is specified. |
| alt_language_table | STRING | Optional. Identifies the table which contains text in alternative languages for certain columns on this table. Please refer to Internationalisation and the Radicore Development Infrastructure (Part 2) for more details. |
| alt_language_cols | STRING | Optional. Identifies the columns which have translated text on alt_language_table. |
| nameof_start_date | STRING | Optional. Identifies the column which is an alias for start_date. |
| nameof_end_date | STRING | Optional. Identifies the column which is an alias for end_date. |
| The following fields are set automatically by the system: | ||
| created_date | DATE+TIME | The date and time on which this record was created. |
| created_user | STRING | The identity of the user who created this record. |
| revised_date | DATE+TIME | The date and time on which this record was last changed. |
| revised_user | STRING | The identity of the user who last changed this record. |
NOTE: the nameof_extra_names/values columns are only relevant if you have developed a software package and users of this package require data elements which are not provided in the standard package.
The structure of this table is as follows:
CREATE TABLE `dict_column` ( `database_id` varchar(64) NOT NULL default '', `table_id` varchar(64) NOT NULL default '', `column_id` varchar(64) NOT NULL default '', `column_seq` smallint(6) unsigned NOT NULL default '0', `column_name` varchar(80) NOT NULL default '', `column_desc` text, `col_type` varchar(20) NOT NULL default '', `col_type_native` varchar(32) NOT NULL default '', `col_array_type` varchar(20) NOT NULL default '', `col_values` text, `user_size` int(11) unsigned NOT NULL default '0', `col_maxsize` int(11) unsigned NOT NULL default '0', `col_null` char(3) NOT NULL default 'YES', `is_required` char(1) NOT NULL default 'N', `col_key` char(3) default NULL, `col_default` varchar(40) default NULL, `col_auto_increment` char(1) NOT NULL default 'N', `col_unsigned` char(1) NOT NULL default 'N', `col_zerofill_bwz` char(3) default NULL, `col_precision` tinyint(3) unsigned default NULL, `col_scale` tinyint(3) unsigned default NULL, `col_minvalue` double default NULL, `col_maxvalue` double default NULL, `user_minvalue` double default NULL, `user_maxvalue` double default NULL, `noedit_nodisplay` char(3) default NULL, `nosearch` char(3) default NULL, `noaudit` char(3) default NULL, `upper_lowercase` varchar(5) default NULL, `is_password` char(1) NOT NULL default 'N', `auto_insert` char(1) NOT NULL default 'N', `auto_update` char(1) NOT NULL default 'N', `infinityisnull` char(1) NOT NULL default 'N', `subtype` varchar(10) default NULL, `image_width` smallint(6) unsigned default NULL, `image_height` smallint(5) unsigned default NULL, `is_boolean` char(1) NOT NULL default 'N', `boolean_true` varchar(4) default NULL, `boolean_false` varchar(4) default NULL, `control` varchar(10) default NULL, `optionlist` varchar(64) default NULL, `checkbox_label` varchar(64) default NULL, `task_id` varchar(64) default NULL, `foreign_field` varchar(64) default NULL, `align_hv` char(1) default NULL, `align_lr` char(1) default NULL, `multi_cols` tinyint(3) unsigned default NULL, `multi_rows` tinyint(3) unsigned default NULL, `custom_validation` varchar(255) default NULL, `created_date` datetime NOT NULL default '2000-01-01 00:00:00', `created_user` varchar(16) default NULL, `revised_date` datetime default NULL, `revised_user` varchar(16) default NULL, PRIMARY KEY (`database_id`,`table_id`,`column_id`) ) TYPE=MyISAM;
| Field | Type | Description |
|---|---|---|
| database_id | STRING | The database identity. Links to an entry on the DICT_TABLE table. |
| table_id | STRING | The table identity. Links to an entry on the DICT_TABLE table. |
| column_id | STRING | The column identity. |
| column_seq | NUMERIC | The sequence number of this column within the table's definition. |
| column_name | STRING | A user-defined name for the column. If this is set to 'DEPRECATED' the column will be excluded from the <tablename>.dict.inc file which is created in the Export Files process. |
| column_desc | TEXT | A user-defined description for the column. |
| col_type | STRING | The column type as shown to the user and as used by the application. In some cases COL_TYPE_NATIVE may identify a collection of possible data types, such as "CHAR,BOOLEAN", "TINYINT,BOOLEAN" or "DATE,TIME,DATETIME", in which case the user must choose the one which is desired from a dropdown list. |
| col_type_native | STRING | The column type as defined in the database. In some cases this may contain a collection of possible choices where a data type in the database may actually be used as a different data type in the application. This situation exists, for example, where the database does not support the BOOLEAN data type, in which case a CHAR(1) or TINYINT(1) is used instead. By defining such a column as BOOLEAN in the dictionary it can be treated as BOOLEAN by the application.
This also applies in the Oracle database where the single DATE data type covers the DATE, TIME and DATETIME types which exist in other databases. As it could be inconvenient to always treat such a field as DATETIME when in fact it should be DATE only or TIME only it is presented to the user as "DATE,TIME,DATETIME" so that a specific choice can be made. |
| col_array_type | STRING | By default each datatype holds a single value, but with the PostgreSQL database it is possible to have a datatype which holds an array of values. In this case COL_TYPE is set to "ARRAY" and COL_ARRAY_TYPE is set to the underlying datatype such as VARCHAR, NUMBER, etc. |
| col_values | TEXT | This is the array of field values for MySQL fields of type 'ENUM' or 'SET'. |
| user_size | NUMERIC | The column size as defined by the user. It starts off the same as COL_MAXSIZE, but may be reduced. |
| col_maxsize | NUMERIC | The column size as defined in the database. |
| col_null | STRING | Identifies if the column value is allowed to be NULL or not. Possible values are:
|
| is_required | BOOLEAN | Indicates if the column value is required or not. This is initially set using the value in COL_NULL. Possible values are:
|
| col_key | STRING | Indicates if this column is part of a key or index. Possible values are:
|
| col_default | STRING | The default value for this column as defined within the database. If IS_REQUIRED is TRUE and no value is supplied on an INSERT, this default value will be used. |
| col_auto_increment | BOOLEAN | Indicates if this column is set to 'auto_increment' within the database. Possible values are:
|
| col_unsigned | BOOLEAN | For numeric columns this turns off the ability to store values with a plus or minus sign (+/-). Only positive values can be stored. For MySQL this allows the maximum value for be doubled as the sign bit can be used as part of the value. |
| col_zerofill_bwz | STRING | Optional. Available for numeric/decimal fields only. Possible values are:
|
| col_precision | NUMERIC | For numeric values this is the number of significant decimal digits. For example, the value 999.99 has a precision of 5. |
| col_scale | NUMERIC | For numeric values this is the number of digits that can be stored following the decimal point. For example, the value 999.99 has a scale of 2. |
| col_minvalue | NUMERIC | For numeric fields this is the minimum value allowed by the database. |
| col_maxvalue | NUMERIC | For numeric fields this is the maximum value allowed by the database. |
| user_minvalue | NUMERIC | This starts off with the same value as COL_MINVALUE, but can be customised by the user. |
| user_maxvalue | NUMERIC | This starts off with the same value as COL_MAXVALUE, but can be customised by the user. |
| noedit_nodisplay | STRING | This is used by the presentation layer only. Possible values are:
|
| nosearch | STRING | This is used by the presentation layer only. Possible values are: |
| noaudit | STRING | This is used by the data access layer only. Possible values are: |
| upper_lowercase | STRING | For string fields this forces all input to be shifted to upper or lower case before being written to the database. |
