Figure 1 - The 3-Tier Architecture
I recently came across an article called Increasing complexity one entity at a time which identified a problem with some people's approach to Object Oriented Programming (OOP). This problem is caused by a certain practice which most OO programmers regard as being standard but which I regard as a complete Pile Of Poo (POP). This is the practice of using inheritance for "is-a" relationships and object composition for "has-a" relationships. This is described in Inheritance, composition and the meaning of "is a" which contains the following statement:
I'm guessing most of us heard that inheritance is for is-a relationships and composition is for has-a relationships one time or another.
This message is echoed in Java 101 primer: Composition and inheritance which contains the following statement:
In Java 101: Inheritance in Java, Part 1 you learned how to leverage inheritance for code reuse, by establishing is-a relationships between classes. This free Java 101 primer focuses on composition, a closely related programming technique that is used to establish has-a relationships instead.
The whole idea of "is-a" being implemented via inheritance and "has-a" being implemented via object composition is completely alien to me. In fact, the whole idea of Object Oriented Design (OOD) and all that it entails is something which I avoid like the plague and wouldn't touch with a barge pole. This is not because I am an idiot or have been badly trained, but because of the 20+ years of training and experience in the design and construction of database applications for the enterprise which I accumulated before moving to a language which supported OO. Those decades of experience taught me the following:
Most of this experience was spent working for software houses where we had to respond to a customer's Specification Of Requirements (SOR) with an outline design as well as cost and time estimates. When we won the business we then had to deliver the goods, and I can honestly say that none of the systems that I designed and built ever failed, nor did any go over budget or over time (at least, not by a significant amount). Having designed and built many systems in several non-OO languages using hierarchical, network and relational databases I became quite proficient at data analysis and data normalisation. Building one new system after another also taught me the value of building code libraries which could be used in multiple applications. Over a period of time these libraries morphed into full-blown frameworks, the first of which I wrote in COBOL which I later rewrote in UNIFACE and then PHP.
I started to use PHP in 2002, but before I could make proper use of its OO capabilities I first had to find out what OO actually meant and how the language could help me write programs which were object oriented. My research led me to the following definition:
Object Oriented Programming is programming which is oriented around objects, thus taking advantage of Encapsulation, Inheritance and Polymorphism to increase code reuse and decrease code maintenance.
You may think that OO requires more than that, but Alan Kay (who invented the term "object oriented") would disagree. In addition, Bjarne Stroustrup (who designed and implemented the C++ programming language), provides this broad definition of the term "Object Oriented" in section 3 of his paper called Why C++ is not just an Object Oriented Programming Language:
A language or technique is object-oriented if and only if it directly supports:
- Abstraction - providing some form of classes and objects.
- Inheritance - providing the ability to build new abstractions out of existing ones.
- Runtime polymorphism - providing some form of runtime binding.
In his paper Encapsulation as a First Principle of Object-Oriented Design (PDF) the author Scott L. Bain wrote the following:
... OO is routed in those best-practice principles that arose from the wise dons of procedural programming. The three pillars of "good code", namely strong cohesion, loose coupling and the elimination of redundancies, were not discovered by the inventors of OO, but were rather inherited by them (no pun intended).
In my article What is Object Oriented Programming (OOP)? I make the following observations:
When some people say that OO programming is completely different from procedural programming they are making a fundamental mistake. OO programming is exactly the same as procedural programming except for the addition of encapsulation, inheritance and polymorphism.
This notion is discussed more in my article What is the difference between Procedural and OO programming? in which I state the following:
Object Oriented programming is exactly the same as Procedural programming except for the addition of encapsulation, inheritance and polymorphism. They are both designed around the idea of writing imperative statements which are executed in a linear fashion. The commands are the same, it is only the way they are packaged which is different. While both allow the developer to write modular instead of monolithic programs, OOP provides the opportunity to write better modules.
I am not the only one who shares this opinion. In his article All evidence points to OOP being bullshit John Barker says the following:
Procedural programming languages are designed around the idea of enumerating the steps required to complete a task. OOP languages are the same in that they are imperative - they are still essentially about giving the computer a sequence of commands to execute. What OOP introduces are abstractions that attempt to improve code sharing and security. In many ways it is still essentially procedural code.
Later versions of various OO languages have added more features, and some people seem to think that it is these additional features which decide if a language is OO or not. I totally disagree for the reasons stated in What OOP is Not, as well as this list of optional OO features for which I have found no use. It would be like saying that a car is not a car unless it has climate control and satnav. Those are optional extras, not the distinguishing features, and not using them does not make your code not OO. It would also be incorrect to say that a car is a car because it has wheels. Having wheels does not make something a car - a pram has wheels, but that does not make it a car, so having wheels is not a distinguishing feature.
A definition which contains terms is pretty worthless unless you also have a description of what those terms actually mean, so these are the definitions of those terms which I use:
| Class | A class is a blueprint, or prototype, that defines the variables and the methods common to all objects (entities) of a certain kind. A class represents a common abstraction of a set of entities, suppressing their differences.
In a database application each table has its own blueprint which is defined in the DDL script, and different rows in that table have different values which match that blueprint. Every table, regardless of the data which it holds, is subject to exactly the same methods, which are Create, Read, Update and Delete (CRUD). |
| Object | An instance of a class. A class must be instantiated into an object before it can be used in the software. More than one instance of the same class can be in existence at any one time. |
| Encapsulation | The act of placing an entity's data and the operations that perform on that data in the same class. The class then becomes the 'capsule' or container for both the data and the operations.
Note that this requires ALL the properties and ALL the methods to be placed in the SAME class. Breaking a single class into smaller classes so that the count of methods in any one class does not exceed an arbitrary number is therefore a bad idea as it violates encapsulation and makes the system harder to read and understand. It would also decrease cohesion and increase coupling which would be the exact opposite of what should be achieved. Note that data may include meta-data (type, size, etc) as well as entity data. |
| Inheritance | The reuse of base classes (superclasses) to form derived classes (subclasses). Methods and properties defined in the superclass are automatically shared by any subclass. A subclass may override any of the methods in the superclass, or may introduce new methods of its own.
All the Model classes in the business/domain layer are database tables, so in my approach each concrete table class inherits from an abstract table class. |
| Polymorphism | Same interface, different implementation. The ability to substitute one class for another. This means that different classes may contain the same method signatures (which are not the same as object interfaces), but the result which is returned by a particular method will be different as the code behind that method (the implementation) is different in each class.
Note that this does NOT require the use of the keywords "interface" and "implements" as these are totally optional in PHP. All that is required is that different classes implement the same method name with the same signature. Each of my 40 reusable Controllers interacts with the 300+ business/domain layer (Model) classes via methods defined in the abstract table class, which means that any Controller can access any Model. Each Controller contains a particular set of method calls on an unknown Model, and the results of each method call varies from one Model to another. The identity of the Model is not hard-coded into any Controller, it is passed to it at runtime using a mechanism known as Dependency Injection. |
The following are not defining features of OO for the simple reason that they existed before OO came into being.
| Abstraction | The process of separating the abstract from the concrete, the general from the specific, by examining a group of objects looking for both similarities and differences. The similarities can be shared by all members of that group while the differences are unique to individual members.
There are two flavours of abstraction: |
| Coupling | Describes how modules interact. The degree of mutual interdependence between modules/components. The degree of interaction between two modules. |
| Cohesion | Describes the contents of a module. The degree to which the responsibilities of a single module/component form a meaningful unit. The degree of interaction within a module. |
Some programmers try to claim that PHP is not an OO language, but as even PHP4 met the requirements that were identified by the man who invented the term I consider this claim to have zero merit.
OOP requires the definition of classes which can be turned into objects at runtime. The first problem is therefore identifying those entities with which your application is expected to communicate.
In his article How to write testable code the author describes three main categories of object that may appear in a computer system:
| Entities | An object whose job is to hold state and associated behavior. The state (data) can be persisted to and retrieved from a database. Examples of this might be Account, Product or User. In my framework each database table has its own Model class. |
| Services | An object which performs an operation. It encapsulates an activity but has no encapsulated state (that is, it is stateless). Examples of Services could include a parser, an authenticator, a validator or a transformer (such as transforming raw data into HTML, CSV or PDF). In my framework all Controllers, Views and DAOs are services. |
| Value objects | An immutable object whose responsibility is mainly holding state but may have some behavior. Examples of Value Objects might be Color, Temperature, Price and Size. PHP does not support value objects, so I do not use them. I have written more on the topic in Value objects are worthless. |
This is also discussed in When to inject: the distinction between newables and injectables.
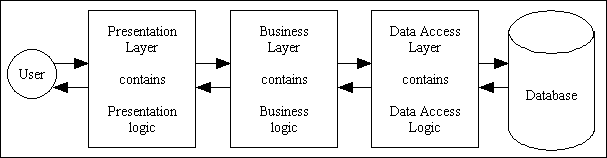
It may not be obvious to the beginner, but it is considered very bad form to put all your code into a single class, just as it is considered bad form to put all your data into a single database table. The code that you write for a database application can be broken down into three distinct categories: Presentation/GUI logic, Business/Domain logic and Data Access logic. This is not just my opinion, it is echoed in the following articles:
This produces the architecture which is shown in Figure 1:
Figure 1 - The 3-Tier Architecture
Most of today's developers are more familiar with the MVC architecture which is shown in Figure 2:
Figure 2 - The Model-View-Controller structure
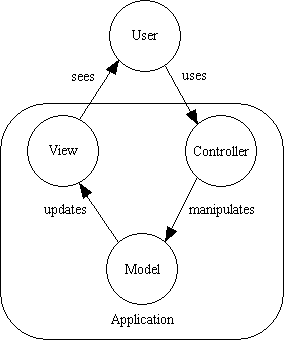
While similar, these two architectural patterns are not the same, but they do overlap and can exist together, as shown in figure 3:
Figure 3 - MVC plus 3 Tier Architecture
")
It is a combination of these two architectures which I used in my open source RADICORE framework, the full structure diagram of which is shown in Figure 4:
Figure 4 - RADICORE framework structure
")
Note that in the above diagram each of the numbered components is a clickable link.
The classes which are the main topic of this article are those which contain the business logic of the application and which reside in what can be called the Business layer, the Domain layer or the Model layer. The components in the other layers will be discussed later on.
One of the big selling points of OOP is that you can model the real world!
, but a lot of developers fail to realise that you do not model the whole of the real world, only those parts in which you are actually interested. Different entities in the real world may have exotic sets of methods (also known as operations, functions or actions) and properties (also known as attributes, variables or data), but you need only create software models which contain those methods and properties which are actually relevant to your application.
This brings me to my next point. You may be building an Order Processing application that deals with entities such as Customers, Products and Sales Orders, so the novice designer will start by making a list of all the methods and properties of people (who are customers), products (the items being sold) and sales orders (agreements to purchase). IMHO this is a BIG mistake. A Person, for example, may have methods such as "stand", "sit", "walk", "run", "eat", "sleep" and "defecate" and properties such as "blue eyes", "brown hair", "6 foot tall", "weighs 12 stone" and "likes cats", but none of these have ever been relevant in any Order Processing application that I have written. They usually restrict themselves to "name", "postal address" and "email address". Similarly different physical products may have oodles of methods and properties which are totally ignored except for "identity", "description" and "price". When it comes to Sales Orders, these never exist physically in the real world. In pre-computer days all sales orders were filled out on paper, but nowadays sales orders are rarely printed, if ever. They are merely stored as bits and bytes in a computer system, but may be passed around electronically as PDF documents.
An Order Processing application, or indeed ANY database application, does not therefore interface with any entities in the real world, it only interfaces with tables in a database, so it should not be a big step to regard each database table as an entity from which you can create a class. When I first published this idea I was immediately branded as a heretic as every competent programmer knows that having a separate class for each database table is not good OO. Another reason was phrased as follows:
I understand the point of reusing code to generate SELECT/INSERT/UPDATE/DELETE statements, but you can do that without having to create a class for every table you have. Say I wanted to talk to the table 'cars'. I'd compose an object by creating an instance of a Table class and add rules represented as objects to it. I think that if you ask some good designers they will tell you that an approach which uses instances of a single Table class is better than one which requires the declaration of a new class for each new table.
Each database table has its own data structure and its own business rules, therefore surely qualifies for its own class. The idea of having an empty table class into which I can later inject the data structure, the business rules and the methods seems to me to be an overly complex way of doing such a simple thing - I would have to hold the data structure, business rules and methods somewhere in the application before I could inject them into an empty Table object in order to make a usable object. Instead of creating an instance of the Table class I turn it into an abstract table class which can never be instantiated. Instead of having code to inject a particular table's details into the empty Table object I hold those details in a concrete table class and replace all that injecting code with the single word "extends". If you look at the definition of a class you will see that it says A class is a blueprint, or prototype, that defines the variables and the methods common to all objects (entities) of a certain kind.
If you look at the DDL for a database table then surely this qualifies as the "blueprint" for every record that will be written to that table?
Later on the same critic wrote:
Abstract concepts are classes, their instances are objects. IMO The table 'cars' is not an abstract concept but an object in the world.
Why don't you read what you wrote? If the table 'cars' is not abstract then it must be concrete, just like the table 'product', 'customer, 'order' and 'shipment'. However, the concept of an unspecified table is NOT concrete, it is abstract. That is precisely why I have an abstract table class which specifies the methods and properties for an unspecified database table, and a separate concrete class for each actual database table which inherits from this abstract class. My main application has over 300 tables, so that's a lot of inheritance.
Somebody once told me:
If you have one class per database table you are relegating each class to being no more than a simple transport mechanism for moving data between the database and the user interface. It is supposed to be more complicated than that.
You are missing an important point - every user transaction starts life as being simple, with complications only added in afterwards as and when necessary. This is the basic pattern for every user transaction in every database application that has ever been built. Data moves between the User Interface (UI) and the database by passing through the business/domain layer where the business rules are processed. This is achieved with a mixture of boilerplate code which provides the transport mechanism and custom code which provides the business rules. All I have done is build on that pattern by placing the sharable boilerplate code in an abstract table class which is then inherited by every concrete table class. This has then allowed me to employ the Template Method Pattern so that all the non-standard customisable code can be placed in the relevant "hook" methods in each table's subclass. After using the framework to build a basic user transaction it can be run immediately to access the database, after which the developer can add business rules by modifying the relevant subclass.