| is_password | BOOLEAN | This is used by the presentation layer only. As characters are input they are masked, typically by a series of asterisks, to protect sensitive information from onlookers. However, they are still transmitted to the server in clear text. |
| auto_insert | BOOLEAN | This is only used when new records are inserted. Possible values are:
|
| auto_update | BOOLEAN | This is only used when existing records are updated. Possible values are:
|
| infinityisnull | BOOLEAN | This is valid for columns of type DATE only. It means that a blank date on the screen will be held in the database as '9999-12-31' instead of '0000-00-00'. See Dealing with null End Dates for a detailed explanation. |
| subtype | STRING | This option is available for string fields only. Possible values are:
|
| custom_validation | STRING | This option is available for any field. It identifies the validation method to be used for this field. The format is 'file/class/method' where:
|
| image_width | NUMERIC | Only valid if CONTROL='IMAGE' or SUBTYPE='IMAGE' or 'VIDEO'. Identifies the width of the image in pixels. |
| image_height | NUMERIC | Only valid if CONTROL='IMAGE' or SUBTYPE='IMAGE' or 'VIDEO. Identifies the height of the image in pixels. |
| is_boolean | BOOLEAN | The DBMS may not support a column type of BOOLEAN, in which case a 1-character field may be used as a substitute. This column may be set to TRUE to force the application to treat such a field as BOOLEAN so that its values can be limited to either BOOLEAN_TRUE or BOOLEAN_FALSE. |
| boolean_true | STRING | Only valid if IS_BOOLEAN='TRUE'. Identifies how the value 'TRUE' is stored, typically something like '1' or 'T' or 'Y'. |
| boolean_false | STRING | Only valid if IS_BOOLEAN='TRUE'. Identifies how the value 'FALSE' is stored, typically something like '0' or 'F' or 'N'. |
| control | STRING | This identifies the HTML control to be used when the field is built into a screen (and is amendable). Possible values are: |
| optionlist | STRING | This is valid for dropdown lists and radio groups only. It is the name the list of items that will be used to populate that HTML control. This list should be constructed within the table class and written out to the XML file. |
| checkbox_label | STRING | This is valid for checkboxes only. It is for an additional piece of text which may appear either to the left or right of the control depending on ALIGN_LR. |
| task_id | STRING | Optional. If the CONTROL type is 'File Picker' or 'Popup' this is the name of the Task that will be activated to provide the picklist of available options. |
| foreign_field | STRING | Optional. If the CONTROL type is 'Popup' this is name of a field on the foreign table that will be merged with the contents of the current table before being output to the XML file. This will allow the key value, which may be meaningless to the user, to be replaced with a more descriptive value. Note that the value in the foreign field can only be displayed if it is available in $fieldarray. This can be done either by including that field in the SQL SELECT query by following the instructions in Using Parent Relations to construct sql JOINs or by using custom code to insert the value manually after the SELECT query has been executed. |
| align_hv | STRING | Optional. If the CONTROL type is 'Radio Group' this identifies how the list of options should be aligned. Possible values are:
This can be used to produce effects such as: 3.png)
|
| align_lr | STRING | Optional. If the CONTROL type is 'Radio Group' or 'Checkbox' this identifies whether the text should be to the left or the right of the control. For checkboxes this only applies if an additional checkbox label has been defined. Possible values are:
This can be used to produce effects such as: |
| multi_cols | NUMERIC | If the CONTROL type is 'Multi-Line' this identifies the width of the text box in columns. |
| multi_rows | NUMERIC | If the CONTROL type is 'Multi-Line' this identifies the height of the text box in rows (lines).
If the CONTROL type is 'Dropdown' or 'Multi-Dropdown' this identifies the height of the scrollable area in rows (lines). |
| The following fields are set automatically by the system: | ||
| created_date | DATE+TIME | The date and time on which this record was created. |
| created_user | STRING | The identity of the user who created this record. |
| revised_date | DATE+TIME | The date and time on which this record was last changed. |
| revised_user | STRING | The identity of the user who last changed this record. |
The structure of this table is as follows:
CREATE TABLE `dict_table_key` ( `database_id` varchar(64) NOT NULL default '', `table_id` varchar(64) NOT NULL default '', `key_name` varchar(64) NOT NULL default '', `column_id` varchar(64) NOT NULL default '', `seq_in_index` tinyint(3) unsigned NOT NULL default '0', `is_unique` char(1) NOT NULL default 'N', `column_seq` tinyint(3) unsigned default NULL, `created_date` datetime NOT NULL default '2000-01-01 00:00:00', `created_user` varchar(16) default NULL, `revised_date` datetime default NULL, `revised_user` varchar(16) default NULL, PRIMARY KEY (`database_id`,`table_id`,`key_name`,`column_id`) ) TYPE=MyISAM;
| Field | Type | Description |
|---|---|---|
| database_id | STRING | The database identity. Links to an entry on the DICT_TABLE table. |
| table_id | STRING | The table identity. Links to an entry on the DICT_TABLE table. |
| key_name | STRING | As a table can have more than one key each one requires a unique identifier. The primary key is given the name 'PRIMARY'. |
| column_id | STRING | The column identity. Links to an entry on the DICT_COLUMN table. This is the identity of the column that appears within this key. A column may appear only once in any key, but it may appear in more than key for the same table. |
| seq_in_index | NUMERIC | A key may be comprised of more than one column, so this is the sequence number of this column within the key. |
| is_unique | BOOLEAN | Keys may be unique or non-unique. This identifies if the key is unique or not. |
| column_seq | NUMERIC | This is the sequence number of the entry returned by the SHOW INDEX statement which was issued to the database. |
| The following fields are set automatically by the system: | ||
| created_date | DATE+TIME | The date and time on which this record was created. |
| created_user | STRING | The identity of the user who created this record. |
| revised_date | DATE+TIME | The date and time on which this record was last changed. |
| revised_user | STRING | The identity of the user who last changed this record. |
The structure of this table is as follows:
CREATE TABLE `dict_relationship` ( `database_id_snr` varchar(64) NOT NULL default '', `table_id_snr` varchar(64) NOT NULL default '', `database_id_jnr` varchar(64) NOT NULL default '', `table_id_jnr` varchar(64) NOT NULL default '', `seq_no` tinyint unsigned NOT NULL default '0', `table_alias_snr` varchar(64) default NULL, `table_alias_jnr` varchar(64) default NULL, `relation_name` varchar(80) default NULL, `relation_desc` text, `relation_type` char(3) NOT NULL default '', `orderby` varchar(64) default NULL, `parent_field` varchar(64) default NULL, `calc_field` varchar(255) default NULL, `created_date` datetime NOT NULL default '2000-01-01 00:00:00', `created_user` varchar(16) default NULL, `revised_date` datetime default NULL, `revised_user` varchar(16) default NULL, PRIMARY KEY (`database_id_snr`,`table_id_snr`,`database_id_jnr`,`table_id_jnr`,`seq_no`) ) TYPE=MyISAM;
| Field | Type | Description |
|---|---|---|
| database_id_snr | STRING | The identity of the parent/senior database in the relationship. Links to an entry on the DICT_TABLE table. |
| table_id_snr | STRING | The identity of the parent/senior table in the relationship. Links to an entry on the DICT_TABLE table. |
| database_id_jnr | STRING | The identity of the child/junior database in the relationship. Links to an entry on the DICT_TABLE table. |
| table_id_jnr | STRING | The identity of the child/junior table in the relationship. Links to an entry on the DICT_TABLE table. |
| seq_no | NUMERIC | If there is more than one relationship between the same tables - in other words, it has duplicates - then this value is a means of making the key unique. The default value is zero for the first entry, and should be incremented for duplicate entries. |
| table_alias_snr | STRING | Optional. Where multiple relationships between the same tables exist this is a means of providing an alias for the parent/senior table. |
| table_alias_jnr | STRING | Optional. Where multiple relationships between the same tables exist this is a means of providing an alias for the child/junior table. |
| relation_name | STRING | A user-defined name for the relationship. |
| relation_desc | TEXT | A user-defined description for the relationship. |
| relation_type | STRING | This specifies how the relationship is to be treated when deleting entries from the parent/senior table. Possible values are:
The CASCADE and NULLIFY selections have two options each: 'framework' (performed by the framework) or 'FK constraint' (performed by a Foreign Key Constraint in the database). The 'framework' option will be slower as it will read each child record, update it, and record the change in the AUDIT database. |
| orderby | STRING | Optional. This is only used when REL-TYPE = 'CASCADE'. It identifies the sequence in which child entries will be processed when they are deleted. |
| parent_field | STRING | Optional. When dealing with a single occurrence from the child table there is code in the standard table class which will attempt to access the parent (foreign) table and bring back one of its fields for inclusion in the data array for the child. This is used to specify which field to return. Possible values area:
|
| calc_field | STRING | Optional. This is only used when PARENT-FIELD = 'CALCULATED'. It provides a means of returning a value from the parent table which is not one of the existing field names. For example:
|
| The following fields are set automatically by the system: | ||
| created_date | DATE+TIME | The date and time on which this record was created. |
| created_user | STRING | The identity of the user who created this record. |
| revised_date | DATE+TIME | The date and time on which this record was last changed. |
| revised_user | STRING | The identity of the user who last changed this record. |
The structure of this table is as follows:
CREATE TABLE `dict_related_column` ( `database_id_snr` varchar(64) NOT NULL default '', `table_id_snr` varchar(64) NOT NULL default '', `column_id_snr` varchar(64) NOT NULL default '', `database_id_jnr` varchar(64) NOT NULL default '', `table_id_jnr` varchar(64) NOT NULL default '', `seq_no` tinyint unsigned NOT NULL default '0', `column_id_jnr` varchar(64) default NULL, `seq_in_index` tinyint(4) unsigned NOT NULL default '0', `created_date` datetime NOT NULL default '2000-01-01 00:00:00', `created_user` varchar(16) default NULL, `revised_date` datetime default NULL, `revised_user` varchar(16) default NULL, PRIMARY KEY (`database_id_snr`,`table_id_snr`,`column_id_snr`,`database_id_jnr`,`table_id_jnr`,`seq_no`) ) TYPE=MyISAM;
| Field | Type | Description |
|---|---|---|
| database_id_snr | STRING | The identity of the parent/senior database in the relationship. Links to an entry on the DICT_COLUMN table. |
| table_id_snr | STRING | The identity of the parent/senior table in the relationship. Links to an entry on the DICT_COLUMN table. |
| column_id_snr | STRING | The identity of a column in the primary key of the parent/senior table. Links to an entry on the DICT_COLUMN table. |
| database_id_jnr | STRING | The name of the child/junior database in the relationship. Links to an entry on the DICT_COLUMN table. |
| table_id_jnr | STRING | The identity of the child/junior table in the relationship. Links to an entry on the DICT_COLUMN table. |
| seq_no | NUMERIC | If there is more than one relationship between the same tables - in other words, it has duplicates - then this value is a means of making the key unique. The default value is zero for the first entry, and should be incremented for duplicate entries. |
| column_id_jnr | STRING | The identity of a column in the child/junior table which corresponds with COLUMN_ID_SNR. Links to an entry on the DICT_COLUMN table. |
| seq_in_index | NUMERIC | The primary key on the parent table may be comprised of more than one column, so this is the sequence number of this column within the key. |
| The following fields are set automatically by the system: | ||
| created_date | DATE+TIME | The date and time on which this record was created. |
| created_user | STRING | The identity of the user who created this record. |
| revised_date | DATE+TIME | The date and time on which this record was last changed. |
| revised_user | STRING | The identity of the user who last changed this record. |
These are the maintenance screens for the Data Dictionary:
My whole development methodology is built around the philosophy of having a separate class for each database table. Some OO proponents consider this approach to be pure heresy, but I choose to ignore them.
Files <tablename>.class.inc and <tablename>.dict.inc are created by the Export Table to PHP process.
File <dbname>.dict_export.inc is created by the Export Database process.
All the standard functionality for accessing a database table is contained within an abstract superclass, so all that is required for each individual table is a simple script that extends this into a subclass, as shown in the sample below:
<?php require_once 'std.table.class.inc'; class #tablename# extends Default_Table { // **************************************************************************** // class constructor // **************************************************************************** function __construct () { // save directory name of current script $this->dirname = dirname(__file__); $this->dbname = '#dbname#'; $this->tablename = '#tablename#'; // call this method to get original field specifications // (note that they may be modified at runtime) $this->fieldspec = $this->loadFieldSpec(); } // __construct // **************************************************************************** } // end class // **************************************************************************** ?>
During the export process the strings #dbname# and #tablename# are replaced with the relevant values. The loadFieldSpec() method will load additional information regarding the structure of that table from the corresponding <tablename>.dict.inc file into the common table properties.
Upon first seeing one of these classes a casual observer may notice that there are no methods apart from the constructor, and these may lead that person to believe that the class does not perform any operations on its data therefore is a prime example of an Anemic Domain Model. If you look closely you will see that each table class extends or inherits from an abstract superclass, and it is this superclass which contains all the relevant processing in the form of Template Methods. The invariant/fixed methods have their implementations defined in the abstract superclass while the variant/customisable methods, while also defined in the superclass, have empty implementations which can be replaced with actual implementations in any subclass. These variant/customisable methods are also known as hook methods.
Notice that, for reasons described in Separate properties for database columns are NOT best practice, I do not define a class property for each column within the table, nor do I define getters and setters for each column. I find this approach too restrictive as it promotes tight coupling instead of the preferred loose coupling, so instead I do the following:
The loadFieldSpec() method is defined within the superclass and will load the contents of <tablename>.dict.inc into the class instance at runtime using code similar to the following:
function loadFieldSpec ()
// set the specifications for this database table.