The RADICORE framework provides more boilerplate code in the form of reusable Controllers and Views which can operate with any database table which you care to construct. These components do not contain any business rules, they simply pass data to and from the client device, and they do not care about what sort of data it is.
Surely all I am doing is following the KISS principle. There is nothing inherently wrong with this, just as there is nothing inherently right about making things more complicated than they need be.
I have been building database applications for several decades in several different languages, and in that time I have built thousands of programs. Every one of these, regardless of which business domain they are in, follows the same pattern in that they perform one or more CRUD operations on one or more database tables aided by a screen (which nowadays is HTML) on the client device. All standard functionality, all the boilerplate code, is provided by the framework while any complicated business rules are placed within the customisable hook methodswithin each table's subclass.
I have been told many times that having one class per database table is simply not done, but I have not been made aware of any problems which this cause. It may disagree with some people's ideas of how it should be done, but not everyone shares that opinion. If it is wrong then why does Martin Fowler, the author of Patterns of Enterprise Application Architecture, have several design patterns for it? Take a look at Table Data Gateway, Row Data Gateway, Class Table Inheritance and Concrete Table Inheritance. Is he wrong, or are you? In his article OrmHate he states the following:
I often hear people complain that they are forced to compromise their object model to make it more relational in order to please the ORM. Actually I think this is an inevitable consequence of using a relational database - you either have to make your in-memory model more relational, or you complicate your mapping code. I think it's perfectly reasonable to have a more relational domain model in order to simplify [or even eliminate] your object-relational mapping.
Note that the words or even eliminate are mine. Later in the same article he also says:
To use a relational model in memory basically means programming in terms of relations, right the way through your application. In many ways this is what the 90's CRUD tools gave you. They work very well for applications where you're just pushing data to the screen and back, or for applications where your logic is well expressed in terms of SQL queries. Some problems are well suited for this approach, so if you can do this, you should.
If programmers say that following the rules of OOP make it either difficult or impossible to write database applications, then why don't they question those rules, or even their interpretations of those rules. When I look at what has been published regarding the principles of OOP the one common factor I see is that they have their roots in the type of software that was being written in the Smalltalk language which was constructed by academics for educational use. When you consider that this language, and its later derivatives, was used to build operating systems, compilers, text processors and process control software - but NEVER enterprise database applications - you should realise that those rules are irrelevant. That is why I do not follow them.
I have been building database applications for the enterprise for several decades in several languages, and I have personally designed and built many thousands of user transactions. No matter how complex an individual transaction may be, it always involves performing one or more CRUD operations on one or more database tables. All I have done is adapt my procedural programming method to encapsulate the knowledge of each database table in its own class, then use inheritance and polymorphism to increase code reuse and decrease code maintenance. This is supposed to be what OOP is all about, so how can I be wrong? In addition, because my class structures and database structures are always kept in sync I do not have any mapping code or any mapping problems.
When I first encountered the Composite Reuse Principle, which is often phrased as favour composition over inheritance
I initially thought that it was a joke. Inheritance is supposed to be one of the three pillars of OOP, so here is someone saying "DON'T USE INHERITANCE!" I could not see any justification for this ridiculous theory, so I chose to ignore it. I later came across ideas such as inheritance breaks encapsulation and inheritance produces tight coupling, but I dismissed them simply because I had found no such problems in my code.
It wasn't until I read Object Composition vs. Inheritance by Paul John Rajlich that I began to see the light. Apparently the only problem with inheritance is that many people do not know how to use it properly in that they often inherit from one concrete class to create a different concrete class and/or create inheritance hierarchies which are too deep. The solution is surprisingly simple - only ever inherit from an abstract class.
I recently encountered a paper called Designing Reusable Classes, published by Ralph E. Johnson & Brian Foote as far back as 1988, which provided complete justification for my method of creating an abstract table class which could be inherited by every concrete table class. They did this by providing the best explanation of abstraction that I have ever read, as explained in my article The meaning of "abstraction":
Abstraction is the process whereby you separate the abstract from the concrete, the similar from the different. The promotes a technique known as programming-by-difference which enables you to put the similar into reusable modules and the different into unique modules.
The idea is that you examine several classes which share common protocols (methods or operations) and move those protocols into an abstract superclass so that they can be shared by numerous concrete subclasses using inheritance. Because these methods are then shared by multiple classes it provides that feature of OOP called polymorphism which then opens the door to another technique of code reuse which is Dependency Injection. This allows you to call a method on an unknown object where the identity of that object is not provided until runtime. This is what allows any of my reusable Controllers to communicate with any of my Models.
As well as providing code reuse through inheritance, abstract classes also provide access to the Template Method Pattern which is a valuable part of framework design as it implements the Hollywood Principle, also known as Inversion of Control. This is where the superclass defines the skeleton of an algorithm with its varying and unvarying parts, and allows the varying parts (known as "hook" methods) to be overridden in a subclass in order to provide customised behaviour.
If the purpose of OOP is to increase code reuse and decrease code maintenance
then any method which achieves this aim should be applauded. All those practices and principles which inhibit this result should be ignored.
According to this wikipedia article the meaning of Object Composition is as follows:
In computer science, object composition and object aggregation are closely related ways to combine objects or data types into more complex ones.
Objects in the real world, as well as in a database, may either be stand-alone, or they have associations with other objects which then form part of larger compound/composite objects. In OO theory this is known as a "HAS A" relationship where you identify that the compound object contains (or is comprised of) a number of associated objects. There are several flavours of association:
Please refer to Using "HAS-A" to identify composite objects for more details.
Many years ago I read a post in a newsgroup where a developer complained that his code was very slow. He had built an application for a school which dealt with entities such as Classroom, Teacher and Student. It also had Subject which was subdivided into Lessons, and Schedule which is an instance of a Teacher giving a Lesson to a group of Students in a particular Classroom on a particular date and time. Following the rules of object composition he had created a School class which had properties for each of these "has-a" entities. When he instantiated the School object this read everything from the database in order to populate each of these child objects. When the volume of data was quite small it ran reasonably quickly, but as he added more and more data it got slower and slower, and he couldn't understand why. His complaint to the newsgroup was I have followed the rules concerning object composition, so why is my software so slow?
The first thing he did wrong was to use object composition. The second thing that he did wrong was to implement it badly.
The idea that you should read all your data into a single object just in case it is needed is not a good idea. Those of us with practical experience know that you only read the data that you need when you actually need it. This philosophy is known as just in time.
I actually wrote my own version of a Classroom Scheduling system way back in 2004 which has exactly the same entities but does not have any performance problems. You can run this code now for yourself by visiting the RADICORE demonstration page, logging on as "demo" and selecting the PROTO menu followed by the CLASSROOM option. This works because I don't use object composition and can access each table's class without going through a parent class, and because each user transaction only reads that data from the tables that it actually needs in order to service the current request.
He follows the rules and creates crap software. I disobey the rules and create good software. What does this tell you about those rules?
I am quite familiar with, and totally agree with, the idea that once you have identified an entity (something which has properties and methods) that needs to be accessed in your application then you should create a class which encapsulates the properties and methods of that entity. Note that this means ALL the properties and ALL the methods of that entity should go into a SINGLE class. The idea that you should split some of these methods or properties off into separate and smaller classes simply because the count exceeds an arbitrary number is an idea that never occurred to me, and now that I know that it exists I am quite happy to ignore it. However, where one of those properties is so complex that it goes beyond being a single value and requires its own table in the database, then I treat that property as a totally separate entity which requires its own independent class.