{
if (empty($this->fieldspec)) {
// first time only - look for changes in engine, prefix or database name
list($this->dbname, $this->dbprefix, $this->dbms_engine) = findDBConfig($this->dbname,
$this->dbprefix,
$this->dbms_engine);
} // if
$fieldspec = array();
$this->primary_key = array();
$this->unique_keys = array();
$this->child_relations = array();
$this->parent_relations = array();
$this->audit_logging = FALSE;
$this->default_orderby = '';
$this->alt_language_table = '';
$this->alt_language_cols = '';
$this->nameof_start_date = '';
$this->nameof_end_date = '';
if ($this->getTableName() != 'default') {
// include table specifications generated by Data Dictionary
require ($this->dirname .'/' .$this->getTableName() .'.dict.inc');
} // if
return $fieldspec;
} // loadFieldSpec
This subclass, when combined with the standard code inherited from the superclass, is enough to provide all the code necessary to perform insert, select, update and delete operations on that database table, with all primary validation being performed using the rules provided by the contents of <tablename>.dict.inc.
The default processing for any table can be modified by inserting the required code into the customisable methods (identified by the prefix '_cm_') which have been defined as empty stubs within the superclass. The default processing contains calls to these empty methods at various stages of its processing, as shown in UML diagrams for the Radicore Development Infrastructure. Simply copy the empty method from the superclass to the subclass and whatever code you place within it will be executed at runtime instead of the empty original.
Note that should the table details be re-exported from the data dictionary then this file will NOT be overwritten in order to preserve any manual amendments.
This file contains information that was contained within the Data Dictionary at the time the EXPORT function was processed. Note that should the table details be re-exported from the data dictionary then this file will be overwritten, so any manual amendments will be lost. If any changes need to be made to any of this data at run time in a particular object then these changes should be made in the _cm_changeConfig() method of the table's class file. Any such changes will be lost when the script terminates.
Note that any columns with the description set to 'DEPRECATED' will not be exported and so will be invisible to the table class. This can be used in those organisations which prefer to mark a redundant column as 'deprecated' instead of physically removing it from the database schema.
This file is presented in a format which is readily accessible to PHP scripts. The structure of this file is as follows:
<?php // file created on May 30, 2005, 10:45 am // field specifications for table dbname.tblname $fieldspec['fieldname1'] = array('keyword1' => 'value1', 'keyword2' => 'value2'); $fieldspec['fieldname2'] = array('keyword1' => 'value1', 'keyword2' => 'value2'); // primary key details $this->primary_key = array('field1','field2'); // unique key details $this->unique_keys[] = array('field1','field2'); $this->unique_keys[] = array('field3','field4'); // child relationship details $this->child_relations[] = array('child' => 'tblchild', 'dbname' => 'dbchild', 'subsys_dir' => 'dirname', 'alias' => 'tblchild_alias', 'type' => 'RES/CAS/NUL', 'orderby' => 'field1,field2,...', 'fields' => array('fldparent1' => 'fldchild1', 'fldparent2' => 'fldchild2')); $this->child_relations[] = array(...); // parent relationship details $this->parent_relations[] = array('parent' => 'tblparent', 'dbname' => 'dbparent', 'subsys_dir' => 'dirname', 'alias' => 'tblparent_alias', 'parent_field' => 'fieldname', 'alt_language_table' => 'tablename', 'alt_language_cols' => 'fieldname1,fieldname2,...', 'fields' => array('fldchild1' => 'fldparent1', 'fldchild2' => 'fldparent2')); $this->parent_relations[] = array(...); // determines if database updates are recorded in an audit log $this->audit_logging = TRUE/FALSE; // default sort sequence $this->default_orderby = 'fieldname1,fieldname2,...'; // alternative language options $this->alt_language_table = 'tablename'; $this->alt_language_cols = 'fieldname1,fieldname2,...'; // alias names $this->nameof_start_date = 'nameof_start_date'; $this->nameof_end_date = 'nameof_end_date'; // extra_names/extra_values table names $this->nameof_extra_names_db = 'nameof_extra_names_db'; $this->nameof_extra_names_tbl = 'nameof_extra_names_tbl'; $this->nameof_extra_values_db = 'nameof_extra_values_db'; $this->nameof_extra_values_tbl = 'nameof_extra_values_tbl'; // finished ?>
Each individual component of this file is described below.
This has the following format:
// field specifications for table dbname.tblname $fieldspec['fieldname1'] = array('keyword1' => 'value1', 'keyword2' => 'value2'); $fieldspec['fieldname2'] = array('keyword1' => 'value1', 'keyword2' => 'value2');
An entry is created here for each field (column) within the database table. Each entry has an array of keywords and values which identify how the field is to be dealt with as it passes in and out of the application. Please note the following:
The meanings of each entry are:
| Keyword | Value |
|---|---|
| type | The identifies the field type. Possible values are:
|
| size | The size of the field. This is used to set the MAXLENGTH and SIZE options for the HTML control. During validation of user input any value which exceeds this length will be rejected. |
| precision | For numeric values this is the number of digits, including decimals. For example, the value 999.99 has a precision of 5. |
| scale | For numeric values this is the number of digits that can be stored following the decimal point. For example, the value 999.99 has a scale of 2. |
| zerofill=y | Available for unsigned numeric fields only. Causes leading zeros to be shown as '0' instead of ' ' (blank). |
| blank_when_zero=y | Available for numeric fields only. Causes a zero value to be displayed as ' ' (blank). |
| auto_increment=y | For numeric fields only. On an INSERT the database will provide the next sequence number. |
| minvalue | During the validation of user input this is the minimum value that can be accepted. |
| unsigned=y | During the validation of user input this will cause any negative values to be rejected. |
| maxvalue | During the validation of user input this is the maximum value that can be accepted. |
| pkey=y | This indicates that this field is part of the primary key and cannot be changed once it has been written to the database. |
| required=y | This will cause an empty input field to be rejected unless:
|
| default | The default value for this column as defined within the database. If IS_REQUIRED is TRUE and no value is supplied on an INSERT, this default value will be used. |
| password=y | This is used for HTML controls only. It causes user input to be masked. |
| uppercase=y | This will cause all user input to be shifted into uppercase before being written to the database. |
| lowercase=y | This will cause all user input to be shifted into lowercase before being written to the database. |
| autoinsert=y | This is only used when new records are inserted. A value will automatically be inserted according to the field's TYPE:
|
| autoupdate=y | Same as for AUTOINSERT, but for updates. |
| infinityisnull=y | This is valid for columns of type DATE only. It means that a blank date on the screen will be held in the database as '9999-12-31' instead of '0000-00-00'. See Dealing with null End Dates for a detailed explanation. |
| true | For BOOLEAN fields this identifies how a TRUE value will be recorded in the database. It may be '1' or 'T' or 'Y', for example. |
| false | For BOOLEAN fields this identifies how a FALSE value will be recorded in the database. It may be '0' or 'F' or 'N', for example. |
| subtype | This optional setting is available only for fields of type STRING. Possible values are:
NOTE: if CONTROL=FILEPICKER and SUBTYPE=IMAGE or VIDEO the HTML output will show the following:
If in some screens it is required to display the image without the file name, the text can be suppressed by adding |
| custom_validation | This option is available for any field. It identifies the validation method to be used for this field. The format is 'file/class/method' where:
|
| image_width | Only valid if CONTROL='IMAGE' or SUBTYPE='IMAGE' or 'VIDEO'. Identifies the width of the image in pixels. |
| image_height | Only valid if CONTROL='IMAGE' or SUBTYPE='IMAGE' or 'VIDEO'. Identifies the height of the image in pixels. |
| control | This identifies the HTML control to be used when the field is built into a screen (and is amendable). Possible values are: If this is not specified the default control will be a standard TEXT BOX. |
| optionlist | This is only valid when CONTROL='DROPDOWN', 'MULTIDROP' or 'RADIO'. It is the name the list of items that will be used to populate that HTML control. This list should be constructed within the table class and written out to the XML file. |
| label | This is only valid when CONTROL='CHECKBOX'. It provides an optional piece of text that will be placed either to the left or right of the control depending on ALIGN_LR. |
| task_id | If CONTROL = 'FILEPICKER' or 'POPUP' this is the name of the TASK that will be activated to provide the picklist of available options. |
| foreign_field | If the CONTROL = 'POPUP' this is name of a field on the foreign table that will be merged with the contents of the current table before being output to the XML file. This will allow the key value, which may be meaningless to the user, to be replaced with a more descriptive value. |
| align_hv | If the CONTROL = 'RADIO' this identifies how the list of options should be aligned. Possible values are:
|
| align_lr | If the CONTROL = 'RADIO' this identifies whether the text for each button goes on the left or the right. If the CONTROL = 'CHECKBOX' this identifies whether the optional CHECKBOX_LABEL goes on the left or the right. Possible values are:
|
| cols | If the CONTROL = 'MULTILINE' this identifies the width of the text box in columns. |
| rows | If the CONTROL = 'MULTILINE' this identifies the height of the text box in rows (lines).