Figure 7 shows a small ERD, but in a large enterprise application the number of tables and relationships can be much, much larger. My own ERP application, for example, is based on the database designs which can be found in Len Silverston's Data Model Resource Book. A diagram of a subset of the PARTY database is shown in Figure 5, the PRODUCT database is shown in Figure 6, and the ORDER database is shown in Figure 7.
Figure 5 - the PARTY database
")
Note that this design caters for organisations as well as people, and customers as well as suppliers.
A subset of the PRODUCT database is shown in Figure 6:
Figure 6 - the PRODUCT database
")
As you should see there is a relationship between the PARTY table and the PRODUCT table via the PRODUCT_SUPPLIER table, so should this be a child in the PARTY class or the PRODUCT class? Should I have a different version of the PRODUCT_SUPPLIER class for each of its parents?
A subset of the ORDER database is shown in Figure 7:
Figure 7 - the ORDER database
")
As you can see it is just not possible to have a single table for CUSTOMER, PRODUCT and ORDER. They each require such a diverse collection of data that, following the rules of Data Normalisation, they actually require a large collection of tables, large enough to warrant an entire database to themselves. Just as you would not put all that data into a single table I do not see why you should put all the programming logic for those tables into a single class. Each table has its own schema, its own blueprint, its own business rules, so as far as I am concerned it qualifies for its own class. That is the basis on which I built my RADICORE framework in 2002, and as it has worked out so well I see no reason to change it.
By coincidence this actually conforms to the idea that with OOD you use inheritance for each "is-a" relationship. As each of my entities is a database table it therefore inherits from my abstract table class.
Whenever you have a call from one module/component to another the two modules are said to be coupled. Coupling describes how the two modules interact. It describes the degree of mutual interdependence and the degree of interaction between them. Lower coupling is better. Low coupling tends to create more reusable methods. Tightly coupled systems tend to exhibit the following developmental characteristics, which are often seen as disadvantages:
If you create a new table in the database which happens to be the child of an existing table, then you have to make the following changes:
Cohesion describes the contents of a module, the degree to which the responsibilities of a single module/component form a meaningful unit, and the degree of interaction within a module. It is a measure of the strength of association or the functional relatedness of the elements inside a module. Modules with high cohesion are preferable because high cohesion is associated with desirable traits such as robustness, reliability, reusability, extendability, and understandability whereas low cohesion is associated with undesirable traits such as being difficult to maintain, difficult to test, difficult to reuse, difficult to extend, and even difficult to understand.
For example, in my framework I have separate View components which formats application data into HTML, PDF and CSV. Each format requires processing which totally unconnected with that required for the other formats, so it makes sense to keep the code for each format in its own class.
Having a separate class for each database table, and to be able to access that class without having to go through another class, means that each class is limited to the business rules of a single table. Mixing the business rules for several tables in a single class is a practice that I have learned to avoid. Each table is a separate entity in the database, so it should be a separate entity in the software and it should be able to be accessed as a separate entity.
Polymorphism is the ability to call the same method on a number of different classes. This makes the calling module reusable as the identity of the dependent module can be supplied at runtime, usually through a mechanism known as dependency injection, and the method call will still work, although the code which is executed will be different. If a method is only available on a single object then there is no opportunity for polymorphism and no opportunity for reusability. By decreasing the reusability of your code you are therefore violating one of the aims of OOP which is increased reusability. If I can only access the Contact table by going through the Company table then the controller must use code such as the following:
require 'classes/company.class.inc'; $company = new Company; $result = $company->getContactData(); or $result = $company->contact->getData();
This code is tightly coupled and not reusable. Compare this with the following code:
require 'classes/$table_id.class.inc'; $dbobject = new $table_id; $result = $dbobject->getData($where);
This allows to value of $table_id to be set to any table in the database, and the method call will then perform that operation on that table. In my framework I have 40 controllers, one for each Transaction Pattern, that can be used with any Model class in the Business layer by virtue of the fact that the method names are defined in the abstract class which is inherited by each Model class. As my main enterprise application has 300 database tables, this provides the opportunity for 12,000 (300 x 40) polymorphic combinations. If your methodology does not provide that level of reusability then I would strongly suggest that you re-evaluate your methodology as it is failing to deliver what OOP was supposed to deliver.
Another idea which I came across several years after building my framework is that when implementing the MVC design pattern you are supposed to have a separate Controller class for each Model class, and this this single Controller is supposed to be able to deal with every possible Use Case (user transaction).
A Use Case is defined as:
a list of action or event steps, typically defining the interactions between a role/actor and a system, to achieve a goal.
In my universe, which existed before this term was invented, these things called "use cases" were known as "transactions" within a Transaction Processing System. This was later changed to User Transaction in order to differentiate it from a Database Transaction as some user transactions do not actually involve updating the database, so using a COMMIT/ROLLBACK would not be relevant. In my RADICORE framework the term user transaction has been shortened to task, and each task, which performs one of the LIST, SEARCH, INSERT, ENQUIRE, UPDATE or DELETE operations shown in Figure 8, can be selected by a user either from a menu button or a navigation button. Each task has its own component script in the file system which identifies which Model, View and Controller to use.
Some people create complex user transactions by combining several separate operations into one, such as "show a SEARCH screen where the user can enter filters, then show a LIST screen displaying the records which match those filters, allow the user to select a record and then show an ENQUIRE screen which displays all the details for that record". Each of the SEARCH, LIST and ENQUIRE screens should be developed as separate transactions which can be run one after the other in any combination. The idea of predefining which combinations are allowed, and having a separate user transaction for each combination, is an alien concept to me.
The idea of having a single controller which can handle multiple operations is also an idea which I shot down in flames several decades ago. Each operation requires its own pieces of program logic, therefore in order to execute a single operation the controller must contain additional code which identifies which pieces of code need to be included or excluded for that particular operation. Problems arise when a piece of code gets executed when it should not, or does not get executed when it should. This becomes a bigger problem when you try to introduce Role Based Access Control in order to limit particular operations to particular users. I solved this problem in 1985 when I built my first development framework in COBOL by having each user transaction (task) developed as a separate piece of code which had its own entry on the M-TRAN table in the database. Each user had an entry on the M-USER table, and a particular user could only access a particular transaction if there was a corresponding entry on the D-TRAN-USER table. This meant that there was no need for any code inside a transaction which checked to see if a particular user could or could not access a piece of logic as the checking could now be performed by the framework before the transaction was run and not after it had started. Each transaction was activated by pressing a button on a screen, and the framework was programmed not to display those buttons for which the current user did not have access. If the user could not see the button to activate a transaction then he could not run that transaction. How simple is that?
There are some programmers who seem to think that a Controller can only ever access a single Model, but this rule does not exist in my universe. The author of Increasing complexity one entity at a time seems to agree with me as in the paragraph titled Fixing the problem (2nd solution) he says the following:
I then decided to make multiple calls from my pages. If a page needed a company, a list of contacts and a list of engagements related to that company, I would make three calls from the page. This decision made all the "read" objects go away and still kept my code very simple.
If he says it's OK then how can it possibly be wrong?
In his article Objects as Contracts for Behaviour Mathias Verraes makes the following comment:
Of course invoices do not pay themselves, but that's not what an object model is trying to do. An invoice exposes the behaviour of being able to be paid. That ability is in fact essential to what it means to be an invoice. The behaviour is an inherent property of an invoice. If an invoice doesn't have the ability of being paid, there's no point in issuing invoices at all. In other words, the contract of an invoice object declares that its interface includes payment as a feature. Its promise to the outside world is that it allows an outsider to pay for it.
This sentiment is echoed in Domain Driven Design (DDD) which states:
If software processes loan applications, it might have classes like LoanApplication and Customer, and methods such as AcceptOffer and Withdraw.
This idea is often extended into the rule that every use case requires its own method
. I disagree simply because it is not how it is implemented in any enterprise application that I have worked on. In my current ERP application I have over 4,000 tasks (user transactions), and creating a separate method for each one would immediately rule out any possibility of polymorphism as they could not be inserted into an abstract class. By not being able to use an abstract class you then rule out the possibility of using the Template Method Pattern. It would also require specialist Controllers to call those specialist methods which would rule out any possibility of using dependency injection with reusable Controllers. By ruling out such basic methods of providing reusable code you would be negating the effects of using OOP in the first place, in which case you should rule out the possibility of ever becoming an effective OO programmer.
How is it possible to achieve these results without using specialised methods? You have to remember that in a database application the entities called INVOICE and PAYMENT are both database tables, and the only operations that can be performed on a database table are Create, Read, Update and Delete (CRUD). In my framework these operations are built into my abstract table class which is inherited by every concrete table (Model) class. Every one of my 40 page controllers communicates with its Model by using these generic methods, which means that every one of those page controllers is capable of being used with any of my 300+ table classes. Thus by opening up the door to polymorphism I have created a huge amount of reusable code, and as this is supposed to be one of the objectives of OOP it must be a good idea.
How is it possible to perform these operations by calling generic methods? You should realise that in an application each use case is implemented as a user transaction (task) which can be selected from a menu. Each task consists of a Controller which calls a Model which in turn calls a DAO to update the database. So for each use case you need to identify exactly what database operations are needed to achieve the desired result.
In order to implement the use case "add a payment to an invoice" it is not as simple as updating a single column in the INVOICE table. In a properly designed system you must allow for payments of different types (credit card, cheque, etc). You must also be able to deal with partial as well as full payments, and provide the ability to either void or refund a payment. This means that all payments are held on their own PAYMENT table while the invoice balance - the difference between the invoice amount and any payments - is held on the INVOICE table. In order to complete this use case the user transaction must achieve the following:
Point #1 can be done by creating a task which combines the standard ADD 1 pattern and the PAYMENT table. This will use the generic insertRecord() method to add a record to the PAYMENT table, such as in the following:
$table_id = 'payment'; ..... require "classes/$table_id.class.inc"; $dbobject = new $table_id; $result = $dbobject->insertRecord($_POST); if ($dbobject->errors) { $errors = array_merge($errors, $dbobject->errors); $dbobject->rollback(); } else { $dbobject->commit(); } // if
Point #2 can be achieved by inserting the following code into the _cm_post_insertRecord() method of the PAYMENT class:
function _cm_post_insertRecord ($fieldarray) // perform custom processing after database record has been inserted. { $dbobject = RDCsingleton::getInstance('invoice'); $pkey['invoice_id'] = $fieldarray['invoice_id']; $result = $dbobject->updateRecord($pkey); if ($dbobject->errors) { $this->errors = array_merge($this->errors, $dbobject->errors); } // if return $fieldarray; } // _cm_post_insertRecord
You may notice that this code does not actually identify which columns on the INVOICE table need to be updated with what values. This is because the updateRecord() method contains a call to the _cm_pre_updateRecord() method, and this method in the INVOICE class contains code similar to the following:
function _cm_pre_updateRecord ($fieldarray) // perform custom processing before database record is updated. { $where = array2where($fieldarray, $this->getPkeyNames()); $dbobject = RDCsingleton::getInstance('payment'); $fieldarray['total_paid'] = $dbobject->getCount("SELECT SUM(payment_amount)) FROM payment WHERE $where"); $fieldarray['balance'] = $fieldarray['invoice_amount'] - $fieldarray['total_paid']; return $fieldarray; } // _cm_pre_updateRecord
Notice that I do not bother with a special updateBalance() method as I want the balance to be automatically updated in every update operation, and this can be done with the generic updateRecord() method.
In order to implement the use case "reschedule an appointment" this could be as simple as updating the appointment_date column on the APPOINTMENT table, in which case all you need to do is create a task which combines the standard UPDATE 1 pattern and the APPOINTMENT table. Note that this will allow any column except for the primary key to be updated.
By working with the fact that I am updating a relational database, and breaking down each use case into specific database operations, I am able to perform each of those operations with a combination of pre-written and reusable generic code plus the addition of custom code in the relevant custom methods. This achieves the necessary results, but with far less effort, so how can it possibly be wrong?
In What entities can be turned into classes? I identified two categories for objects - entities (domain objects) and services. The main difference between the two is that entities have state which can persist while services do not.
A problem arises because some programmers have great difficulty in answering these two questions:
As far as I am concerned any business logic which is specific to a single entity belongs in the class which represents that entity, and these classes belong in the Domain/Business layer. This, after all, is what encapsulation is all about. However, in any application there will be some logic that will need to be performed on the data for many entities, not just a specific entity, and it is this logic that can safely be put into separate service objects.
In order to put this idea into practice you must start with a multi-layer architecture. My own framework for example, is a combination of the 3-Tier Architecture and the MVC Design Pattern as it contains Models, Views, Controllers and Data Access Objects.
They exist in the Business/Domain layer and encapsulate all the business logic for each of the entities which are used within the application. The classes for these entities are generated by the application developer from the table definitions within the application database.
They exist in the Presentation/UI layer and turn requests from the user into actions which are performed on one or more objects in the Business/Domain layer. Each of these has been written to work with any domain object, not just a single specific object, which makes them infinitely reusable. As such they are supplied within the framework and do not have to be touched by the developer.
They exist in the Presentation/UI layer and transform the raw data produced by objects in the Business/Domain layer into the format desired by the user, with different objects for HTML (using reusable XSL stylesheets), CSV and PDF output. They can do this by extracting the object's data in a single array variable, and then iterate through this array one row and one column at a time, which means that they do not need to contain any hard-coded column names. Each of these has been written to work with any domain object, not just a single specific object, which makes them infinitely reusable. As such they are supplied within the framework and do not have to be touched by the developer.
They exist in the Data Access layer and translate requests from a domain object into SQL queries which are executed on a particular DBMS engine, with separate classes for MySQL, PostgreSQL, Oracle and SQL Server. They do not contain any hard-coded table or column names so can operate on any table in the database. As such they are supplied within the framework and do not have to be touched by the developer.
All application logic is contained within the Domain/Business layer in the form of Model classes which are generated by the developer with the help of the Data Dictionary. All Views, Controllers and DAOs are application-agnostic as they do not contain any application logic, only general-purpose framework logic. They are supplied within the framework, can work with any domain object, and do not have to be touched by the developer, therefore can be regarded as services.
I am often asked the question I have been taught that there is only one way to do OO, and you are not following that way, so how can it possibly work?