If the CONTROL = 'DROPDOWN' or 'MULTIDROP' this identifies the height of the scrollable area in rows (lines). |
| noedit=y | This is used when building the input form for the user. This field will be set to read-only. |
| nodisplay=y | This is used when building the input form for the user. For DETAIL screens both the label and the field will be left out of the form. For LIST screens the column heading will remain but the value will be blanked out. |
| nosearch=y | This is used when building SEARCH screens. It will cause the field to be left out of the form. |
| noaudit=y | This is used when recording database updates in the Audit Log. If this is set then the actual value will be replaced by a series of asterisks (*). |
The $fieldspec array has several uses:
size option will be used to set the field size, for example.pkey option means that the field will be editable only on INSERT and SEARCH screens.noedit option will cause the field to be rendered as non-editable.nodisplay option will cause the field value to be completely omitted from the HTML output. For DETAIL screens both the label and the field will be omitted. For LIST screens the column heading will remain but the value will be blanked out.nosearch option will cause the field to be removed from search screens.$fieldspec array to be modified at runtime. Thus it is possible to change a field from editable to non-editable, or even hide it altogether. It is even possible to change the HTML control type - in one application I have a field which may vary between a multi-line text box, a dropdown list or a number depending on different settings. Code in the entity class detects what is required and alters the $fieldspec array accordingly. This information is written out to the XML document so it can be actioned by the XSL transformation.Note that there are other options which may be added to any entry in this array within program code as discussed in Additional options for the $fieldspec array.
This has the following format:
// primary key details $this->primary_key = array('field1','field2');
This is an indexed array containing one or more field names which together form the primary key of this database table.
This information is used just before an INSERT to check that a record with this key does not currently exist, otherwise an error message will be returned to the user. If the primary key contains a field with AUTO-INCREMENT=TRUE then this check will not be performed.
If a primary key contains more than one column then none of those columns is allowed to be NULL.
The value in a primary key cannot be changed.
This has the following format:
// unique key details $this->unique_keys[] = array('field1','field2'); $this->unique_keys[] = array('field3','field4');
These are unique keys that are in addition to the primary key, and are sometimes known as candidate keys. As a table may have zero or more additional keys this array may be empty, or it may contain a separate entry for each additional key. Each entry will itself be an array containing one or more field names.
This information is used just before an INSERT or UPDATE to check that a record with each key does not currently exist, otherwise an error message will be returned to the user.
If a candidate key contains more than one column and any of these columns is NULL then the entry will not be added to the unique index.
The value in a candidate key can be changed, but the new value cannot already exist in the index.
This has a separate entry for each table which is the child in a parent-child relationship with this table. This also maps the primary key on this table to the foreign key of the child table. It has the following format:
// child relationship details $this->child_relations[] = array('child' => 'tblchild', 'dbname' => 'dbchild', 'subsys_dir' => 'dirname', 'alias' => 'tblchild_alias', 'type' => 'RES/CAS/NUL', 'orderby' => 'field1,field2,...', 'fields' => array('fldparent1' => 'fldchild1', 'fldparent2' => 'fldchild2')); $this->child_relations[] = array(...);
An entry is created here for each instance where this table is defined as the parent in a parent-to-child (one-to-many, senior-to-junior) relationship. Note that a table can be the parent in any number of relationships. The meanings of each entry are:
| 'child' => 'tblchild' | tblchild identifies the name of the child table in this parent-child relationship. |
| 'dbname' => 'dbchild' | Not currently used (for information only). |
| 'subsys_dir' => 'dirname' | If this child table does not reside in the same directory as this parent then dirname provides the directory name from the SUBSYSTEM entry. This is used on an include() statement to identify the location of the class file so that an object of this child table class can be instantiated. |
| 'alias' => 'tblchild_alias' | It is possible for more than one relationship to exist between the same pair of tables, so this is a means of giving each occurrence of the duplicated child table an alias name as an aid to identification. The tblchild_alias value is taken from the TABLE_ALIAS_JNR column of the RELATIONSHIP table. |
| 'type' => 'RES/CAS/NUL/IGN' | This identifies the type of processing to be performed when an attempt is made to delete on entry from the parent table. The possible values are:
The CASCADE and NULLIFY selections have two options each: 'framework' (performed by the framework) or 'FK constraint' (performed by a Foreign Key Constraint in the database). The 'framework' option will be slower as it will read each child record, update it, and record the change in the AUDIT database. |
| 'orderby' => '... , ...' | This is an optional list of field names separated by commas. It is only relevant when 'type' => 'CAS' as it identifies the order in which the occurrences from the child table should be retrieved before they are deleted. This is because the records may have a sequence number and it is only allowed to delete the record with the highest number. |
| 'fields' => array( 'fldparent1' => 'fldchild1', 'fldparent2' => 'fldchild2') |
In any parent-child relationship the primary key field(s) in the parent table must be linked to corresponding field(s) in the child table. Each entry in this array identifies which field from the parent table (fldparentN) is associated with which field in the child table (fldchildN). Note that this structure allows for the fact that corresponding fields may not have the same name in the two tables. |
This has a separate entry for each table which is the parent in a parent-child relationship with this table. This also maps foreign keys on this table to the primary key of the parent table. It has the following format:
// parent relationship details $this->parent_relations[] = array('parent' => 'tblparent', 'dbname' => 'dbparent', 'subsys_dir' => 'dirname', 'alias' => 'tblparent_alias', 'parent_field' => 'fieldname', 'alt_language_table' => 'tablename', 'alt_language_cols' => 'fieldname1,fieldname2,...', 'fields' => array('fldchild1' => 'fldparent1', 'fldchild2' => 'fldparent2')); $this->parent_relations[] = array(...);
An entry is created here for each instance where this table is defined as the child in a parent-to-child (one-to-many, senior-to-junior) relationship. Note that a table can be the child in any number of relationships. The meanings of each entry are:
| 'parent' => 'tblparent' | tblparent identifies the name of the parent table in this parent-child relationship. |
| 'dbname' => 'dbparent' | If this parent table does not belong in the same database then dbparent is used as the qualifier in the JOIN clause of the sql SELECT statement which is generated by the system (refer to Using Parent Relations to construct sql JOINs for details). |
| 'subsys_dir' => 'dirname' | If this parent table does not reside in the same directory as this child then dirname provides the directory name from the SUBSYSTEM entry. This is used on an include() statement to identify the location of the class file so that an object of this parent table class can be instantiated. |
| 'alias' => 'tblparent_alias' | It is possible for more than one relationship to exist between the same pair of tables, or for a table to be related to itself, so this is a means of giving each occurrence of the duplicated parent table an alias name as an aid to identification. The tblparent_alias value is taken from the TABLE_ALIAS_SNR column of the RELATIONSHIP table. Refer to Using Parent Relations to construct sql JOINs for examples of specifying alias names. |
| 'parent_field' => '...' | In some cases it is a common requirement that when reading an occurrence of the child table that a lookup be performed on the parent table in order to bring back one or more fields from the parent table (for example, to bring back a COUNTRY_NAME for a given COUNTRY_CODE). This structure provides the means for this to be performed automatically by the standard code (refer to Using Parent Relations to construct sql JOINs).
One or more field names can be specified here by using the Update Relationship screen. |
| 'fields' => array( 'fldchild1' => 'fldparent1', 'fldchild2' => 'fldparent2') |
In any parent-child relationship the primary key field(s) in the parent table must be linked to corresponding field(s) in the child table. Each entry in this array identifies which field from the parent table (fldparentN) is associated with which field in the child table (fldchildN). Note that this structure allows for the fact that corresponding fields may not have the same name in the two tables. |
| 'alt_language_table' => '...'
'alt_language_cols' => '...' |
This identifies those columns on this table which are also available on another table in an alternative language. Please refer to Internationalisation and the Radicore Development Infrastructure (Part 2) for details. |
The information in the $parent_relations array is used to help construct sql SELECT statements, as explained in Using Parent Relations to construct sql JOINs. It is also referenced in the getForeignData() method which will perform a separate lookup for each relationship.
This has the following format:
// determines if database updates are recorded in an audit log $this->audit_logging = TRUE/FALSE;
This switch can either be TRUE or FALSE. If TRUE then any INSERT, UPDATE or DELETE operation on this table will cause the Data Access Object (DAO) to pass control to the Audit Logging system so that the changes can be logged in the AUDIT database. These changes will then be available for viewing using standard online enquiry screens.
This has the following format:
// default sort sequence $this->default_orderby = 'fieldname1,fieldname2,...';
This is a string containing zero or more field names. When occurrences of this table are retrieved for LIST screens this will be used as the sort sequence unless other sorting criteria has been specified either for the TASK or by the use of the column headings.
This has the following format:
// alternative language options $this->alt_language_table = 'tablename'; $this->alt_language_cols = 'fieldname1,fieldname2,...';
These two strings identify the fact that this table has columns which have translations in alternative languages on another table. his is described in Internationalisation and the Radicore Development Infrastructure (Part 2).
This has the following format:
// alias names
$this->nameof_start_date = 'nameof_start_date';
$this->nameof_end_date = 'nameof_end_date';
Each of these strings identifies the column which is to be treated as start_date or end_date, but which has a different name. These two dates identify the period during which the record is to be considered as "current" or "available". This allows different records with different values, such as those of a PRICE file, to be created so that when the date changes the "current" value will be used instead of the "historic" value.
// extra_names/extra_values table names
$this->nameof_extra_names_db = 'nameof_extra_names_db';
$this->nameof_extra_names_tbl = 'nameof_extra_names_tbl';
$this->nameof_extra_values_db = 'nameof_extra_values_db';
$this->nameof_extra_values_tbl = 'nameof_extra_values_tbl';
This is only used in the commercial version in order to provide links to tables which contain data in additional to that contained within the standard tables.
It is sometimes necessary to take the details which have been entered into one data dictionary and copy them into another. Typing in the details manually would be too cumbersome, and copying the entire dictionary database may include unwanted details. Another option would be to export the details for selected application databases into an SQL script which can then be processed by whatever utility comes with your database engine.
This facility will create an SQL script containing INSERT/REPLACE statements for each record in the data dictionary which belongs to the selected application database. This script can then be used to import the same details into another dictionary database.
Using this function to provide an export of dictionary data would be a good idea before the erase function is used.
When a table class is instantiated into an object the constructor for that class will load the contents of the <table>.dict.inc file into memory. During the execution of a task it is possible to amend the contents of this data before it is actually used, but why would there be any need to do so? You may wish to amend the $fieldspec options for an existing field by adding or removing the noedit option or the nodisplay option. You may even wish to change the control from 'dropdown list' to a 'popup' should the number of entries be too great.
There may also be times when you need to add entries for field names which do not actually exist in that table. By default any field which is sent to the screen without having an entry in the $fieldspec array will be displayed as a piece of read-only text. A date field, for example, will have its contents displayed as '2016-05-23'. To have it properly formatted into '23 Jun 2016' you would have to add an entry to the $fieldspec array such as the following:
function _cm_changeConfig ($where, $fieldarray) // Change the table configuration for the duration of this instance. { if (!isset($this->fieldspec['dummy_date'])) { $this->fieldspec['dummy_date'] = array('type' => 'date', 'size' => 12); } // if return $fieldarray; } // _cm_changeConfig
This is fine in a read-only screen, but if the operation is an INSERT or an UPDATE then the framework will assume that the dummy_date field belongs in the table and will pass its details to the DML object so that it can be included in the SQL query, and this will result in a fatal error. This can be avoided by including the nondb (non-database) keyword which, by default, will also prevent the field's contents from being validated. The full range of options which can be included in the $fieldspec array within program code but not via the Data Dictionary screens is contained in the following list:
| Keyword | Value |
|---|---|
| nondb=y | This indicates that the field does not actually exist within the current table, so it will not be validated. Furthermore, if available during an INSERT or an UPDATE operation the field and its data will NOT be passed to the DML object otherwise it will cause a fatal error. |
| novalidate=y | This turns off field validation, but will still include the field in any database INSERT or UPDATE. |
| mustvalidate=y | This can be used with the nondb option to allow the field's value to be validated, but it will still be excluded from any database INSERT or UPDATE. |
| no_undef=y | By default when a checkbox, which can only have a value for either ON or OFF, is used in a search screen, it is changed to a radiogroup so that it can provide a third option for 'undefined'. If this third option is not required then this attribute can be added to the field's specifications which will then keep it as a checkbox without the 'undefined' option. |
Accessing the database is performed by constructing a query string within the data access layer and sending this to the database via the relevant API. Because this string is constructed from several smaller substrings which are generated in the business layer it is possible to incorporate the details of any parent relationships so that the sql SELECT statement which is constructed will include the relevant JOIN clauses to bring back the specified field(s) from the parent table(s). It is also possible to specify alias names to deal with those situations when a table appears more than once in the same SELECT statement.
The full query string is constructed using the following substrings:
$query = "SELECT $select_str FROM $from_str $where_str $group_str $having_str $sort_str $limit_str";
These are described in more detail in How to extend the SQL SELECT statement.
Just before the business layer component passes control to the data access layer to retrieve data from the database it will check to see if it needs to include any JOIN clauses for parent relations. The actual sequence of events is as follows:
$from_str is not empty then skip this processing. This means that the developer has provided a customised SELECT string and does not want the system to automatically add in any extra JOIN clauses.$select_str is empty then insert <tablename>.*.<tablename> into $from_str.parent_field then ignore this entry. If no data is going to be retrieved from this parent table then there is no point in JOINing to it.parent_field to the contents of $select_str.'LEFT JOIN <tblparent>' to the contents of $from_str.alias is defined then append ' AS <alias>' to the contents of $from_str.fields array to construct the ' ON (tblparent.fldparent=tblchild.fldchild) clause, and append it to the contents of $from_str.If all these substrings are still empty by the time they reach the data access layer, then:
$select_str to '*'.$from_str to the current table name.Here are some examples of SELECT strings which can be generated by the system when no customised substrings are supplied:
SELECT * FROM x_tree_node WHERE node_id='23'If there are no parent relations then no JOIN clauses can be constructed.
SELECT x_tree_node.*, tree_level_seq, tree_level_desc FROM x_tree_node LEFT JOIN x_tree_level ON (x_tree_level.tree_type_id=x_tree_node.tree_type_id AND x_tree_level.tree_level_id=x_tree_node.tree_level_id) WHERE x_tree_node.node_id='23'In this example
x_tree_level is the parent and x_tree_node is the child. Note here that more than one field is being retrieved from the parent table. It is also possible to specify a calculated field, as in CONCAT(first_name, ' ', last_name) AS person_nameThere is no need to qualify these field names unless they also appear on other tables in the same SELECT statement.
SELECT x_tree_node.*, x_tree_node_snr.node_desc AS node_desc_snr FROM x_tree_node LEFT JOIN x_tree_node AS x_tree_node_snr ON (x_tree_node_snr.node_id=x_tree_node.node_id_snr) WHERE x_tree_node.node_id='23'In this example the table
x_tree_node (primary key node_id) is joined to itself by field node_id_snr which contains the identity of the parent node within the hierarchy of senior-to-junior nodes. Because the table name x_tree_node will appear twice in the same SELECT statement the parent entry is given the alias name of x_tree_node_snr. Because the field name node_desc will appear twice in the same SELECT statement the parent entry is given the alias name of node_desc_snr. Note that this also has to be qualified with the table's alias name.
SELECT mnu_nav_button.*, mnu_task_snr.task_desc AS task_desc_snr, mnu_task_jnr.task_desc AS task_desc_jnr FROM mnu_nav_button LEFT JOIN mnu_task AS mnu_task_snr ON (mnu_task_snr.task_id=mnu_nav_button.task_id_snr) LEFT JOIN mnu_task AS mnu_task_jnr ON (mnu_task_jnr.task_id=mnu_nav_button.task_id_jnr) WHERE mnu_nav_button.task_id_snr='mnu_dialog_type(list)' ORDER BY mnu_nav_button.sort_seq ascIn this example the table
mnu_nav_button is related to table mnu_task twice, using a field with either a '_snr' or '_jnr' suffix. Each occurrence of the table name is therefore given an alias which, by coincidence, also includes the same suffix. Note also that this requires the field name(s) which are to be retrieved from each parent table to be given the same qualifier as that table's alias.
SELECT x_tree_node.node_id, x_tree_node.tree_type_id, x_tree_node.tree_level_id, ...,
COALESCE(...) AS node_desc,
COALESCE(...) AS tree_level_desc,
COALESCE(...) AS node_desc_snr,
COALESCE(...) AS tree_type_desc
FROM x_tree_node
LEFT JOIN x_tree_level ON (x_tree_level.tree_type_id=x_tree_node.tree_type_id
AND x_tree_level.tree_level_id=x_tree_node.tree_level_id)
LEFT JOIN x_tree_node AS x_tree_node_snr ON (x_tree_node_snr.node_id=x_tree_node.node_id_snr)
LEFT JOIN x_tree_type ON (x_tree_type.tree_type_id=x_tree_node.tree_type_id)
WHERE ( x_tree_node.node_id='44' )
where each COALESCE statement is in the format:
COALESCE((SELECT <field> FROM <table_alt> WHERE <table_alt>.<foreign_key>=<table>.<primary_key> AND <table_alt>.language_id='??') , <table>.<field>) AS <field>The details of the alternative language option are explained in Internationalisation and the Radicore Development Infrastructure (Part 2).
All of the above is standard SQL, therefore should work in any standards-compliant database engine.
In those transaction patterns such as LIST2 and LIST3 which deal with two or more entities in a parent-child/one-to-many relationship, it is possible to use the information in the $parent_relations array when constructing the WHERE clause which is passed from the parent object to the getData() method of the child object. This is useful in those situations where the names of the columns in the child's foreign key are different from the corresponding names in the parent's primary key as it will deal automatically with any differences in the names.
Note that this procedure cannot be used when a WHERE string is constructed in a parent task and passed to a child task by pressing a navigation button as the child task does not know the name of the table in the parent task, and if there are alias names it would not know which one to use.
The procedure, which is performed by the getForeignKeyValues() function, will examine the contents of the $parent_relations array in the child object and stop when it finds the first of the following:
Note here that 'parent_name' is obtained by using getClassName() on the parent object as this can provide an alias name. An alias name which is defined in the Data Dictionary can also be used to provide a subclass with the same name.
If an entry is found it steps through the 'fields' array which equates a column name 'fldchild' in the child entity with a column name 'fldparent' in the parent entity and creates an entry in the output array with the name 'fldchild' and the value obtained from the parent's data with the name 'fldparent'.
If an entry is not found in the $parent_relations array then the default behaviour is to use the column names of the parent's primary key to populate the output array. It is then up to the child object to have the code necessary to convert the column names in the WHERE string.
This a simple parent-child relationship with a compound foreign key which produces the following metadata in the $parent_relations array for the child table:
$this->parent_relations[] = array('parent' => 'parent_table', 'fields' => array('foo_id' => 'bar_id', 'fubar_id' => 'snafu_id'));
When the primary key values are extracted from the parent table the result will be as follows:
bar_id='bar_id_value' AND snafu_id='snafu_id_value'
After being processed by the getForeignKeyValues() function it will look like the following:
foo_id='bar_id_value' AND fubar_id='snafu_id_value'
Here is an example from the MENU database where the MNU_TASK table has a primary key of task_id and the MNU_MENU table has two foreign keys, menu_id and task_id_jnr, which both relate back to task_id. The $parent_relations array for MNU_MENU contains the following:
$this->parent_relations[] = array('parent' => 'mnu_task', 'alias' => 'mnu_task_snr', 'fields' => array('menu_id' => 'task_id')); $this->parent_relations[] = array('parent' => 'mnu_task', 'alias' => 'mnu_task_jnr', 'fields' => array('task_id_jnr' => 'task_id'));
Note here that in each of the relationships between MNU_TASK and MNU_MENU a different alias name is provided for the MNU_TASK table. This mechanism also requires that for each alias name a separate subclass be created with that name. This subclass extends the parent class and need not contain any code as its main purpose is to provide a different class name at runtime. It is also necessary to have a separate LIST2 task to show the data for each relationship, and for each of these tasks to use the correct alias name for its outer/parent entity. From a LIST1 task which shows records from the MNU_TASK table, a record with the primary key 'task_id'='foobar' is selected, then a navigation button is pressed in order to activate one of the aforementioned LIST2 tasks. Although both tasks have MNU_TASK as the outer/parent entity and MNU_MENU as the inner/child entity, the use of alias names for outer/parent will cause this function to produce different results
This task is designed to display, for a selected menu, all those child tasks which are options on that menu. It has the following component script:
<?php $outer_table = 'mnu_task_snr'; // name of outer table $inner_table = 'mnu_menu'; // name of inner table $screen = 'mnu_menu.list2.screen.inc'; // file identifying screen structure require 'std.list2.inc'; // activate page controller ?>
Because the class name of the parent is given as "mnu_task_snr" this will be matched with the first of the $parent_relations entries shown above. This will cause the value task_id = xxx in the parent's data to be converted to menu_id = xxx before it is passed to the child object.
This task is designed to display, for a selected task, all those menu tasks for which this task is an option. It has the following component script:
<?php $outer_table = 'mnu_task_jnr'; // name of outer table $inner_table = 'mnu_menu_snr'; // name of inner table $screen = 'mnu_menu.list2.screen.inc'; // file identifying screen structure require 'std.list2.inc'; // activate page controller ?>
Because the class name of the parent is given as "mnu_task_jnr" this will be matched with the second of the $parent_relations entries shown above. This will cause the value task_id = xxx in the parent's data to be converted to task_id_jnr = xxx before it is passed to the child object.
As well as being able to generate the table classes from the Data Dictionary, it is now possible to generate the PHP scripts which use these table classes so that the user can view and maintain the contents of these database tables. This is achieved in the following steps:
This procedure will generate the following:
If the selected pattern is the parent in a family of forms this procedure will also generate a MNU_TASK entry for each of its children as well as adding them to the navigation bar of the parent form. If it is a LIST1 pattern it will also be added as an item to that subsystem's main menu.
This feature now means that starting with nothing more than the schema for an application database it is possible to import that database schema into the Radicore framework then generate all the components necessary to maintain each of those database tables without writing a single line of code. These generated components may be basic in their construction, but they are fully functional. They may be modified afterwards for cosmetic reasons, or to add in additional business rules. Once generated these files cannot be regenerated, so any modifications cannot be accidentally overwritten.
This capability is explained in Radicore for PHP - Tutorial and this video.
This Data Dictionary is not a stand-alone product. It is an integral part of the following:
| 01 Nov 2022 | Altered the DICT_TABLE table to include the nameof_extra_names_tbl and nameof_extra_values_tbl columns. |
| 09 Nov 2020 | Altered Additional options for the $fieldspec array to include the 'no_undef' option. |
| 01 Jun 2017 | Altered the DICT_DATABASE table to rename database_desc to database_name and db_comment to database_desc.
Altered the DICT_TABLE table to rename table_desc to table_name and tbl_comment to table_desc. Altered the DICT_COLUMN table to rename column_desc to column_name and col_comment to column_desc. Altered the DICT_RELATIONSHIP table to rename relation_desc to relation_name and rel_comment to relation_desc. |
| 01 Jun 2016 | Added Additional options for the $fieldspec array.
Added 'video' as another option for subtype. |
| 30 Jan 2016 | Added Using Parent Relations to construct WHERE strings.
Amended <tablename>.dict.inc to exclude any columns marked as 'deprecated'. |
| 1st Dec 2013 | Amended the DICT_RELATIONSHIP table to allow the rel_type column to include the 'IGNORE' option, and to expand the 'CASCADE' and 'NULLIFY' options to include 'framework' or 'FK constraint'. |
| 1st May 2010 | Amended the $fieldspec array to allow a control type of 'image'. |
| 1st Mar 2010 | Amended the $fieldspec array to allow a control type of 'image hyperlink'. |
| 1st Apr 2009 | Amended the DICT_TABLE table to include the nameof_start_date and nameof_end_date columns, and added the $nameof strings section. |
| 1st Feb 2008 | Amended the COL_ZEROFILL_BWZ column on the DICT_COLUMN table to accept the STRIP TRAILING ZERO option. |
| 1st Feb 2008 | Added $alt_language strings and amended $parent_relations array to include details of alternative language options, as detailed in Internationalisation and the Radicore Development Infrastructure (Part 2). |
| 15th Jan 2007 | Amended DICT_COLUMN table to include COL_TYPE_NATIVE which holds the datatype as known to the database. In some cases this may be shown as a collection of data types, such as "CHAR,BOOLEAN" where one data type on the database, such as CHAR, may actually be used as another, such as BOOLEAN, which is not supported by that database. This is also true of the Oracle DATE data type which may actually be used as DATE (without TIME), TIME (without DATE) or DATETIME (DATE and TIME together). |
| 15th Oct 2006 | Added Generate PHP scripts |
| 9th Sep 2006 | Added field CUSTOM_VALIDATION to the contents of the DICT_COLUMN table. |
| 3rd Aug 2006 | Added MULTI-SELECT DROPDOWN to the list of HTML controls. |
| 15th May 2006 | Added HYPERLINK to the list of HTML controls. |
| 30th Apr 2006 | Added CHECKBOX to the list of HTML controls.
Added column CHECKBOX_LABEL to the DICT_COLUMN table. Added column ALIGN_LR to the DICT_COLUMN table. Amended $fieldspec array to incorporate these new columns. |
| 20th Jan 2006 | Added Using Parent Relations to construct sql JOINs. |
| 18th Dec 2005 | Added a NOAUDIT switch to the DICT_COLUMN table to prevent a field from appearing in the audit log. |
| 11th Dec 2005 | Added Export Database and Erase Database to the maintenance screens.
Added <dbname>.dict_export.inc to Export Files. |
| 18th July 2005 | Changed column COL_ZEROFILL to COL_ZEROFILL_BWZ to allow an extra option to show '0.00' as blank (Blank When Zero) as well as filling leading blanks with '0' (Zero Fill). |