. When I explain that I design my database first and then build the software around the database design, as taught in the Jackson Structured Programming course I attended decades ago, I am then told But that's not how it's supposed to be done!
One indignant OO "expert" went so far as to tell me I tried that approach once, and I couldn't get it to work
. That just tells me that his implementation was seriously flawed, and if he cannot achieve what generations of programmers have been doing for decades, then what does that say about his programming skills?
I had been writing database applications in several non-OO languages for several decades before I switched to PHP and its OO capabilities in 2002, so I wanted to continue doing what had worked successfully till then, but to take advantage of encapsulation, inheritance and polymorphism in order to increase code reuse and decrease maintenance. This, after all, is supposed to be what OO is all about.
It is only after writing large numbers of programs which maintain the contents of large numbers of database tables that you begin to see patterns emerging, and it is the ability to turn these patterns into reusable code which is the mark of a good programmer. But when do these patterns start to emerge?
Even in my COBOL days I could see patterns when, after having written a set of CRUD screens for one database table, I was asked to write a similar set of screens for another database table. Unfortunately the means to propagate that pattern in those days was very primitive as it involved making a copy of the first program, then going through the code line by line in order to change all references to table and column names from the first table to the new table. It was quite tedious, but it was quicker than writing a brand new program from scratch. This assured that the structure of the first program, a structure which had hopefully been completely debugged, was duplicated in the new program. Unfortunately if any flaws were found in this structure there were multiple copies of the code which then needed to be modified. Although it was possible to put some common code into libraries, there was no way to easily reuse a program structure except for this copy-paste technique. The common structure I used for building CRUD screens in the COBOL language is shown in Figure 8:
Figure 8 - A typical Family of Forms
")
Note: each of the boxes in the above diagram is a clickable link. Here is an overview of what each function does:
These six functions use only two screen structures between them:
In the early 1990s my employer switched from COBOL to UNIFACE, which was based on the 3-Schema approach:
The Physical Schema was handled by a built-in database driver which connected the UNIFACE application to a particular DBMS at runtime. This allowed an application to be developed using one DBMS and deployed using another.
The Conceptual Schema was an internal database known as the Application Model or Repository which contained information on entities (tables), fields, keys (indexes) and relationships, together with referential integrity, for the application database. Each entity and field in the model had properties and a set of triggers, which were containers for Proc code (Uniface's procedural language). Application databases were first defined in the Conceptual Schema and then exported to the DBMS-of-the-day by means of a CREATE TABLE script.
Components were created by embedding objects from the Application Model into the layout canvas. This would start with rectangle called an entity frame which was linked to a particular entity into which other objects, either fields from that entity or another related entity, could then be painted. At runtime the user would press a button to fire the "read" trigger and this would read a record from the database and populate the fields in the screen. This would start at the outermost entity and work its way inwards one entity at a time. This is why in those Transaction Patterns which deal with more than one database table I use terms such as "outer" and "inner" entity.
The main advantage of this language was that you could develop an application for one OS and DBMS and then deploy it on a completely different OS and DBMS. Another advantage was that developers never had to write any SQL queries as they were generated automatically at runtime by whatever database driver had been configured. This also had a big disadvantage - it was impossible to write complex queries or to use JOINs.
It was through working with UNIFACE that I learned about the 3-Tier Architecture. This was implemented in the following manner:
I also learned about XML documents, XSL transformations and component templates.
UNIFACE was initially developed for client/server applications, but the facility to deal with web pages was added on later. I felt that the mechanism for building web pages was far too cumbersome (the use of XSL transformations did not include the ability to create HTML output) so I decided to switch to a more appropriate language. I chose PHP.
I started to teach myself how to program with PHP in 2002. This was with PHP4 as PHP5 did not exist at that time. As I had already written successful frameworks in both COBOL and UNIFACE I started with the database design, then built the components to maintain each of its tables. I did not use Object Oriented Design (OOD) as I did not agree with its "is-a" and "has-a" approach for dealing with relations. I also did not like the idea of using an alien technique for designing my software structure as it totally contradicted what I had learned in Jackson Structured Programming and had used successfully for decades. The very idea of being forced to use an Object Relational Mapper filled me with horror.
I chose to use the 3-Tier Architecture as I liked the way it split the program logic into separate layers. I started by building a class in the Business layer for the first table, then a script in the Presentation layer which translated requests from the user into method calls on that class. As I had already proved to myself that PHP could adequately produce XML files and perform XSL transformations I decided to produce all HTML in this way. It was several years later on when a colleague pointed out that what I had actually developed was an implementation of the MVC design pattern. That is why I tell people that I did not not use that pattern by design but by accident.
After having written the code to deal with the first database table, which had zero inheritance and zero reusability, I then copied this code to deal with the second database table. I then started to refactor the code by creating an abstract table class which could be inherited by every concrete table class, then moved duplicated code from each of my two concrete classes into the abstract class. This left each concrete class with surprising little code:
Because I was dealing with database tables, and there are only four basic operations which can be performed on a database table - create read, update and delete - I initially built only four methods into my abstract table class, which were insertRecord(), getData(), updateRecord() and deleteRecord(). All the default code for dealing with these methods was built into the abstract class, but I interrupted this processing flow with a series of blank customisable methods which could be copied into the concrete class and then filled with code so that the default behaviour could be overridden.
I did not like the idea of defining each database column as a separate property in the class so I stuck with a single $fieldarray variable which holds the data in an associative array. I find it much easier to pass the data between different objects in a single variable, either as an argument on the method call or its return value. I can therefore adjust the contents of the array without adjusting the coupling between objects, which provides for loose coupling which is supposed to be better than tight coupling. This means that I can add or remove columns for individual use cases at will, which includes the use of JOIN clauses which add columns from other tables. This associative array can also be turned into a multi-dimensional array in order to hold data for multiple rows by using the row number as the key at the first level.
Because of the way I had written my page controllers the only difference between them was the name of the table class, so I split each controller into two separate parts - a component script which identifies which table class to use, and a reusable controller script which performs operations on that table. This is a technique which I later learned was called Dependency Injection.
In my original implementation I used a separate custom-built XSL stylesheet for each screen into which all column names and the HTML controls which they were to use were hard-coded. By refactoring this code I found a way of inserting the column names and their controls into the XML document so that I only needed a very small set of reusable XSL stylesheets which could then deal with any screen in the application. This is done by creating a simple screen structure file which is copied into the XML document and then used by the XSL stylesheet to work out which piece of data goes where. This meant that the form structure shown in Figure 8 could be implemented using a single stylesheet for all LIST forms and a single stylesheet for all child/DETAIL forms.
Uniface had a feature called Component Templates which I converted into Transaction Patterns. Several programmers have told me that these patterns do not exist because nobody famous has ever written about them. This just tells me that their ability to recognise patterns or recurring themes is sadly lacking. They will pontificate wildly about design patterns while failing to realise that they do not actually provide reusable code, only designs which then have to be coded by hand. My Transaction Patterns are genuine patterns because it is possible to say "Take this object, that pattern, and generate a new component".
In my original implementation I had all SQL queries generated within the abstract class, but then I moved them to a separate object so that I could easily switch to another DBMS. This was useful when it came to handle the switch from the old mysql extension to the new "improved" extension when MySQL version 4.1 was released in 2003. I later added classes to deal with PostgreSQL, Oracle and SQL Server.
In my original implementation I created all the table class files by hand, but then I created a Data Dictionary to do this for me. Unlike the Application Model in UNIFACE, which was maintained by the developer and then exported to the database by generating a CREATE TABLE script, my version works in the opposite direction. The database structure is created manually, then imported into the dictionary, then exported to create the table class file and a separate structure file. I made these files separate so that the structure file could be regenerated while the class file would be untouched in case it had been customised.
In my original implementation I created the component scripts and screen structure scripts manually, and also added the component details to the MENU database manually, but I later modified my Data Dictionary to do this job for me using my library of Transaction Patterns.
This depends on the structure of the particular screen or form. Each screen can be split into several distinct areas which contain specific pieces of data, some of it provided by the framework and some of it from the application database. The area for application data may be subdivided into different zones for different entities. A LIST1 pattern uses a single application zone, as does an ADD1, ENQUIRE1, UPDATE1, DELETE1 and SEARCH1. The LIST2 and MULTI2 patterns use two zones, an outer/parent and an inner/child, whereas the LIST3 and MULTI3 patterns use three zones.
When a single use case requires reading from more than one database table you have to be careful to avoid the infamous N+1 problem which can be stated simply as:
The "N+1" problem involves reading from two tables which exist in a parent-child relationship. In the case of starting with the "child" and including a column from the "parent", the "1" is the query which reads from the "child" table and the "N" is one query for each parent table for each row in the "child" table.
If the 1st query reads 10 rows from "child" you will then need an additional 10 queries to read the "parent" of each of those "child" rows. If the child has more than 1 parent this will require 10 additional queries for each parent.
In the case of populating one area with one row from the "parent" and populating a second area with multiple rows from the "child", some OR mappers will perform one query for the parent and a separate query for each row of the child.
In order to include data from multiple tables in a single zone, eg. from "child" to "parent", the preferred approach is to use JOIN clauses in the SQL query. It is possible to get the framework to construct this type of query for you provided that the relevant information has been provided on the parent relationships.
An alternative but less efficient approach would be to read the different tables one at a time starting with the following code in the _cm_post_getData() method of the first table:
$other = RDCsingleton::getInstance('other_table'); foreach ($rows AS $rowdata) { $where2 = array2where($rowdata, $other->getPkeyNames()); $other_data = $other->getData($where2); if (!empty($other_data)) } $other_data = $other_data[0]; $rowdata['field1'] = $other_data['field1']; $rowdata['field2'] = $other_data['field2']; } // if } // foreach
If a screen has more than one application zone then the Controller will require a separate Model class for each zone. In the case of a parent-child relationship this will operate as follows:
$parent->getData($where). This may retrieve multiple rows depending on the contents of $where, but it will only return a single row at a time due to LIMIT being set to 1. If more rows are available a scroll bar will be made available in order to step through the other rows.$parent and place it in the $child_where string.$child->getData($child_where). The number of rows returned will depend on the current page size. If more rows are available a pagination bar will be made available in order to step through the other rows.Unless you are using a MULTI4 pattern which allows updates to both the parent and child entities, the Controller will only be able to send the contents of the $_POST array to a single Model entity, as in $object->insertRecord($_POST) or $object->updateRecord($_POST). This means that, by default, it will only be able to update that particular database table. In order to deal with other database tables you will have to put code into the either the _cm_post_insertRecord() or _cm_post_updateRecord() methods, as in the following example:
$other = RDCsingleton::getInstance('other_table');
$other_data = $other->insertRecord($rowdata);
if ($other->errors) {
$this->errors = array_merge($this->errors, $other->getErrors());
} // if
Note that each class, thanks to its own version of $fieldspec, knows which fields are valid for its database table, so will ignore any data in its $fieldarray or $rowdata array. This also means that when passing the data to the $other object it is not necessary to filter the data. Nor is it necessary to pass the data one field at a time as everything is always passed around in a single array.
In OOP relationships go by a different name - object associations - and were obviously devised by someone with little or no practical experience of writing database applications. Before switching to PHP with its OO capabilities I had spent the previous 20 years in writing enterprise applications which dealt with different database types - hierarchical, network and relational - which meant that I had plenty of experience of writing code to deal with a variety of different types of relationship. When developing my PHP framework I used that experience to develop a solution that was based around objects and which made use of as much reusable code as possible. In order to achieve this I deviated from the "approved" OO method, which advocates adding code to an entity's class to deal with any relationships which that class may have with other entities, and instead I built the necessary code into reusable framework components such as Controllers, Views and the abstract table class. The only code dealing with relationships that needs to exist in a table (Model) class are entries in either the $parent_relations or $child_relations arrays which are exported from the Data Dictionary into a table structure file. This reflects the fact that in a database the existence of a relationship is indicated by the existence of a foreign key in a child table which links to the primary key in the parent table. There are no special methods in the database to deal with any relationships, so there are no special methods in any of my table classes. This means that I can add and remove relationships without having to modify any table classes. All I have to do is build the necessary tasks using the relevant Transation Pattern.
More details regarding my approach can be found in the following:
I have been told on numerous occasions by other programmers that I am a bad boy simply because I don't follow the rules. This is incorrect for two reasons:
Below is a list of rules that I have been told that I should follow, and against each one I explain why I don't.
| Perceived Wisdom | Actual Wisdom | |
|---|---|---|
| 1 | Use OOD first to design your software structure, and leave the database design to last. | NO! Design the database first and create a separate class for each database table. This completely removes the need for OOD, and because it avoids the problem called Object-Relational Impedance Mismatch it also avoids the need to implement that abomination called an Object-Relational Mapper (ORM). |
| 2 | Use "is-a" relationships for to create class hieraechies. | NO! I never create class hierarchies where the top-most class is a concrete class, as explained in Using "IS-A" to identify class hierarchies. Instead I recognised that every object in my Business layer "is-a" database table, so I only ever inherit from an abstract class. |
| 3 | Use object associations to deal with relationships. | NO! This is explained in Object Associations. |
| 4 | Use "has-a" relationships to implement object composition. | NO! This is explained in Object Composition. |
| 5 | Use "has-a" relationships to implement object aggregation. | NO! This is explained in Object Aggregation. |
| 6 | Use lots of design patterns, the more the merrier! | NO! Design patterns do not provide reusable code, only reusable designs which still have to be coded by hand, and which can be implemented in an infinite variety of ways. I prefer to use Transaction Patterns which DO actually provide pre-written and reusable code. |
| 7 | Create each Model class by hand. | NO! Each class is created by the framework using information which is imported into the Data Dictionary direct from the database schema. Each database table requires two files:
Note that if the table's structure changes it can be re-imported into the Data Dictionary, and the export process will only overwrite the structure file so as not to interfere with any customisations which may exist in the class file. |
| 8 | Create each Controller by hand. | NO! Each Transaction Pattern has its own controller script which is built into the framework. |
| 9 | Create a single super-Controller for each Model which can handle all the use cases for that Model. | NO! Each use case has its own unique component script which shares one of my 40 controller scripts, but each Model can be used by any number of Controllers and Views. |
| 10 | Create each View by hand. | NO! Components are already built into the framework to format the application data into either HTML, PDF or CSV. All HTML output is produced from a library of 12 reusable XSL stylesheets. |
| 11 | Create a method in the class for each Use Case. | NO! In the real world each use case is actually satisfied by performing one or more operations (Create, Read, Update, Delete) on one or more database tables, so the User Transaction which implements a use case need do nothing more than specify which operations on which database tables. Methods such as invoice->pay() should therefore be implemented as payment->insertRecord(). |
| 12 | Create a separate finder method for each different set of data that you want the class to return, as shown in the Table Data Gateway and Row Data Gateway patterns. | NO! The SQL language does not require separate methods, it simply uses a SELECT ... WHERE ... which may be augmented with the addition of LIMIT ... OFFSET ... (or their equivalent). That is why my framework needs nothing more than a single generic getData($where) method which is defined in the abstract class. There are separate methods to set values for LIMIT and OFFSET. The other parts of the SELECT statement can be specified by custom code in each class. |
| 13 | A Controller can only ever access a single Model. | NO! An HTML screen can contain one or more areas (or zones) of application data, and each of these areas contains data from a specific database table. In order to use independent CRUD operations on each of these tables the Controller must be able to access each table class independently. |
| 14 | Each column in the table must have its own property in the class. | NO! Those who understand how relational databases and the Structured Query Language (SQL) works will know that they deal with rows or sets of data, and the number of columns which can be returned from a SELECT statement can be infinitely variable, especially when JOINS are used to connect to other tables. I find it much easier to use a single property called $fieldarray which can hold any number of columns from any number of rows in a plain PHP array. It is just as easy to reference a column using $this->fieldarray['column'] as it is with $this->column. |
| 15 | Each column in the table must have its own GETTER and SETTER methods. | NO! By using a single property called $fieldarray I can hold an infinite number of columns and an infinite number of rows in a single variable, a plain PHP array. All data comes into the Controller in a single variable, the $_POST array, and this array can be passed directly into the Model object, and subsequently the DAO, without having to unpack it. This eliminates the need to have code which specifies column names as the code would have to be different for each table. |
| 16 | Each column must be passed as a separate argument on any method call, as shown in Table Data Gateway. | NO! This would create tight coupling as any change in the number of columns in a table would cause a change to the method signature which in turn would affect any object using that signature. It would also prevent the passing in (or out) of any columns which did not actually exist in that table. |
| 17 | Each table object can only deal with a single row. | NO! Relational databases operate on data in rows, not individual columns, and the code inside a class can deal with multiple rows as well as multiple columns. Forcing each Model class to deal with a single row, as described in Row Data Gateway, would require extra code in the Controller to instantiate a separate instance for each row, and as a follower of the KISS principle I choose to implement the simplest solution, which happens to be the Table Data Gateway. |
| 18 | If data needs to be transferred from one object to another it must be done using a Data Transfer Object (DTO). | NO! A database query can return any number of rows, and these rows can be stored in a plain PHP array. This can be multi-dimensional in that the first level is indexed by row, and each row contains an associative array of name=value pairs. Arrays can be passed around just as easy as objects, and they require less overhead to create and populate. Even Martin Fowler does not think that this is a good idea, as explained in his article LocalDTO. |
| 19 | Model objects should only hold data, while all business logic should be handled by objects in a separate service layer. | NO! This is because my definition of a service is completely different. Logic which is specific to a particular entity should always be encapsulated in that entity's class. Only that logic which can be applied to any entity within the application is eligible for placement within a service. In my framework I have Models, Views, Controllers and Data Access Objects. Each Model encapsulates the business rules for a single database table. All the Views, Controllers and Data Access Objects are services because they can execute their logic on any Model. |
| 20 | Use an Object Relational Mapper (ORM). | NO! This is supposed to be a cure for the problem called Object-relational impedance mismatch which is caused by having the in-memory structure of an application completely out of sync with the actual database structure. Instead of masking the symptoms of the problem I prefer to eliminate the problem altogether by removing the mismatch. By designing the database first, then ignoring OOD and creating a separate class for each database table the problem simply goes away, which means that I don't need that abomination of a solution. |
| 21 | Objects should not be aware of the database structure. | NO! Some part of the code somewhere MUST have knowledge of the database structure otherwise it would be physically impossible to construct the SQL queries which move data in and out of that structure. These queries must contain actual table and column names, and must contain values which conform to each column's data type.
In my framework, which consists of Models, Views, Controllers and Data Access Objects, the only logical place is within the Models as these are the only components which are allowed to have knowledge of the application. All Views, Controllers and DAOs are application-agnostic sharable services which are built into the framework. All data validation, which verifies that the user-supplied value for a column matches that column's specifications, is performed within the Model, so it follows that the Model must have a list of column names and their specifications. |
Considering that the principle objective of OOP is take advantage of Encapsulation, Inheritance and Polymorphism to increase code reuse and decrease code maintenance
then I can clearly demonstrate that I have achieved that objective. My framework's architecture is comprised of Models, Views, Controllers and Data Access Objects (DAO) which have the following characteristics:
Using my framework I can create a table in the database, generate the table class, then generate and run a family of forms to maintain that database table without having to write a single line of code - no PHP, no HTML no SQL. Unless you can match that level of productivity I suggest you re-examine and refactor your own methodology.
In 2004 this post identified a study that broke down an application's code into several basic categories - business logic, glue code, user interface code and database code - and highlighted the fact that it is only business logic which has any real value to the company. It compared the productivity of two different teams and found that the team which spends less time writing glue code, user interface code and database code can spend more time writing the "value" code and therefore be more productive. My framework follows this idea simply because it maximises the amount of time that developers spend on the important business logic.
Now ask yourself a simple question - if I can break all of those "rules" and still produce cost-effective software then do those rules have any actual value? Not only does breaking those rules not have a detrimental effect, I submit that my implementation has a beneficial effect because I can produce effective software quicker and therefore cheaper. Producing cost-effective software is the name of the game, not following a set of artificial and arbitrary rules.
Here endeth the lesson. Don't applaud, just throw money.
#1: I have been told that my abstract class must surely be breaking the Single Responsibility Principle for no reason other than it has 9000+ lines of code and 120+ methods. Different people suggest different maximum values. If you read When is a class too big? you will see such values as 7, 10, 20 or more being quoted as the limit. The paper titled A large-scale empirical study of practitioners' use of object-oriented concepts suggests other values.
If you actually read the Single Responsibility Principle you will see that it advocates the separation of User Interface logic, Business logic and Data Access logic which is precisely what I have done by virtue of the fact that I have implemented a mixture of the 3-Tier Architecture and the Model-View-Controller design pattern. My abstract table class does not contain any UI logic, Controller logic or Data Access logic, so I cannot see any justification for saying that it "breaks" SRP.
I was asked to explain what that class does in no more than 20 words and my reply was:
It is an abstract class that contains methods for any operation that can be performed on any database table. (that's 19 words)
Each concrete class identifies exactly which database table is being accessed as well as containing methods which supplement or replace the default behaviour.
Each concrete class is responsible for the business rules associated with a single database table, so why does that not follow the Single Responsibility Principle?
The following articles describe aspects of my framework:
The following articles express my heretical views on the topic of OOP:
These are reasons why I consider some ideas on how to do OOP "properly" to be complete rubbish:
These are reasons why I consider some ideas on how to do OOP "properly" to be complete rubbish:
Here are my views on changes to the PHP language and Backwards Compatibility:
The following are responses to criticisms of my methods:
Here are some miscellaneous articles: