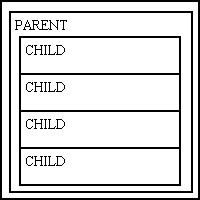
Figure 1 - The MVC and 3-Tier architectures combined
")
Abstraction is supposed to be an important part of OOP, but what exactly does it mean? What is it, and how is it implemented? This has confused me, and many others, for a long time as wherever I look I seem to find a different definition, such as the following which I found by searching the internet:
- The process of removing or generalizing physical, spatial, or temporal details or attributes in the study of objects or systems to focus attention on details of greater importance; it is similar in nature to the process of generalization;
- the creation of abstract concept-objects by mirroring common features or attributes of various non-abstract [concrete] objects or systems of study - the result of the process of abstraction.
- the process of reorganizing common behavior from non-abstract [concrete] classes into "abstract classes" using inheritance to abstract over sub-classes as seen in the object-oriented C++ and Java programming languages.
Note that in the above I have inserted the word "[concrete]" to indicate where it is normally used instead of the term "non-abstract".
Each significant piece of functionality in a program should be implemented in just one place in the source code. Where similar functions are carried out by distinct pieces of code, it is generally beneficial to combine them into one by abstracting out the varying parts.
Computer scientists use abstraction to make models that can be used and re-used without having to re-write all the program code for each new application
Both of the above would seem to be echoing the Don't Repeat Yourself (DRY) principle.
Here are some more dubious descriptions:
The first pillar of OOP is "Abstraction". "Abstraction is the process of selecting data to show only the relevant information to the user".
Abstraction is the concept of object-oriented programming that "shows" only essential attributes and "hides" unnecessary information. The main purpose of abstraction is hiding the unnecessary details from the users. Abstraction is selecting data from a larger pool to show only relevant details of the object to the user.
Through the process of abstraction, a programmer hides all but the relevant data about an object in order to reduce complexity and increase efficiency.
Abstraction is the process of hiding the internal details of an application from the outer world. Abstraction is used to describe things in simple terms. It's used to create a boundary between the application and the client programs.
In object oriented programming, abstraction involves exposing necessary functionality to external objects and hiding implementation details.
Abstraction means displaying only essential information and hiding the details. Data abstraction refers to providing only essential information about the data to the outside world, hiding the background details or implementation.
An abstraction is a way of hiding the implementation details and showing only the functionality to the users. In other words, it ignores the irrelevant details and shows only the required one.
Abstraction is the process of taking away or removing characteristics from something in order to reduce it to a set of essential characteristics.
in Object-oriented programming, abstraction is a process of hiding the implementation details from the user, only the functionality will be provided to the user. In other words, the user will have the information on what the object does instead of how it does it.
In Object Oriented Programming abstraction concept the actual implementation is hidden from the user and only required functionality will be accessible or available to the user.
Abstraction in oops simplifies how we interact with software systems by focusing on their essential features while hiding unnecessary details.
Abstraction can be defined as hiding internal implementation and showing only the required features or set of services that are offered.
Abstraction is the concept of wrapping up complex actions in simple verbs. Describe each thing you've abstracted clearly, and hide the complexity.
Often, it's easier to reason and design a program when you can separate the interface of a class from its implementation, and focus on the interface. This is akin to treating a system as a "black box," where it's not important to understand the gory inner workings in order to reap the benefits of using it.
Abstraction is an extension of encapsulation. It is the process of selecting data from a larger pool to show only the relevant details to the object.
Abstraction is a technique of providing only the essential details to the user by hiding the unnecessary or irrelevant details of an entity. This helps in reducing the operational complexity at the user-end.
Abstraction of Data or Hiding of Information is called Abstraction! or in other words, what are those things that a user is concerned about.
Abstraction is the process of showing only essential/necessary features of an entity/object to the outside world and hide the other irrelevant information.
Abstraction is a process of hiding the implementation details and showing only functionality to the user. It only shows essential things to the user and hides the internal details. Abstraction lets you focus on what the object does instead of how it does it.
Code abstraction is the process of hiding the implementation details of a piece of code behind an interface - i.e. the details of how something works are hidden away, leaving us to deal only with what it does. This allows developers to work with the code at a higher level of abstraction, without needing to understand fully (or keep in mind) all the underlying details and thereby reducing the cognitive load when programming.
I found some more definitions in Abstraction, Encapsulation, and Information Hiding by Edward V. Berard of The Object Agency:
A view of a problem that extracts the essential information relevant to a particular purpose and ignores the remainder of the information.
The essence of abstraction is to extract essential properties while omitting inessential details.
Abstraction is a process whereby we identify the important aspects of a phenomenon and ignore its details.
Abstraction is generally defined as 'the process of formulating generalised concepts by extracting common qualities from specific examples.'
Abstraction is the selective examination of certain aspects of a problem. The goal of abstraction is to isolate those aspects that are important for some purpose and suppress those aspects that are unimportant.
The meaning [of abstraction] given by the Oxford English Dictionary (OED) closest to the meaning intended here is 'The act of separating in thought'. A better definition might be 'Representing the essential features of something without including background or inessential detail.'
[A] simplified description, or specification, of a system that emphasizes some of the system's details or properties while suppressing others. A good abstraction is one that emphasizes details that are significant to the reader or user and suppress details that are, at least for the moment, immaterial or diversionary.
An abstraction denotes the essential characteristics of an object that distinguish it from all other kinds of object and thus provide crisply defined conceptual boundaries, relative to the perspective of the viewer.
A large number of the above links describe abstraction as separating what can be hidden from what can be left visible. This is wrong. They seem to be based on the word abstract (noun) which means a short form of a speech, article, book, etc., giving only the most important facts or ideas
, which has synonyms such as: summary, synopsis, precis, outline and digest. An abstract is produced from a single document in order to provide a shorter version whereas in computer science an abstraction is produced from a group of objects in order to identify the similarities so that they can be separated from the differences.
You can find even more misleading descriptions if you read What an abstraction is not where you will see, when associated with computer programming, the term has been twisted to mean "separating what data can be hidden from that which should be visible" instead of "separating the abstract from the concrete".
So many different definitions, so many different descriptions, but they still fail to answer the basic question "How do I apply this concept called abstraction when designing a computer system, and what are the results?" To muddy the waters even more Edward V. Berard makes this observation:
One point of confusion regarding abstraction is its use as both a process and an entity. Abstraction, as a process, denotes the extracting of the essential details about an item, or a group of items, while ignoring the inessential details. Abstraction, as an entity, denotes a model, a view, or some other focused representation for an actual item. Abstraction is most often used as a complexity mastering technique. For example, we often hear people say such things as: "just give me the highlights" or "just the facts, please." What these people are asking for are abstractions.
We can have varying degrees of abstraction, although these "degrees" are more commonly referred to as "levels." As we move to higher levels of abstraction, we focus on the larger and more important pieces of information (using our chosen selection criteria). Another common observation is that as we move to higher levels of abstraction, we tend to concern ourselves with progressively smaller volumes of information, and fewer overall items. As we move to lower levels of abstraction, we reveal more detail, typically encounter more individual items, and increase the volume of information with which we must deal.
We also note that there are many different types of abstraction, e.g., functional abstraction, data abstraction, process abstraction, and even object abstraction.
How can novice programmers become masters of the art of abstraction if even the current set of so-called "masters" cannot describe it in a consistent and unambiguous manner?
In the above list of random definitions you will see the following:
Abstraction is a technique of providing only the essential details to the user by hiding the unnecessary or irrelevant details of an entity. This helps in reducing the operational complexity at the user-end.
Abstraction of Data or Hiding of Information is called Abstraction! or in other words, what are those things that a user is concerned about.
Abstraction is the process of showing only essential/necessary features of an entity/object to the outside world and hide the other irrelevant information.
Abstraction is a process of hiding the implementation details and showing only functionality to the user. It only shows essential things to the user and hides the internal details. Abstraction lets you focus on what the object does instead of how it does it.
Abstraction can be defined as hiding internal implementation and showing only the required features or set of services that are offered.
Code abstraction is the process of hiding the implementation details of a piece of code behind an interface.
I have seen it written many times that encapsulation and abstraction mean exactly the same thing, that they are both concerned with data hiding or information hiding. This is absolute nonsense as neither is concerned with data hiding. Encapsulation means enclosing an entity's data and the operations which can be performed on that data in a capsule called a "class". While it is obvious that the internals of every object's method are hidden from view, just as they are in procedural functions, the idea of hiding the data seems nonsensical as you must have a mechanism to put the data in and get it out afterwards. Abstraction is about examining several classes looking for similarities and differences so that the similarities can be placed in a reusable module (such as an abstract class) and all the differences placed in a unique module (such as a concrete subclass). All the similar protocols are then shared via inheritance. Each concrete class need only contain those things which make it different from other concrete classes.
Encapsulation, abstraction and data hiding are three separate concepts, not the same concept.
You can perform an abstraction and the result will be an abstraction, meaning that it is both a verb/process and a noun/entity. So when authors write about "abstraction" which type do they mean? On top of that there are also different types of abstraction, which potentially leads to even more confusion. To muddy the waters even more the only reference in the programming language which includes the word "abstract" is to denote a type of class, one that cannot be instantiated into an object. So if there are different types of abstraction and different types of class, which type of abstraction produces which type of class? Confused? I know I was. Things started to become clearer when I came across the following statements in in a paper called Designing Reusable Classes which was published in 1988 by Ralph Johnson and Brian Foote, but which I only discovered quite recently. While this was published 35 years ago with just the Smalltalk language in mind, the basic concepts are still relevant in many of today's Object Oriented languages.
Introduction
The first section of the paper describes the attributes of object-oriented languages that promote reusable software. Data abstraction encourages modular systems that are easy to understand. Inheritance allows subclasses to share methods defined in superclasses, and permits programming-by-difference. Polymorphism makes it easier for a given component to work correctly in a wide range of new contexts. The combination of these features makes the design of object-oriented systems quite different from that of conventional systems.
Protocol
The specification of an object is given by its protocol, i.e. the set of messages that can be sent to it.
...
Objects with identical protocol are interchangeable. Thus, the interface between objects is defined by the protocols that they expect each other to understand. If several classes define the same protocol then objects in those classes are "plug compatible".
...
Standard protocols are given their power by polymorphism.
Inheritance
Most object-oriented programming languages have another feature that differentiates them from other data abstraction languages; class inheritance. Each class has a superclass from which it inherits operations and internal structure. A class can add to the operations it inherits or can redefine inherited operations. However, classes cannot delete inherited operations.
Class inheritance has a number of advantages. One is that it promotes code reuse, since code shared by several classes can be placed in their common superclass, and new classes can start off having code available by being given a superclass with that code. Class inheritance supports a style of programming called programming-by-difference, where the programmer defines a new class by picking a closely related class as its superclass and describing the differences between the old and new classes. Class inheritance also provides a way to organize and classify classes, since classes with the same superclass are usually closely related.
One of the important benefits of class inheritance is that it encourages the development of the standard protocols that were earlier described as making polymorphism so useful. All the subclasses of a particular class inherit its operations, so they all share its protocol. Thus, when a programmer uses programming-by-difference to rapidly build classes, a family of classes with a standard protocol results automatically. Thus, class inheritance not only supports software reuse by programming-by-difference, it also helps develop standard protocols.
Abstract Classes
Standard protocols are often represented by abstract classes [Goldberg & Robson 1983].
An abstract class never has instances, only its subclasses have instances. The roots of class hierarchies are usually abstract classes, while the leaf classes are never abstract. Abstract classes usually do not define any instance variables. However, they define methods in terms of a few undefined methods that must be implemented by the subclasses.
...
A class that is not abstract is concrete. In general, it is better to inherit from an abstract class than from a concrete class. A concrete class must provide a definition for its data representation, and some subclasses will need a different representation. Since an abstract class does not have to provide a data representation, future subclasses can use any representation without fear of conflicting with the one that they inherited.
After reading this I could eventually see the light at the end of the tunnel. Out of all the previous definitions of abstraction the only ones which were a close match were:
Thought of or stated without reference to a specific instance. Separated from matter, practice, or particular examples; not concrete.
The act of comparing commonality between distinct objects and organizing using those similarities; the act of generalizing characteristics; the product of said generalization.
Each significant piece of functionality in a program should be implemented in just one place in the source code. Where similar functions are carried out by distinct pieces of code, it is generally beneficial to combine them into one by abstracting out the varying parts.
So the aim of abstraction is to separate out the abstract from the concrete from a group of objects where the abstract identifies the similarities, the fixed parts, and the concrete identifies the differences, the varying parts. This concept, called programming-by-difference, means that you look at several entities which are of interest to your application and separate out the similarities from the differences. You are looking for patterns which repeat so that when you want to reuse that pattern you can invoke a central definition of that pattern instead of writing a fresh copy each time. Creating multiple copies of something violates the DRY principle. When you create an abstraction you are creating a master copy of something that can be reused multiple times.
Performing an abstraction it not something you can do in your code, only in your mind. You must then use your programming skills to implement that abstraction in your code.
This means that you cannot perform an abstraction before you start creating entities, or by looking at a single entity, you must create several and then examine them. You look at the data for these entities as well as the operations that can be performed on their data. If the data representations (properties) are different but the protocols (methods) are the same then you can put the similarities in an abstract superclass and the differences in separate concrete subclasses. While each concrete class has its own data representation an abstract class does not. The abstract class may contain placeholders for data and/or metadata, but these placeholders are not populated until a concrete class is instantiated into an object and methods are called to insert data. Any shared protocols (ie: operations or methods) can be defined in the abstract class and may use the contents of these placeholders. Application data can be inserted into an object either by being pushed from a calling object or pulled from a dependent object.
Experiences programmers should understand immediately the significance of these statements which appeared under the heading Protocol above:
Objects with identical protocol are interchangeable.
If several classes define the same protocol then objects in those classes are "plug compatible".
Standard protocols are given their power by polymorphism.
To the uninitiated it means that the more polymorphism you have then the more you can employ the technique which is now known as Dependency Injection. For example, in an enterprise application every entity will require a service to transform its data into a format required by the user, such as HTML, CSV or PDF. It is possible to create a single service object for each of these formats so that it can perform its function on any entity that is injected into it. Having a single service object that can perform its function on any entity is obviously far better than creating a separate service object for each individual entity.
While all the standard protocols/methods can be defined in the abstract class, how do you deal with any non-standard methods which are unique to particular subclasses? You implement the Template Method Pattern, of course. Any programmer who has read Design Patterns: Elements of Reusable Object-Oriented Software by the Gang of Four (GoF) should know that.
It then became clear to me that the practices which I had adopted instinctively and intuitively when I began to develop my framework were completely in tune with the concept of programming-by-difference. These practices are discussed in the following sections:
The word "entity" is used several times in the statements above, so in order to avid any confusion I would like to explain what this means in terms of OO programming. In his article How to write testable code the author identifies three distinct categories of object:
| Entities | An object whose job is to hold state and associated behavior. The state (data) can be persisted to and retrieved from a database. Examples of this might be Account, Product or User. In my framework each database table has its own Model class. |
| Services | An object which performs an operation. It encapsulates an activity but has no encapsulated state (that is, it is stateless). Examples of Services could include a parser, an authenticator, a validator or a transformer (such as transforming raw data into HTML, CSV or PDF). In my framework all Controllers, Views and DAOs are services. |
| Value objects | An immutable object whose responsibility is mainly holding state but may have some behavior. Examples of Value Objects might be Color, Temperature, Price and Size. PHP does not support value objects, so I do not use them. I have written more on the topic in Value objects are worthless. |
Note also that entities contain business rules while services do not. When an entity represents a table in a database that entity should contain all the business rules concerning that table. A service should not contain any business rules as it should be able to perform its function on any entity within the system. No service should ever be tightly coupled to a single entity.
This is also discussed in When to inject: the distinction between newables and injectables.
The PHP language does not have value objects, so I ignore them. My framework does not deal with anything other than entities and services, so anything else is totally irrelevant and a complete waste of time.
These entities should appear as objects in the business/domain layer of your application, otherwise known as Models in the Model-View-Controller (MVC) design pattern. These form the heart of the application as they contain all the business rules and other information. The remaining objects - the Controllers, Views and Data Access Objects - should not have any knowledge of the application and can be regarded as being nothing but services which should be able to operate on any entity. As such they can be pre-built and supplied as part of the framework as they should be able to perform whatever service they provide on any object in the business/domain layer.
It should be understood by every developer that when you are creating a database application you will not be writing software which communicates with objects in the real world, you will only be communicating with their representations in a database, and those representations are known as tables. That is why you should follow my lead and create a separate class for each database table. This follows the principle of Information Expert (GRASP) in which it states that you should Assign responsibility to the class that has the information needed to fulfill it
. I interpret "responsibility" to mean code and "information" to mean data, so because each database table is responsible for a different set of data it follows that I should have a separate class to control access to that data, and that class should also contain all the methods which can act upon that data.
While some real world objects may result in a collection of tables (such as those shown in Object Aggregations) which are joined in a network of relationships, in a database each table is a separate entity in its own right which has its own data structure and which is subject to the same CRUD operations as every other table. By creating a separate class for each individual table you will be creating classes with identical protocols which then maximises the possibility of reusing those protocols using the mechanism of polymorphism.
If you ever follow the teachings of others and create classes which are responsible for more than one database table, such as to deal with object aggregation which involve several tables, you will then find it necessary to create unique methods to access each of those tables, and by creating unique methods instead of sharing common ones you immediately kiss goodbye to those benefits which are provided by polymorphism, the most useful being dependency injection.
It would also be advisable to avoid the temptation to create Anemic Domain Models which contain data but no processing. This goes against the whole idea of OO which is to create objects which contain both data and processing. If you put the state and behaviour in separate classes then you are violating the principle of encapsulation.
Before you can start creating classes you have to identify those objects/entities which will be relevant to your application, then you can create classes for those entities. My previous experience with database applications made me aware of the following common characteristics:
Smart data structures and dumb code works a lot better than the other way around.
Every database table, regardless of the fact that it deals with different data, has a structure which follows the same set of rules:
In a large ERP application, such as the GM-X Application Suite, which is comprised on a number of subsystems, each subsystem has a unique set of attributes:
Despite the fact that these two areas are completely different for each subsystem, they each have their own patterns and so can be handled using standard reusable code provided by the framework:
Why do I have a separate class for each table? Because it matches this definition of a class:
A class is a blueprint, or prototype, that defines the variables and the methods common to all objects (entities) of a certain kind. A class represents a common abstraction of a set of entities, suppressing their differences.
The DDL script is the "blueprint" for each row in that table, so I use that blueprint to create a class which will be used to manipulate that data.
The contents of a database table are manipulated using the DML language, so I provide methods which utilise this language.
After having produced a list of classes for each entity (database table) in the business domain the next step is to look for similarities and differences in the operations that can be performed on those entities. I have already determined that I am not writing an application which communicates with objects in the real world, only the data which is held on those objects in the database, so I am not interested in the operations which are available in those real world objects, only those which are available in the database. A real-world product such as a ride-on lawn mower may have operations such as "switch engine on", "switch engine off", "start moving", "stop moving", "turn left", "turn right", "raise blades" and "lower blades", but these are completely irrelevant in a Sales Order Processing (SOP) system. A person/customer may have operations such as "stand", "sit", "walk", "run", "eat", "sleep" and "defecate", but these are completely irrelevant in a Sales Order Processing (SOP) system.
Regardless of the fact that entities such as products and customers in the real world are as different as chalk and cheese, a Sales Order Processing (SOP) system does not interact with those entities directly, it interacts with nothing but information about those entities, and that information is stored in a database as columns of data arranged into tables. Regardless of how many different tables I have, and how many different columns I have in each table and how different the data is in each of those columns, the only operations that can be performed on a database table are Create, Read, Update and Delete (CRUD). So just as I use the DDL language to define the structure of each domain object (table) I use the DML language to define the operations that can be performed on each of those objects.
| Operation | Code |
|---|---|
| Create |
INSERT INTO <tablename> (column1, column2, column3) VALUES ('value1', 'value2', 'value3');
|
| Read | simple: SELECT * FROM <tablename> [WHERE <condition>] advanced: SELECT <select list> FROM <tablename> [JOIN <tablename2> ON (...)] [WHERE <condition>] [GROUP BY ...] [HAVING ...] [ORDER BY ...] [LIMIT ... OFFSET ...] |
| Update | UPDATE <tablename> SET column1='value1', column2='value2', column3='value3' WHERE <condition> |
| Delete | DELETE FROM <tablename> WHERE <condition> |
Note that the Create, Update and Delete operations function on only one table at a time whereas the Read operation can obtain data from several tables using an SQL JOIN.
As these four operations are common to every database table they are prime candidates for being moved into an abstract class from which they can be inherited, thus removing large amounts of boilerplate code that would otherwise be duplicated. These operations can be provided by the methods shown below in Common Table Methods where methods called externally identifies the public methods which then act as wrappers for the methods called internally.
| Methods called externally | Methods called internally | UML diagram |
|---|---|---|
| $object->insertRecord($_POST) | $fieldarray = $this->pre_insertRecord($fieldarray); if (empty($this->errors) { $fieldarray = $this->validateInsert($fieldarray); } if (empty($this->errors) { $fieldarray = $this->commonValidation($fieldarray); } if (empty($this->errors) { $fieldarray = $this->dml_insertRecord($fieldarray); $fieldarray = $this->post_insertRecord($fieldarray); } |
ADD1 Pattern |
| $object->updateRecord($_POST) | $fieldarray = $this->pre_updateRecord(fieldarray); if (empty($this->errors) { $fieldarray = $this->validateUpdate($fieldarray); } if (empty($this->errors) { $fieldarray = $this->commonValidation($fieldarray); } if (empty($this->errors) { $fieldarray = $this->dml_updateRecord($fieldarray); $fieldarray = $this->post_updateRecord($fieldarray); } |
UPDATE1 Pattern |
| $object->deleteRecord($_POST) | $fieldarray = $this->pre_deleteRecord(fieldarray); if (empty($this->errors) { $fieldarray = $this->validateDelete($fieldarray); } if (empty($this->errors) { $fieldarray = $this->dml_deleteRecord($fieldarray); $fieldarray = $this->post_deleteRecord($fieldarray); } |
DELETE1 Pattern |
| $object->getData($where) | $where = $this->pre_getData($where); $fieldarray = $this->dml_getData($where); $fieldarray = $this->post_getData($fieldarray); |
ENQUIRE1 Pattern |
Here the methods called externally are the ones which are called from external modules, such as a Controller, while the methods called internally are called only from within the abstract class. Because this abstract class is inherited by every Model it means that these methods are available within every Model, thus producing polymorphism. Each external method then acts as a wrapper for a group of internal methods. You can visualise the full picture by looking at the specified UML diagrams.
You should see here that I have different versions of the validate() and store() methods depending on which operation is being performed as the logic is entirely different in each case. Notice also that I have a single getData() method for reading from the database rather than a collection of different finder methods simply because SQL does not have different finder methods, just a single SELECT query which can retrieve any number of records simply by varying the contents of the WHERE string.
In order to cater for the possibility that some concrete subclasses may require additional or non-standard processing then the use of an abstract superclass allows the Template Method Pattern to be employed so that any non-standard processing can be added to "hook" methods within each concrete subclass. These methods have prefixes such as "pre_" (before) and "post_" (after).
If functional abstraction identifies protocols/methods which can be shared, then data abstraction should identify variables/properties which can be shared. These can all be shared by being inherited from an abstract class. In the case of a database application with a separate class for each table, each of those tables has its own unique structure with its own set of column names, so what data can possibly be shared? The answer is to look for that data which every table has but which is not application data. This is called Metadata and can be found in the INFORMATION_SCHEMA which is provided by each DBMS.
In the description of abstract classes by Johnson and Foote it says Abstract classes usually do not define any instance variables
. The term "usually" means to me that this is an option which may or may not be implemented at the developer's discretion. There is no rule that says Abstract classes must not define instance variables
. I have found that I can define placeholders for common pieces of metadata in the abstract class and fill these placeholders with actual data within each concrete subclass when it is instantiated into an object. These placeholders are as follows:
| $this->dbname | This value is defined in the class constructor. This allows the application to access tables in more than one database. It is standard practice in the RADICORE framework to have a separate database for each subsystem. |
| $this->tablename | This value is defined in the class constructor. |
| $this->fieldspec | The identifies the columns (fields) which exist in this table and their specifications (type, size, etc). |
| $this->primary_key | This identifies the column(s) which form the primary key. Note that this may be a compound key with more than one column. Although some modern databases allow it, it is standard practice within the RADICORE framework to disallow changes to the primary key. This is why surrogate or technical keys were invented. |
| $this->unique_keys | A table may have zero or more additional unique keys. These are also known as candidate keys as they could be considered as candidates for the role of primary key. Unlike the primary key these candidate keys may contain nullable columns and their values may be changed at runtime. |
| $this->parent_relations | This has a separate entry for each table which is the parent in a parent-child relationship with this table. This also maps foreign keys on this table to the primary key of the parent table. This array can have zero or more entries. |
| $this->child_relations | This has a separate entry for each table which is the child in a parent-child relationship with this table. This also maps the primary key on this table to the foreign key of the child table. This array can have zero or more entries. |
| $this->fieldarray | This holds all application data, usually the contents of the $_POST array. It can either be an associative array for a single row or an indexed array of associative arrays for multiple rows. This removes the restriction of only being able to deal with one row at a time, and only being able to deal with the columns for a single table. This also avoids the need to have separate getters and setters for each individual column as this would promote tight coupling which is supposed to be a Bad Thing ™. |
In the RADICORE framework this metadata is not hard-coded into each table class, nor is it extracted from the database and loaded into the object when it is instantiated. I have a separate subsystem called a Data Dictionary which I use to extract the data just once and then export it to produce a table structure file in the file system, along with the default table class file.
Note that when taking an entity's data and converting it into a database table, the process of Data Normalisation may force that data to be spread across several related tables. The identity of these relationships will be held in the $parent_relations property for the child table, and the $child_relations property for the parent table. I do not have code within any concrete class to deal with any relationships as this is handled by standard code which is built into the framework. I do not have classes which are responsible for groups of tables, known as aggregate objects, as I believe it would violate the Single Responsibility Principle.
In the section on Inheritance vs. decomposition the article states the following:
Since inheritance is so powerful, it is often overused. Frequently a class is made a subclass of another when it should have had an instance variable of that class as a component. For example, some object-oriented user-interface systems make windows be a subclass of Rectangle, since they are rectangular in shape. However, it makes more sense to make the rectangle be an instance variable of the window. Windows are not necessarily rectangular, rectangles are better thought of as geometric values whose state cannot be changed, and operations like moving make more sense on a window than on a rectangle.
Behavior can be easier to reuse as a component than by inheriting it. There are at least two good examples of this in Smalltalk-80. The first is that a parser inherits the behavior of the lexical analyzer instead of having it as a component. This caused problems when we wanted to place a filter between the lexical analyzer and the parser without changing the standard compiler. The second example is that scrolling is an inherited characteristic, so it is difficult to convert a class with vertical scrolling into one with no scrolling or with both horizontal and vertical scrolling. While multiple inheritance might solve this problem, it has problems of its own. Moreover, this problem is easy to solve by making scrollbars be components of objects that need to be scrolled.
Most object-oriented applications have many kinds of hierarchies. In addition to class inheritance hierarchies, they usually have instance hierarchies made up of regular objects. For example, a user-interface in Smalltalk consists of a tree of views, with each subview being a child of its superview. Each component is an instance of a subclass of View, but the root of the tree of views is an instance of StandardSystemView. As another example, the Smalltalk compiler produces parse trees that are hierarchies of parse nodes. Although each node is an instance of a subclass of ParseNode, the root of the parse tree is an instance of MethodNode, which is a particular subclass. Thus, while View and ParseNode are the abstract classes at the top of the class hierarchy, the objects at the top of the instance hierarchy are instances of StandardSystemView and MethodNode.
This distinction seems to confuse many new Smalltalk programmers. There is often a phase when a student tries to make the class of the node at the top of the instance hierarchy be at the top of the class hierarchy. Once the disease is diagnosed, it can be easily cured by explaining the differences between the instance and class hierarchies.
The first statement Since inheritance is so powerful, it is often overused.
tells me that some people implement an idea indiscriminately instead of intelligently. They do not understand when the use of an idea is appropriate and when it is not. I'm afraid there is no cure for this disease. You either have the ability to think, or you don't. Those people whose thought processes are sub-optimal will end up as being nothing more than Cargo Cult programmers. Instead of becoming rock star programmers they will never become anything more than rocks-in-the-head programmers.
The second statement Behavior can be easier to reuse as a component than by inheriting it
is misleading as it totally depends on the nature of that behaviour. If it is common to all entities then it is a candidate for being placed in an abstract class which is then inherited by those entities. Note that I never inherit from a concrete class to create a new concrete class, I always inherit from an abstract class. If the behaviour belongs in a service object which is called to perform its service on an entity's data then it is a candidate for being placed in a reusable library so that it can be loaded and called as and when necessary. Once the shared behaviour has been placed in its own method it should be a relatively simple process to move that method between the abstract class and a service object.
The statement about scrolling being an inherited characteristic
is completely wrong when talking about a web application as it does not require any logic in any table class. Scrolling and pagination originate as controls in the HTML screen which are constructed within the View object and give the user the opportunity to move either forwards or backwards through the current record set. When the user activates one of these controls this results in a fresh HTTP request being sent to the server. This is received by the Controller which sets the $pageno or $rowsperpage variables in the Model before it calls the getData() method on that Model. This does absolutely nothing with these variables except pass them straight through to the DAO which creates and executes a SELECT statement which includes those variables. There is no processing required in any Model class as this is split across the Controller, View and DAO. This means that there is no processing to inherit in the Model class. There is also nothing to inherit in the View as it is a single concrete class which has no need for any inheritance at all.
The remainder of the section in the above article is totally irrelevant when it comes to programming with PHP. It is talking about using a compiled language which is communicating with a bit-mapped display in which a copy of the GUI is held in memory, and changes to any part of this memory would result in a corresponding change in the visible display. PHP does not use a bit-mapped display and it does not respond to mouse movements, it constructs an HTML document which is sent to the client's web browser after which the PHP script dies. There is no further interaction with the web page until the user either presses a SUBMIT button which results in a new POST request, or presses a hyperlink which results in a new GET request. A web page is not an object which is comprised of other objects which can be read from or written to in isolation, so it has no instance hierarchies. An HTML document is just a huge string of text containing values which are enclosed in HTML tags. In order to change the display a fresh copy of the entire HTML document has to be constructed and returned to the client's browser. I don't have to waste time developing hierarchies of classes to deal with the different parts of a web page as every page can be built using a single View object which is discussed further in Reusable Views.
Instance hierarchies have no place in a database application for the simple reason that a database does not have hierarchies of objects. It does not have object associations which are processed by custom methods within the Model, it has relationships which are processed by standard components in the framework. There is no such thing as a table being a container for other tables. There may be logical hierarchies of tables, as identified by foreign keys, but it is up to the software to handle these relationships in a user-friendly way. Each table is an independent object which can be addressed directly without the necessity of going through another table. While an ERD diagram may show several tables in what appears to be a hierarchy, they do not constitute a composite object in the database so should not be developed as a composite object in the software. Relationships between tables have no effect on the way that the tables are accessed, they are always accessed using the same CRUD operations whether or not they are related to other tables. I do not have methods within each table class to deal with any relationships, instead I have different framework components to deal with different types of relationship.
The article has this to say about frameworks:
One of the most important kinds of reuse is reuse of designs. A collection of abstract classes can be used to express an abstract design. The design of a program is usually described in terms of the program's components and the way they interact.
An object-oriented abstract design, also called a framework, consists of an abstract class for each major component. The interfaces between the components of the design are defined in terms of sets of messages. There will usually be a library of subclasses that can be used as components in the design.
Here I disagree slightly. In my framework the major components are Models, Views, Controllers and Data Access Objects, but I only have an abstract class for the Model components as these are the only components that are generated by the developer. All the others are pre-written objects which are supplied in the framework.
Frameworks are more than well written class libraries.
...
A framework, on the other hand, is an abstract design for a particular kind of application, and usually consists of a number of classes. These classes can be taken from a class library, or can be application-specific.
The kind of application for which RADICORE was created is one which accesses a relational database through a web browser. It has been used to create a ERP application with 20 subsystems (each with its own database), 400+ database tables and 4,000+ HTML screens.
Frameworks provide a way of reusing code that is resistant to more conventional reuse attempts. Application independent components can be reused rather easily, but reusing the edifice that ties the components together is usually possible only by copying and editing it. Unlike skeleton programs, which is the conventional approach to reusing this kind of code, frameworks make it easy to ensure the consistency of all components under changing requirements.
The framework provides components which can be useful to any subsystem, such as the following:
All user transactions are generated from a library of Transaction Patterns which utilise pre-defined Controllers and Views in conjunction with any of the generated Models.
Since frameworks provide for reuse at the largest granularity, it is no surprise that a good framework is more difficult to design than a good abstract class. Frameworks tend to be application specific, to interlock with other frameworks by sharing abstract classes, and to contain some abstract classes that are specialized for the framework. Designing a framework requires a great deal of experience and experimentation, just like designing its component abstract classes.
In the case of the RADICORE framework the particular kind of application
is that of a web-based database application. While some people consider that applications such as Invoicing and Inventory cover separate business domains and therefore require separate designs, I do not. It does not matter that each "application domain" requires a totally different set of database tables, totally different business rules and totally different tasks (user transactions), as each of those is handled in exactly the same way. The RADICORE framework is a system for creating and then running database applications which itself is comprised of 4 subsystems - Menu, Audit, Workflow and Data Dictionary. Applications such as Order Processing, Invoicing, Shipments and Inventory are nothing more than additional subsystems which can be added in at random intervals.
White-box vs. Black-box Frameworks
One important characteristic of a framework is that the methods defined by the user to tailor the framework will often be called from within the framework itself, rather than from the user's application code. The framework often plays the role of the main program in coordinating and sequencing application activity. This inversion of control gives frameworks the power to serve as extensible skeletons. The methods supplied by the user tailor the generic algorithms defined in the framework for a particular application.
A framework's application specific behavior is usually defined by adding methods to subclasses of one or more of its classes. Each method added to a subclass must abide by the internal conventions of its superclasses. We call these white-box frameworks because their implementation must be understood to use them.
What is being described here is the Template Method Pattern. My abstract table class is full of template methods which means that every concrete table class, which is a subclass of this abstract class, shares the same methods. It does not matter that the data held in each table is totally different as the only operations that can be performed on a table are always the same - Create, Read, Update and Delete (CRUD). Every Controller communicates with its Model(s) using one or more of these template methods. The invariant methods in the abstract class are always executed, but the empty variable "hook" methods may be overridden in any concrete subclass.
The major problem with such a framework is that every application requires the creation of many new subclasses. While most of these new subclasses are simple, their number can make it difficult for a new programmer to learn the design of an application well enough to change it.
Not with the RADICORE framework it doesn't. You only need to create one concrete table class for each table in your database. All the other components - abstract table class, Views, Controllers and Data Access Objects - come supplied with the framework.
A second problem is that a white-box framework can be difficult to learn to use, since learning to use it is the same as learning how it is constructed.
There is a learning curve with every framework, but if all you are going to do is write and then maintain database applications then you should treat any learning curve as an investment that will pay off over time.
Another way to customize a framework is to supply it with a set of components that provide the application specific behavior. Each of these components will be required to understand a particular protocol. All or most of the components might be provided by a component library. The interface between components can be defined by protocol, so the user needs to understand only the external interface of the components. Thus, this kind of a framework is called a black-box framework.
RADICORE is a white-box framework for building and then running web-based database applications, which means that the Presentation layer does nothing but deal with the sending a receiving of HTML forms while the Data Access layer deals with nothing but the reading and writing of data within a database. These two layers are not affected by what data is passed between them, so they can be built as standard and reusable components. It is only the components in the Business layer which need be created and maintained by the developer. While all standard behaviour is supplied by the invariant methods within the abstract class, any custom behaviour can be supplied by customisable/variable methods within each table's subclass.
The idea with RADICORE is that you should never need to customise the framework. You build a new subsystem for each new application domain and then run it. Everything is taken care of by the framework except the business rules which the developer deals with by inserting code into the relevant "hook" methods in each table's subclass.
In the introduction of Designing Reusable Classes it states the following:
Object-oriented programming is often touted as promoting software reuse [Fischer 1987]. Languages like Smalltalk are claimed to reduce not only development time but also the cost of maintenance, simplifying the creation of new systems and of new versions of old systems. This is true, but object-oriented programming is not a panacea. Program components must be designed for reusability. There is a set of design techniques that makes object-oriented software more reusable. Many of these techniques are widely used within the object-oriented programming community, but few of them have ever been written down. This article describes and organizes these techniques. It uses Smalltalk vocabulary, but most of what it says applies to other object-oriented languages. It concentrates on single inheritance and says little about multiple inheritance.
This makes it clear that simply writing programs that use classes and objects is no guarantee that you will be automatically creating software that is more reusable and will require less maintenance. It is how you design your classes to take advantage of encapsulation, inheritance and polymorphism which counts. The more reusability you produce the better.
In the section on abstract classes in the same article it says:
Creating new abstract classes is very important, but is not easy. It is always easier to reuse a nicely packaged abstraction than to invent it. However, the process of programming in Smalltalk makes it easier to discover the important abstractions. A Smalltalk programmer always tries to create new classes by making them be subclasses of existing ones, since this is less work than creating a class from scratch. This often results in a class hierarchy whose top-most class is concrete. The top of a large class hierarchy should almost always be an abstract class, so the experienced programmer will then try to reorganize the class hierarchy and find the abstract class hidden in the concrete class. The result will be a new abstract class that can be reused many times in the future.
This quite clearly says that creating a class hierarchy whose top-most class is concrete is bad, but large numbers of programmers are still doing it. Why? Because that is the way they are taught to do it. This can create problems, but instead of using inheritance correctly they came up with a new principle called favour composition over inheritance. It also leads to such statements as inheritance breaks encapsulation and Inheritance produces tight coupling. I ignore all these principles simply because I don't have the problems created by having deep class hierarchies whose top-most class is concrete. I avoid such problems altogether by only ever inheriting from an abstract class. Taking steps to avoid a problem altogether is always much better than trying to deal with the consequences of hitting that problem. As the old saying goes: Prevention is better than Cure.
The article goes on to say:
We have already seen that object-oriented programming languages encourage software reuse in a number of ways. Class definitions provide modularity and information hiding. Late-binding of procedure calls means that objects require less information about each other, so objects need only to have the right protocol. A polymorphic procedure is easier to reuse than one that is not polymorphic, because it will work with a wider range of arguments. Class inheritance permits a class to be reused in a modified form by making subclasses from it. Class inheritance also helps form the families of standard protocols that are so important for reuse.
These features are also useful during maintenance. Modularity makes it easier to understand the effect of changes to a program. Polymorphism reduces the number of procedures, and thus the size of the program that has to be understood by the maintainer. Class inheritance permits a new version of a program to be built without affecting the old.
Here the article states that creating useful abstractions is a rare skill among programmers.
The most important attitude is the importance given to the creation of reusable abstractions. Kent Beck describes the difficulty in finding reusable abstractions and the importance placed on them by saying:
Even our researchers who use Smalltalk every day do not often come up with generally useful abstractions from the code they use to solve problems. Useful abstractions are usually created by programmers with an obsession for simplicity, who are willing to rewrite code several times to produce easy-to-understand and easy-to-specialize classes.
Later he states:
Decomposing problems and procedures is recognized as a difficult problem, and elaborate methodologies have been developed to help programmers in this process. Programmers who can go a step further and make their procedural solutions to a particular problem into a generic library are rare and valuable. [O' Shea et. al. 1986]
Here the article states that useful abstractions are discovered after writing code, not invented before writing code.
The sixth section of this article describes design rules. These rules are based on the fact that useful abstractions are usually designed from the bottom up, i.e. they are discovered, not invented. We create new general components by solving specific problems, and then recognizing that our solutions have potentially broader applicability. The design rules in this paper are a way of converting specific solutions into reusable abstractions, not a way of deducing abstractions from first principles.
This is precisely how I did it in my own application. I did not start with an abstract class and work my way down to a concrete class, I started by building a Model, View and Controller to handle Table#1 where the Model did not inherit anything. I then copied these three modules to deal with Table#2 which involved changing all the references for Table#1 to Table#2. I then went through the classes line by line and moved all the code which was duplicated into an abstract class. When I was finished the Model classes ended up with nothing but their constructors. You can read the full details in Evolution of the RADICORE framework.
This is not just a case of looking at code which can be reused, the starting point should be to look at the application as a whole - the "big picture" if you like - looking for patterns in structure as well as behaviour. If you cannot spot such patterns then your ability to create reusable objects will be severely limited. Some patterns can be turned in templates such as XSL stylesheets which are collections of small templates. Duplicated code can be moved into subroutines which can be called, or moved into an abstract class so that it can be inherited. A great advantage of using an abstract class, which is briefly mentioned in Rule 8 of the Johnson and Foote article, is that it enables the use of the Template Method Pattern which is a vital component in any framework.
The first pattern you should notice in every enterprise application is that it is broken down into a large number of tasks (aka user transactions) where each task can be characterised as an having an electronic form at the front end to input and view data, a database at the back end to store and retrieve that data, and software in the middle to handle the transfer of data between the two ends and to process any business rules. Note that while most tasks will produce output in HTML form, some will produce CSV or PDF, or perhaps even XML or JSON, while some will produce no visible output at all. According to "best practices" the correct way to write code to implement these three areas of processing is to use the 3-Tier Architecture with its Presentation layer for the front end, its Business layer in the middle, and its Data Access layer at the back end. As an alternative you could implement the Model-View-Controller (MVC) design pattern. If you are really adventurous you could combine the two, as shown in Figure 1 and Figure 2.
Figure 1 - The MVC and 3-Tier architectures combined
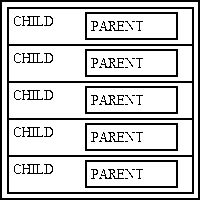
Here is an alternative diagram which shows the same information in a different way:
Figure 2 - MVC plus 3 Tier Architecture
")
This results in objects which are one of the following:
Every subsystem in an enterprise application has its own unique elements - a database to store data and user transactions to maintain and view that data. While a novice programmer would tend to construct separate objects for each component in each transaction this would be wrong as it would result in a great deal of duplicated code. The experienced programmer would use the process of abstraction to look for similarities or patterns in the code so that he could put the similar code into reusable functions/methods so that they can be called many times instead of being duplicated many times. The more reusable code you have at your disposal the less code you will have to write and maintain, and the more productive you will be.
The ability to spot patterns is an art, a skill which some programmers have but most do not. Most programmers can only identify a pattern when somebody else sticks a label on it. A real programmer has the ability to spot patterns that others miss and then exploit them by creating reusable code. So what are these patterns in an enterprise application? Consider the following:
In a large ERP application, such as the GM-X Application Suite, which is comprised on a number of subsystems, each subsystem has a unique set of attributes:
Despite the fact that these two areas are completely different for each subsystem, because the code to implement them follows the same set of rules they can each be handled using standard reusable code provided by the framework.
By starting with these basic observations I was able to see recurring patterns in my code which I could then convert into reusable objects. I started by creating a Model class for my first database table. In the early stages of learning PHP I saw several code samples where the Model contained three separate and distinct methods - load(), validate() and store(). My previous experience taught me that when a group of functions is always executed in the same sequence that instead of always writing code to call those functions one after the other, along with any error checking, it is far more efficient to place that group of functions in a separate wrapper function so that you can perform the whole group with a single call to the wrapper.
A second practice which I chose to ignore was deconstructing the contents of the $_POST array into its constituent parts so that they could be loaded into the Model one at a time with separate setters. This would also require the use of separate getters to get that data out. I had become impressed with how arrays were handled in PHP compared with the alternatives in my previous languages, so I decided to take a shortcut and pass in the entire contents of that array as a single argument on a method call. This is a prime example of loose coupling which is considered to be superior to tight coupling. I therefore ended up with a set of methods such as those shown in common table methods.
After creating the code for the first database table I then created the code for the next database table. I did this by copying the code and then changing the table names. Note that I did not have to change any column names as my use if a single $fieldarray array meant that I did not require a separate property for each column. This resulted in a lot of duplicated code in each Model class, so how do you convert that into reusable code? The obvious choice should be inheritance, which is why I created an abstract table class which could then be inherited by each concrete table class. Note that I did not make the mistake of inheriting from the first concrete class. I moved the duplicated methods into the abstract class and deleted them from each concrete class. I ended up with classes which were empty apart from their constructors, but they still worked.
Notice that I reference the data array as $fieldarray and not $this->fieldarray. This is because I found it more convenient to pass this data around as an input and output argument on each method call. This also means that any attempt to alter a value using $this->fieldarray['fieldname'] will be wiped out with the next call to any of the CRUD methods.
You may notice that none of these method names include the name of the table on which they are expected to operate. Each table has its own concrete class, and each of those classes contains the table name as a class property called $this->tablename. This means that at runtime each Model object "knows" the identity of the table on which it is operating.
With my Controllers it was a different matter. Each of these was unique in that it called different combinations of methods on their designated Models. The only difference between those for table #1 and table #2 was the identity of the table class which was instantiated into an object. My solution for this was to change the controller script to take the class name from a variable and to create a separate component script to supply a value for this variable. I later discovered that this was a form of Dependency Injection.
The Controller which calls that method on the Model does not contain any references to the table name. It also does not contain any references to any columns because it loads the entire contents of the $_POST array in one go without having to explode it into its component parts and load each part one at a time. This leaves me with the following levels of reusability:
If I have 40 Controllers and 450 Models this means that I have 40 x 450 = 18,000 (EIGHTEEN THOUSAND) opportunities for polymorphism. The more polymorphism I have then the more opportunities I have for creating code which is reusable via dependency injection. Taking steps to increase the amount of polymorphism is therefore a worthy goal while doing the opposite is not.
Instead of having a single store() I created a separate one for each CRUD operation to deal with the different ways in which the SQL query is constructed. This is where having all the table's data in a single $fieldarray property instead of multiple properties became very useful. The structure of the different SQL queries follows a standard template:
INSERT INTO <tablename> (column1, column2, column3, column4, ...columnN)
VALUES (value1, value2, value3, value4, ...valueN);
UPDATE <tablename>
SET SET column1 = value1, column2 = value2...., columnN = valueN
WHERE [condition];
DELETE FROM <tablename> WHERE [condition];
SELECT <select_str>
FROM <tablename>
<join_str>
<where_str>
<group_str>
<having_str>
<sort_str>
<limit_str>
The SQL query is nothing but a long string, so constructing a string from an associative array is very easy in PHP:
$field_list = null; $value_list = null; foreach ($fieldarray AS $fieldname => $fieldvalue) { if (strlen($fieldvalue == 0) { $fieldvalue = 'NULL'; // empty, so set to NULL } else { $fieldvalue = "'$fieldvalue'"; // enclose in single quotes } // if if (empty($fieldlist) { $field_list = $fieldname; $value_list = $fieldvalue; } else { $field_list .= ", $fieldname"; $value_list .= ", $fieldvalue"; } // if } // foreach $query = "INSERT INTO $tablename ($field_list) VALUES ($value_list)";
Note here that while numeric values do not need to be enclosed in single quotes, the DBMS will not object if they are.
You may recall that I included the entire contents of the $_POST array as an input argument in the first call into the Model, but the observant among you might be aware that this array may contain field names which do not actually exist on that table, such as the SUBMIT button, which would cause the SQL query to be rejected. To get around this I manually created a new class property called $fieldlist which contained an array of field names which were valid for that table. I could then use this list to filter out the invalid field names from $fieldarray before it was passed to the method which generated the SQL query.
I also created an additional array called $primary_key to contain the field name(s) of the primary key to help in the construction of the [condition] string.
If you are observant you should notice that the above methods can work with any database table as the structure of the queries follows a standard pattern. The differences between one table and the next are supplied either as input arguments or class properties, but the processing is exactly the same. As these methods can be shared in every concrete table class it makes sense to define them in an abstract class so that they can be inherited from a single source instead of being duplicated each time.
When it comes to building a SELECT query using the getData() method you should already be aware that this query is actually comprised of a series of substrings some of which are optional. The query generated by the framework by default will be as simple as possible:
SELECT * FROM $tablename [WHERE $where_str]
Note here that $where_str is optional. Some user transactions will allow this string to be empty while others will insist that it contain values for the primary key of that table. This is easy to check as the identity of the primary key columns are contained in the $primary_key property.
There is a separate class property for each of those substrings, which allows the developer to insert custom values using the _cm_pre_getData() method which is one of the "hook" methods. Note also that it is possible for the framework to automatically insert JOIN substrings using data within the $parent_relations array, as described in Using Parent Relations to construct sql JOINs.
Every programmer knows that all user input should be properly validated before it can be processed. This is especially important when accepting input from HTML forms as all values are unvalidated strings which means that a user could enter "four" as a number and "today" as a date, thus causing the resulting SQL query to be rejected. In all the code samples I saw during my learning period all this validation was hard-coded, but I did not like this idea. In those languages with compiled forms it is possible to set the datatype for each field in the form so that the user is physically prevented from inserting an invalid value. This is not possible in HTML forms (at least it wasn't in 2002), so I had to invent my own way of automating this procedure. The manual procedure involved looking at the table's DDL script in order to identify the names and specifications of all the fields in that table, so I hit upon the idea of copying this information into the table's class file so that I could then write a procedure to process this information. This is where I transformed the $fieldlist array which I mentioned earlier into the $fieldspec array which I am still using 20 years later. The information is this array is processed in the built-in validation class which again takes advantage of the fact that all the data is contained in a single $fieldarray property.
Originally I populated the $fieldspec array by hand, but this became very tedious, so I decided to automate it by writing a procedure which extracted the relevant data from the database's INFORMATION_SCHEMA and wrote it to a table structure file, one for each table. I did this by creating a separate Data Dictionary subsystem with separate import and export procedures.
The validateInsert() method iterates through the $fieldspec array and compares a value found in the $fieldarray array with its specifications so that it can detect a field marked as NOT NULL which does not have a value.
The validateUpdate() method iterates through the $fieldarray before looking at the $fieldspec array as it is only concerned with values which have actually been changed.
Notice that these standard methods can only perform what I call primary validation as that it easy to automate. Additional (secondary) validation has to be performed in separate methods which have to be manually added to each concrete table class. The advantage of putting all the standard methods in an abstract table class was that I could then implement the Template Method Pattern and create "hook" methods which I could then add to individual subclasses.
The validateDelete() method does not use the $fieldspec array. Instead it uses the $child_relations array which contains a type property to identify what action needs to be taken regarding any child tables before the parent record can be deleted.
As you should be able to see I have automated as much as possible by providing components within the framework to carry out as much common functionality as possible, which means that when using my framework to create an application the only code that has to be written is that which is inserted into into the relevant "hook" methods.
As mentioned above in What is an "entity"? there are basically two types of object - Entities and Services. Unlike an entity which can have numerous methods to load, modify and interrogate its data (state), a service does not have any state of its own so it performs its function on the data which is obtained from a separate entity. Having performed its function on that data and produced a result the service has no more use for that data. Some developers create separate services to operate on specific entities, but this is not the correct way to use OOP as it does not offer any reusability. It would better to create services which can operate on any entity. How can this be done? By maximising the use of inheritance to share common methods within each entity. This provides polymorphism which in turn provides opportunities for Dependency Injection.
The components in the RADICORE framework fall into the following categories:
Notice here that transforming an entity's data into HTML, CSV or PDF is not a function that is carried out within the entity itself. Mixing presentation logic with business logic and SQL logic is frowned upon in modern applications as it produces a tangled mess that is difficult to maintain. In my long career I have personally dealt with monolithic single-tier applications, then 2-tier applications, finally ending up with the 3-Tier Architecture which is an implementation of the Single Responsibility Principle (SRP). I loved this architecture so much that I made it the starting point when I redeveloped my framework in PHP. By later splitting my Presentation layer into two separate components, a Controller and a View, I also accidentally created an implementation of the Model-View-Controller (MVC) design pattern.
When an object such as a service performs a single operation on a set of application data there is little scope for a data abstraction unless you fall into the trap of treating the data for each entity as being so different that you have to create a different version of that service for each entity. As soon as I started programming with PHP I recognised that this was not the case.
By deliberately designing the entities in the Business/Domain layer so that their data can be both input and output in a single array instead of being forced to use separate getters and setters for each column, thus exhibiting loose coupling, it then became much easier to design a single service for each operation that can work with any data rather than having a separate version of that service that can only work with the data for a particular entity.
None of the services in the RADICORE framework was designed to operate on a specific entity. In order to maximise reusability they were designed to operate on any given entity. At runtime the entities are injected into the relevant service as follow:
After having built many screens in my previous languages I had already come to notice that many had the same basic structure or layout, sometimes the same behaviour, but with the only difference being with the content. Some of this content could be supplied by the framework and some could be supplied by each application component. In my previous languages each screen had to be built individually so that it could be compiled before it could be used, and all the software could do was amend the data that was to be displayed. It simply was not possible to amend the structure of the screen 'on the fly'. Fortunately this restriction does not exist with PHP as each screen is an HTML document which is nothing more than a plain text file containing values which are enclosed in HTML tags, usually with some CSS style information and perhaps some javascript. When each PHP script is activated its HTML document has to be built entirely from scratch, so it is entirely possible for each page to be built differently than before.
Although all the early PHP books and online tutorials which I read showed the HTML document being output in little chunks in different parts of the code I had already dismissed this idea as being far too long-winded and primitive for my needs. Instead I wanted to create each web page from a template, which meant that I needed to make use of a templating engine. Fortunately I had already encountered XML documents and XSL stylesheets in my previous language, so I knew that these would work, and after having confirmed that PHP contained the necessary extensions I made XSL Transformations the standard templating engine in my RADICORE framework. This is how I managed to build a single View object which performs the following steps at the end of each PHP script:
Note that the XML document is not constructed in little chunks during the execution of the PHP script, it is constructed in one go as the final step in each script. It does not matter in what order the various pieces of data are added to the document as the XSL transformation process can read those pieces in whatever order it likes.
In my first iteration I created separate stylesheets for each web page to account for the different column names and their position on the HTML document. However, after building more and more web pages for more and more database tables I began to notice more and more similarities. After a bit of experimentation and refactoring I managed to confine all the similarities into a set of reusable XSL stylesheets and relegate the differences to a series of screen structure scripts. My main ERP application currently has 4,000 (four thousand) web pages which are produced from just 12 (twelve) XSL stylesheets. How's that for reusability?
Here is an example of one of my earliest stylesheets which is described in Using PHP 4's Sablotron extension to perform XSL Transformations:
<?xml version='1.0'?> <xsl:stylesheet xmlns:xsl="http://www.w3.org/1999/XSL/Transform" version="1.0"> <xsl:output method='html'/> <!-- param values may be changed during the XSL Transformation --> <xsl:param name="title">List PERSON</xsl:param> <xsl:param name="script">person_list.php</xsl:param> <xsl:param name="numrows">0</xsl:param> <xsl:param name="curpage">1</xsl:param> <xsl:param name="lastpage">1</xsl:param> <xsl:param name="script_time">0.2744</xsl:param> <!-- include common templates --> <xsl:include href="std.pagination.xsl"/> <xsl:include href="std.actionbar.xsl"/> <xsl:template match="/"> <html> <head> <meta http-equiv="Content-Type" content="text/html; charset=UTF-8" /> <title><xsl:value-of select="$title"/></title> <style type="text/css"> <![CDATA[ <!-- caption { font-weight: bold; } th { background: #cceeff; } tr.odd { background: #eeeeee; } tr.even { background: #dddddd; } .center { text-align: center; } --> ]]> </style> </head> <body> <form method="post" action="{$script}"> <div class="center"> <table border="0"> <caption><xsl:value-of select="$title"/></caption> <thead> <tr> <th>Select</th> <th>Id</th> <th>First Name</th> <th>Last Name</th> <th>Star Sign</th> <th>Person Type</th> </tr> </thead> <tbody> <xsl:apply-templates select="//person" /> </tbody> </table> <!-- insert the page navigation links --> <xsl:call-template name="pagination" /> <!-- create standard action buttons --> <xsl:call-template name="actbar"/> </div> </form> </body> </html> </xsl:template> <xsl:template match="person"> <tr> <xsl:attribute name="class"> <xsl:choose> <xsl:when test="position()mod 2">odd</xsl:when> <xsl:otherwise>even</xsl:otherwise> </xsl:choose> </xsl:attribute> <td><xsl:value-of select="selectbox"/></td> <td><xsl:value-of select="person_id"/></td> <td><xsl:value-of select="first_name"/></td> <td><xsl:value-of select="last_name"/></td> <td><xsl:value-of select="star_sign"/></td> <td><xsl:value-of select="pers_type_desc"/></td> </tr> </xsl:template> </xsl:stylesheet>
Here I am using templates called pagination and actbar which are obtained from external files which are loaded using the <xsl:include> command. These are the equivalent calling subroutines from an external library. The <xsl:apply-templates> command will then iterate over every person element and process the matching template which is hard-coded at the bottom of that stylesheet. This method meant that I had to create a separate XSL stylesheet for each screen as both the table names and the columns were hard-coded.
The previous example was for a LIST screen where all the columns are display-only, but for ADD screens or UPDATE screens each field/column must be specified using the correct HTML control, as in the following example:
<tr> <td class="label">First Name</td> <td> <input type="text" name="first_name" size="//person/first_name/@size"> <xsl:attribute name="value"> <xsl:value-of select="//person/first_name"/> </xsl:attribute> </input> </td> </tr>
Note that the code required for other controls, such as dropdown lists and radio groups, can be more complex.
My next step was to move the code for each HTML control into its own template, as in the following:
<tr> <td class="label">First Name</td> <td> <xsl:call-template name="textbox"> <xsl:with-param name="field" select="//person/first_name"/> </xsl:call-template> </td> </tr>
Here I am still hard-coding which control goes with which field, but what if I wanted to change that choice in my PHP code? I decided to specify the desired control in the XML document as an attribute called control and create a new template called datafield which would call the relevant template:
<tr> <td class="label">First Name</td> <td> <xsl:call-template name="datafield"> <xsl:with-param name="field" select="//person/first_name"/> </xsl:call-template> </td> </tr>
This is the datafield template:
<xsl:template name="datafield"> <xsl:param name="field"/> <xsl:choose> <xsl:when test="$field/@control='dropdown'"> <xsl:call-template name="dropdown"> <xsl:with-param name="field" select="$field"/> </xsl:call-template> </xsl:when> <xsl:when test="$field/@control='radiogroup'"> <xsl:call-template name="radiogroup"> <xsl:with-param name="field" select="$field"/> </xsl:call-template> </xsl:when> <xsl:otherwise> <!-- this is the default control type --> <xsl:call-template name="textbox"> <xsl:with-param name="field" select="$field"/> </xsl:call-template> </xsl:otherwise> </xsl:choose> </xsl:template>
This method still forced me to have a separate XSL stylesheet for each screen as I needed to specify which fields needed to be extracted from the XML document and placed where in the screen. This had been reduced to a simple list which basically said "place column X in the next cell of the current row in the screen", so I asked myself the question "Can I define this list in the XML document and process it in the XSL stylesheet?" I started by creating a new element called structure in the XML document which looked like the following:
<structure>
<main id="person">
<row>
<cell label="Select"/>
<cell field="selectbox"/>
</row>
<row>
<cell label="Id"/>
<cell field="person_id"/>
</row>
<row>
<cell label="First Name"/>
<cell field="first_name"/>
</row>
<row>
<cell label="Last name"/>
<cell field="last_name"/>
</row>
<row>
<cell label="Star Sign"/>
<cell field="star_sign"/>
</row>
<row>
<cell label="Person Type"/>
<cell field="pers_type_desc"/>
</row>
</structure>
I then played with the code in my XSL stylesheet to process this new element (see std.detail1.xsl for details). In order to populate the structure element in the XML document I made use of a small screen structure file which specifies which piece of application data goes where on the screen, as shown in the following:
<?php $structure['xsl_file'] = 'std.list1.xsl'; $structure['tables']['main'] = 'person'; $structure['main']['columns'][] = array('width' => 5); $structure['main']['columns'][] = array('width' => 70); $structure['main']['columns'][] = array('width' => 100); $structure['main']['columns'][] = array('width' => 100); $structure['main']['columns'][] = array('width' => 100); $structure['main']['columns'][] = array('width' => '*'); $structure['main']['fields'][] = array('selectbox' => 'Select'); $structure['main']['fields'][] = array('person_id' => 'Id'); $structure['main']['fields'][] = array('first_name' => 'First Name'); $structure['main']['fields'][] = array('last_name' => 'Last Name'); $structure['main']['fields'][] = array('star_sign' => 'Star Sign'); $structure['main']['fields'][] = array('pers_type_desc' => 'Person Type'); ?>
This file is read into memory at the start of the script, and is copied into the XML document just before the script finishes. This allows the in-memory version to be modified at runtime.
In this way I have separated the similarities from the differences, the what data needs to be processed from the how it needs to be processed. The what is contained within the XML document which is freshly built when each task is run, while the how is defined within a small library of just 12 (twelve) Reusable XSL stylesheets. I have used these 12 stylesheets in my main ERP application to produce the web pages for over 4,000 (four thousand) different tasks, and if that does not qualify as the height of reusability then I'll eat my hat.
Note that my ability to create a single View component which can extract the data from any Model and transform it into XML and then HTML was greatly enhanced by the fact that no Model contains separate named properties for each table column. Instead they all use a ubiquitous $fieldarray property which can hold any data from any table or even several tables. All this data can be extracted using the standard getFieldArray() method. This is an example of loose coupling which is considered to be "good". If each column of data had its own named property then I would need separate calling components for each Model which contained hard-coded references to these named properties, and each of these components would be tightly coupled to a single Model, which is considered to be "bad".
Every modern programmer should be familiar with the term use case, but in my earlier COBOL days they were known as user transactions or units of work, but for the last 20 years I prefer to use the name task as it is short and to the point.
While some OO methodologies teach that each task should have its own method in the domain/business layer I was totally unaware of this idea, so I chose a totally different approach which has turned out to provide enormous benefits. As soon as I started programming with objects I noticed that OOP was 2 Tier by nature - after writing a class for an object in the business/domain layer to encapsulate its own collection of properties and methods it was also necessary to have an additional object in the presentation/UI layer in order to instantiate that class into an object and then call whatever methods were necessary to satisfy the needs of a particular task. In my framework the object in the business/domain layer is known as the Model, while the object in the presentation/UI layer is known as the Controller. This means that each task is actually comprised of two separate components - a Controller which calls a specific set of methods in a specific sequence on a Model, and a Model which contains its own implementation of those methods. The same Model can be forced to produce different outcomes simply by combining it with a different Controller which may either call a different combination of methods and/or use a different View.
My previous experience with database applications had also taught me that each task, from a starting point, performs one or more operations on one or more tables, and regardless of what data a table holds it is always subject to the same operations which are Create, Read, Update and Delete (CRUD). Code to handle the unique business rules is handled separately. The most common set of maintenance tasks for a database table is this family of forms, as shown in Figure 3, where each task performs a different combination of these operations.
Figure 3 - A typical Family of Forms
")
Note that each box in the above diagram is a hyperlink.
Some programmers may think that this family of forms constitutes a single use case and therefore requires a single controller which could operate in one of six modes with the ability to switch modes at runtime. I was taught something similar in my early COBOL days, but in the 1980s I saw the advantage of splitting a large component which could operate in several modes to a group of small components which handled just one of those modes each.
The operations which are performed by each task are as follows:
| LIST | Calls the getData() method with an optional WHERE string and may return any number of rows. |
| INSERT | Displays a screen without values (unless the _cm_getInitialData() method is used) and then calls the insertRecord() method to add a single new row to the database. |
| UPDATE | Calls the getData() method using values for the table's primary key, displays that data on the screen, allows the user to make changes, then calls the updateRecord() method. |
| DELETE | Calls the getData() method using values for the table's primary key, displays that data on the screen, then calls the deleteRecord() method. |
| ENQUIRE | Calls the getData() method using values for the table's primary key, then displays that data on the screen. |
| SEARCH | Displays a screen without any values, and any which are entered are passed back to the parent LIST task and used as filters before it calls the getData() method again. |
Note that each of the above methods is just a wrapper for a group of methods which are defined in the abstract table class. Some of these methods are invariant/fixed while others are "hook" methods which can be defined in each concrete subclass.
When creating Controllers the question you should ask is where do I start? Do I start with the Model and then add in the operations? Or do I start with the operations and add in the Model? It is only after creating several sets of Controllers for different Models that you can really answer this question. Supposing that you create 10 sets of forms for 10 different Models - what are the similarities and what are the differences? The similarities are that each Controller performs the same set of operations regardless of the Model, and the differences are that each set performs it operations on a different Model.
The OO capabilities of PHP provided me with the ability to encapsulate the similarities into a series of reusable Controllers plus the ability to supply the identity of the Model at runtime. All the operations are available in every Model because they are inherited from the same abstract table class, which means that they can be called in a polymorphic manner. You make use of polymorphism by calling the known operations on an unknown object where the identity of that object is not provided until runtime using a mechanism known as Dependency Injection. In my framework this is achieved with the use of a simple component script which says "Run a task using this Model, this View and this Controller". In this way a Controller can be used with any Model, and a Model can be used with any Controller.
Because the behaviour of each reusable Controller is fixed I found it necessary to document this behaviour in Transaction Patterns for Web Applications. Building a new task, or a family of tasks, then became a series of steps which I performed manually. Because these steps were always predictable I eventually decided to automate it. I had already created a Data Dictionary to automate the creation of both the table class file and the table structure file, so it was relatively straightforward to add in a procedure to match a pattern to a table, press a button, and have it create the necessary scripts and perform the necessary database updates.
Over time I have created new Controllers to deal with more complex scenarios, especially those which deal with relationships (associations) between two tables. In some cases this has meant adding new methods to the abstract class, both invariant and variable, but these have always been in addition to the existing methods so that they would continue to work as they always did.
By making my Controllers loosely coupled to any Model instead of tightly coupled to a particular Model, and by tying them to a particular XSL stylesheet which defines the screen's structure, I have been able to create a library of Transaction Patterns. Unlike design patterns where you have to manually create your own implementation each time these allow you link a pattern with a database table and by pressing a button you can generate the code for a task (or in some cases a family of tasks) which you can run immediately without having to write a single line of code - no PHP, no HTML, no SQL. While the generated task can only handle standard validation, the developer can implement any complex business rules by inserting code into the relevant "hook" method in the table's subclass.
Every experienced programmer has probably heard the statement avoid premature optimisations
for reasons given in premature optimisation is the root of all evil. There is also the advice avoid the premature use of design patterns
given by Erich Gamma, one of the Gang of Four in an article How to use Design Patterns in which he stated:
What you should not do is have a class and just enumerate the 23 patterns. This approach just doesn't bring anything. You have to feel the pain of a design which has some problem. I guess you only appreciate a pattern once you have felt this design pain.Do not start immediately throwing patterns into a design, but use them as you go and understand more of the problem. Because of this I really like to use patterns after the fact, refactoring to patterns.
One comment I saw in a news group just after patterns started to become more popular was someone claiming that in a particular program they tried to use all 23 GoF patterns. They said they had failed, because they were only able to use 20. They hoped the client would call them again to come back again so maybe they could squeeze in the other 3.
Trying to use all the patterns is a bad thing, because you will end up with synthetic designs - speculative designs that have flexibility that no one needs. These days software is too complex. We can't afford to speculate what else it should do. We need to really focus on what it needs. That's why I like refactoring to patterns. People should learn that when they have a particular kind of problem or code smell, as people call it these days, they can go to their patterns toolbox to find a solution.
Alongside avoiding the premature use of optimisations and design patterns there is, or should be, another piece of advice which is to avoid the premature use of abstractions. To put it simply, do not think that you can design a particular abstraction and then write the code to fit that abstraction. Instead you should first write code that works, even if it contains blocks of duplicated code, and only afterwards should you review that code looking for repeating patterns. This is the basis of the style of programming which Johnson and Foote call programming-by-difference. This involves looking at a group of existing modules so that you can extract the similar from the different, the abstract from the concrete. It is only after you have done this can you possibly find a way to put the similar code into a reusable module (such as an abstract class) and the different code into a separate module (such as a concrete class).
This is precisely the procedure which I followed when I started to build the code for prototype application which evolved into the RADICORE framework. I built a Model class for the first database table along with 5 Controllers to handle the LIST, CREATE, ENQUIRE, UPDATE and DELETE tasks (I added the sixth SEARCH Controller later). After I had tested these I duplicated them to create a set of components which would work with a second database table. This created a lot of duplicated code which I decided to share by creating a generic class (I called it "generic" as PHP4 did not support the keyword "abstract"). I changed the two table classes to inherit from the generic class, then gradually moved the duplicated code from each table class into the generic class. I tested as I went to ensure that everything still worked as it should, and I ended up with a generic class that was full of code while each table class was empty apart from its constructor. Dealing with the Controllers was slightly different as instead of moving the code which was similar I left that in place and move the differences to a separate component script, as shown in this loose coupling example which was better than the original with its tight coupling.
This transfer of code was made possible due to some early design decisions which I had made:
load(), validate() and store() I had learned during my COBOL days in the early 1980s that if you always have to call the same group of functions in the same sequence then instead of calling those functions separately it is much more efficient to enclose those functions in a wrapper so that you can replace multiple calls with a single call. It also makes it easier to update that single wrapper in the future instead of the multiple places which call those functions.It was not until several years after I had completed my RADICORE framework with its large number of reusable components that I was told that my methods were completely wrong. Why? Not because my results were inferior, but because I was not following "best practices". However, this turned out to be a difference of opinion in what the term "best" actually meant:
There are several reasons why I do not follow what my critics keep telling me are "best practices":
Before I switched to using PHP in 2002 I had 20+ years of experience designing and building enterprise applications, so I knew how to design a database following the principles of Data Normalisation and, following a course in Jackson Structured Programming, the benefits of designing software which matched the database structure. While COBOL followed the procedural paradigm, and UNIFACE was component-based and model-driven, PHP 4 was the first language I used which had object oriented (OO) capabilities. I was not sent on a professional course to learn OO by my employer, instead I downloaded everything I needed onto my home PC and taught myself using the PHP manual, some books which I purchased and some tutorials which I found on the internet. While this taught me how to create classes with methods and properties, how to instantiate classes into objects and call their methods, and how to share code using inheritance, there was very little else of substance. There was no description of polymorphism, nor this mystical process called abstraction. PHP 4 did not even support the abstract keyword, so there was no mention of abstract classes, nor even a hint of other rules, principles and practices which I was told later that every "good" programmer is supposed to follow. As I knew nothing of these "rules" I did not follow them. Instead all I had to go on were my own skills which were derived from 20 years of experience with writing database applications in several other languages, and that experience led me to the following observations:
These observations led me intuitively to the following implementations when using the OO capabilities of PHP:
I first proved that my ideas worked by building a small Sample Application (which you can run online here) which demonstrated how to access several database tables with different relationships. Note that this does not have a framework database as it does not have a logon screen, and all the menu and navigation options are hard-coded. Once I had proved that my ideas worked I then built a MENU database and the framework code to run a selection of Prototype Applications. Since then I have built an ERP application as a package - first known as TRANSIX but now known as GM-X - which has grown over the years to include more and more subsystems.
As far as I am concerned these so-called "best practices" are not rules which every OO programmer is obliged to follow, they are nothing more than the personal preferences of small groups of programmers who have done nothing more than identify the practices which work best for them. I have chosen to disregard them for the following reasons:
favour composition over inheritanceand was obviously devised by someone who did not understand how to use inheritance properly. I never saw any explanations as to why inheritance was supposedly bad, and as my own use of inheritance never indicated any problems I decided to treat that "advice" as the ravings of a lunatic. I only ever inherit from an abstract class which I learned later was the proper thing to do. This allowed me to create a huge amount of reusable code which is shared by hundreds of concrete classes. It also allowed me to utilise the Template Method Pattern so that I can easily insert non-standard code into "hook" methods within each concrete class.
program to the interface, not the implementationI was completely mystified. PHP 4 did not contain the interface keyword, so I assumed it meant the same thing as Application Programming Interface (API) which identifies a function, method or subroutine, which exists in another piece of code, but which can be called from another piece of code. I may be stupid, but in OOP you cannot simply call a method signature, you must call a method on an object that implements that signature. This is how a Controller passes control to a Model - it calls a method on an instance of a Model class. When PHP 5 was released I finally understood that it involved the use of the keywords interface and implements, but as I was already using the keywords abstract and extends to share reusable code I could not see any benefit in using interfaces. It was not until I read Polymorphism and Inheritance are Independent of Each Other that I realised that interfaces were invented to solve a particular problem in statically-typed languages, but as PHP is dynamically-typed and does not have that problem that "solution" is totally redundant and therefore pointless. I can have polymorphism in PHP without inheritance and without interfaces, so they do not add value, only keystrokes. They don't add code which can be shared, only code which is redundant.
High-level modules should not depend on low-level modules; both should depend on abstractions. Abstractions should not depend on details; details should depend on abstractionsas there were no explanations or examples of what this actually meant. Nowhere did it mention taking methods that were duplicated in several concrete classes and moving them to an abstract class so that could be shared using inheritance. Nowhere did it mention that the act of creating multiple classes which shared the same methods, which could happen with or without inheritance, was also creating polymorphism. It gave no examples of how polymorphism could be used.
polymorphism is the provision of a single interface to entities of different types, but this contains two ambiguous words:
All the tables in my application have their own classes as they are separate entities. They all inherit from the same abstract class as they all share the same protocols. This "sharing of the same methods" produces the effect known as "polymorphism". Years before I encountered the Dependency Inversion Principle I was making use of this effect as I later described in Inject Model into the Controller and Inject Model into the View.
This is the reason we do not put SQL in JSPs. This is the reason we do not generate HTML in the modules that compute results. This is the reason that business rules should not know the database schema. This is the reason we separate concerns.
What he is actually describing here is exactly the same as the 3-Tier Architecture, so why didn't he say so instead of appearing to create a completely different and unrelated principle? He also stated This is the reason we separate concerns
which means that SRP is exactly the same as SoC, so why did he describe it using different terminology?
software entities should be open for extension, but closed for modificationit appeared to be saying that if I had a class for an entity which I wanted to modify then I should extend it into a subclass instead and leave the original class alone. I thought this was a stupid idea as I could end up with a deep hierarchy of subclasses, then I would have to change the calling code to reference the new subclass. I thought the whole idea of having shared code in a callable module was that you could make an amendment to that code and not have to make changes to any of the code which called it. I consigned this idea to the rubbish bin.
objects in a program should be replaceable with instances of their subtypes without altering the correctness of that program. As I only ever inherit from an abstract class to create concrete classes it is physically impossible for me to replace an instance of a supertype with an instance of any of its subtypes because the supertype, being an abstract class, can never be instantiated into an object. It would appear, therefore, that this principle only applies when you inherit from one concrete class to create a different concrete class. As I never do this I decided that this principle was irrelevant and could be ignored.
subtyping (implementation inheritance) provides polymorphism without code sharing while subclassing (class inheritance) provides code sharing without polymorphismI was completely mystified as I had already been providing my applications with copious amounts of code sharing and polymorphism through class inheritance since I produced my first sample application way back in 2003. The heart of my framework is built around a single abstract table class which is then inherited by every one of my concrete table classes, of which there can be hundreds. This has allowed me to define all the sharable code in one place using the Template Method Pattern but to insert custom variations into any subclass by the use of overridable "hook" methods. It would appear that some earlier less sophisticated languages only allowed methods to be overridden if they had been defined as abstract methods in a interface instead of non-abstract methods in a superclass. This artificial restriction is described in more detail in Subclasses vs Subtypes.
no client should be forced to depend on interfaces it does not use. In my code I am never forced to add a method to a concrete class which I don't actually use, so I don't have the problem for which this is supposed to be the solution. Eventually I worked out that in this context the word "interface" did not mean "method signature" which could be shared by inheritance using the work "extends", but instead meant that useless artefact that depends on the keyword "implements". In this case the superclass which is constructed using the keyword "interface" can only contain abstract methods which can never contain an implementation, but any subclass must define every abstract method even if the method body, the implementation, is left empty. As I never use the keywords "interface" and "implements", only "abstract" and "extends", I never encounter this problem. Unlike an interface an abstract class can contain concrete methods (with implementations) and I never have to redefine them in a concrete class. Because I also make great use of the Template Method Pattern this allows me to create empty "hook" methods in the abstract class which only have to be defined in a subclass when it is required to override the empty method with an actual implementation which then alters the default behaviour. As I don't use these useless artifacts called "interfaces" this principle is irrelevant in my codebase, so I ignore it.
If the authors of these principles fail to give clarity because of vague and ambiguous definitions then it is no wonder that many programmers are led down the wrong path when they attempt to follow these principles. This can result in some peculiar interpretations which are closely followed by peculiar implementations which do not produce the intended results. For example:
This is the reason we separate concernsthere are a surprising number of programmers who think that "responsibility" and "concern" mean different things which then implies that SRP and SoC are completely different principles which are applied differently. This nonsense is discussed further in Confusion about the words "responsibility" and "concern".
Do not start immediately throwing patterns into a design, but use them as you go and understand more of the problem. Because of this I really like to use patterns after the fact, refactoring to patterns.
While looking at some of the code samples I read in books or in online tutorials there were several practices which I decided not to follow:
When I was later told that all my work was rubbish simply because I was not not following "best practices" I took a look at these practices and quickly concluded that they were anything but the best, and to retrofit them into my framework would wipe out large chunks of reusable code. Among these not-so-best practices were the following:
the sphere of knowledge and activity around which the application logic revolves. This implies that Orders, Inventory and Shipments are entirely different domains as they have totally different database tables, totally different business logic, and totally different user transactions. While this is true an experienced programmer should also be able to see the similarities and realise that these similarities can already be covered by reusable code that is supplied in the framework:
There are enough similarities for me to say that each of these spheres of knowledge and activity is not a separate domain but a sub-domain which shares characteristics with all the other sub-domains. RADICORE is a framework for building web-based database applications, and it is used to build a complete system which is comprised of a number of subsystems (or sub-domains). The framework itself is comprised of four subsystems (Menu, Audit, Workflow and Data Dictionary), and you can add in as many subsystems as you like, a prime example being the GM-X Application Suite.
An is-a relationship is when one type of object 'is a' instance of another type of object.
I have seen far too many examples where people start by saying a Customer is a Person, so I must create a Person class then inherit from it to create a Customer class
. This is not the way such details are recorded in a relational database for use in an enterprise application. In the first case a customer is not limited to being just a person, it may also be an organisation. This is covered properly in Len Silverston's PARTY database. The fact that a Party may be a customer, or even a supplier, does not warrant separate tables for Customer and Supplier. Those are merely Roles which may be attached to Parties in a many-to-many relationship. This also allows for any number of additional Roles, such as employer, employee, manager, contractor, contact, parent organisation, subsidiary, and so on. Each party can have any number of Roles.
This approach can also lead to deep inheritance hierarchies after someone states A Car and a Train and a Truck can all inherit behavior from a Vehicle object, adding their subtle differences. A Firetruck can inherit from the Truck object, and so on
. This is looking at the problem from the wrong angle because it is creating a large number of superclasses which are then each inherited by a small number of subclasses. This greatly reduces the opportunity for polymorphism which then has a knock-on effect of greatly reducing the opportunity for creating reusable code. As OOP, when implemented properly, is supposed to increase code reuse and decrease code maintenance it surely follows that any practice which does not achieve this aim cannot be regarded as "best" by any stretch of the imagination.
Why was it obvious to me, a mere beginner in the art of OOP, that every entity in a database application IS-A table, and because every database table shares exactly the same CRUD protocols as every other table, that the best solution would be to place the common protocols in an abstract class which could then be inherited by every single concrete class in the application? That is why, in my framework, I have a single abstract table class which is inherited by 450 concrete table classes. The use of an abstract class has also enabled me to implement the Template Method Pattern which was described in the Gang of Four Book as follows:
Template methods are a fundamental technique for code reuse. They are particularly important in class libraries because they are the means for factoring out common behaviour.
So if my methods have produced far greater quantities of reusable code than anyone else's, thus producing superior results by making the users of my framework much more productive than the users of other frameworks, how can my critics possibly claim that my practices are not the best?
Has-a is a composition relationship where one object (often called the constituted object, or part/constituent/member object) "belongs to" (is part or member of) another object (called the composite type), and behaves according to the rules of ownership
In a relational database there is no such this a composite table which is comprised of a number of other tables as each table is a separate entity in its own right and is subject to its own set of CRUD operations. Each table therefore has its own table class (Model) and its own set of user transactions to maintain its contents. While there may be relationships with other tables, these are dealt with using separate user transactions. Refer to Object Associations for details.
In my PHP implementation each TASK record contains a column called script_id which points to a small file in the file system which appears as a URL in the browser's address bar. This file is called a component script which does nothing but identify the following:
Note here that the methods called on each Model are NOT unique for each particular task, they are the same shared methods which are available in every Model class. By using shared methods this gives me large amounts of polymorphism which then allows me to share the same Controllers with multiple Models using that technique known as Dependency Injection. If I were to use 4,500 unique method names I would lose all that polymorphism and also the ability to reuse both Controllers and Views using dependency injection. That loss of reusability would be unacceptable to me as it would defeat the entire purpose of using OOP in the first place. Any person who suggests such a stupid idea should be ignored.
Event sourcing is an architectural pattern in which entities do not track their internal state by means of direct serialization or object-relational mapping, but by reading and committing events to an event store.
I do not use any form of serialization, I do not use any form of object-relational mapping, I use nothing but a standard relational database as the applications which I write store changes to entity data using rows in database tables.
When event sourcing is combined with CQRS and domain-driven design, aggregate roots are responsible for validating and applying commands (often by having their instance methods invoked from a Command Handler), and then publishing events.
I do not use CQRS as it means that I should use a different model to update information than the model I use to read information. As far as I am concerned this violates encapsulation which states that ALL the data for an entity and ALL the operations which can be performed on that data should be contained within the same class. Every database table is subject to the same four CRUD operations, so these four operations should be supported by separate methods within each table class. In my framework there are NO exceptions.
I do not have an aggregate root through which any references to any component of that aggregate should pass. Every component is a separate database table with its own class, and it is subject to exactly the same operations as every other table. It also has its own set of user transactions, just like every other database table.
I do not use the Command Handler pattern in my framework. In its place I use a Controller which is part of the Model-View-Controller pattern. I do not have a separate execute() method anywhere as I can do everything that I want to do using the standard methods which are inherited from the abstract table class.
But what is wrong with instantiating an object and calling one of its methods in adjacent lines of code?
None of my objects have different configurations, so this is not a problem which I recognise.
Why should you want to change the behaviour of a piece of code at runtime? Surely once an implementation has been coded inside a method then when you call that method you get that implementation? If you want a different implementation then you have to call a different method.
But what exactly is a "dependency"? I define it as follows:
A dependency exists when one object requires the use of another object in order to carry out its task. For example, when a Controller calls a method on a Model then there is a dependency between the two objects. Note that this is not a two-way dependency - the Controller is dependent on the Model but the Model is not dependent on the Controller because the Model never calls the Controller, it only ever returns a response.
I then read statements such as Dependency Injection decouples the usage of an object from its creation
and Dependency Injection enables loose coupling
, but in these two statements the word "coupling" has different meanings:
To say that Dependency Injection always produces loose coupling
would be completely wrong, and here's why:
EXAMPLE #1: READING function _cm_getForeignData ($fieldarray) // Retrieve data from foreign (parent) tables. { if (!empty($fieldarray['prod_cat_id']) and empty($fieldarray['prod_cat_desc'])) { // get description for selected entry require('classes/product_category.class.inc'); // method #1 $other_table = new product_category; // method #1 $dbobject = RDCsingleton::getInstance('product_category'); // method #2 $dbobject->sql_select = 'prod_cat_desc'; $foreign_data = $dbobject->getData("prod_cat_id='{$fieldarray['prod_cat_id']}'"); $fieldarray = array_merge($fieldarray, $foreign_data[0]); } // if return $fieldarray; } // _cm_getForeignData
Note that I am showing two ways of obtaining an instance of the other table. Method #1 takes two lines of code while method #2 uses only one.
Note also that after retrieving values from a different table I merge that data with the current contents of $fieldarray so that it can be processed with all the other data without the need for additional code.
EXAMPLE #2: WRITING function _cm_post_insertRecord ($fieldarray) // perform custom processing after database record has been inserted. { require('classes/other_table.class.inc'); // method #1 $other_table = new other_table; // method #1 $dbobject = RDCsingleton::getInstance('other_table'); // method #2 $other_data = $dbobject->insertRecord($fieldarray); if ($dbobject->errors) { $this->errors = array_merge($this->errors, $dbobject->getErrors()); } // if return $fieldarray; } // _cm_post_insertRecord
Note that I do not have to filter out any column values which do not belong in other_table as that is done automatically inside the other object.
Note that I was performing my version of dependency injection years before I heard the term simply because I had worked out for myself how to take advantage of all those instances of polymorphism which I had created by inheriting all my concrete classes from a single abstract class. My original code is available in my Sample Application which I published in 2003.
It was not until many years after completing my framework that I was informed that I was not following "best practices" when it came to the use of object associations. When I searched for this term on the internet I found the following:
In object-oriented programming, association defines a relationship between classes of objects that allows one object instance to cause another to perform an action on its behalf. This relationship is structural, because it specifies that objects of one kind are connected to objects of another and does not represent behaviour.
In generic terms, the causation is usually called "sending a message", "invoking a method" or "calling a member function" to the controlled object. Concrete implementation usually requires the requesting object to invoke a method or member function using a reference or pointer to the memory location of the controlled object.
- An association represents a semantic relationship between instances of the associated classes. The member-end of an association corresponds to a property of the associated class
- An aggregation is a kind of association that models a part/whole relationship between an aggregate (whole) and a group of related components (parts).
- A composition, also called a composite aggregation, is a kind of aggregation that models a part/whole relationship between a composite (whole) and a group of exclusively owned parts.
In database design, object-oriented programming and design, has-a (has_a or has a) is a composition relationship where one object (often called the constituted object, or part/constituent/member object) "belongs to" (is part or member of) another object (called the composite type), and behaves according to the rules of ownership. In simple words, has-a relationship in an object is called a member field of an object. Multiple has-a relationships will combine to form a possessive hierarchy.
The phrase allows one object instance to cause another to perform an action on its behalf
is interpreted to mean that if you have a group of related objects (known as an aggregate) then there is code in one object (the container) which calls methods on the other (contained) objects to perform whatever actions are required to maintain that relationship. The more objects which are in this container then the more complicated is the code. It also means that in the container class each contained object is defined as a property, just like the table's columns.
The phrase the member-end of an association corresponds to a property of the associated class
is interpretted to mean that in a parent-child relationship the parent object must have a property which is an object of the child. This does not make sense to me. The only properties (variables) which belong to a database table are its columns. The database does not contain pointers to rows in a child table, so why should the software representation of a table contain pointers to instances which represent rows in a child table. There is no dependency between the parent and child objects as the tables which they represent are independent entities in the database. It is not necessry to "go through" one to get to the other. The child table is not a dependent of the parent table, and therefore a candidate for dependency injection, they are both independent entities.
In the RADICORE framework if there is a parent-child relationship between two entities (tables) then the parent object does not contain instances of the child object:
The $parent_relations array can be used when constructing SELECT queries to insert SQL JOINS in order to retrieve one or more columns from a parent table.
The $child_relations array is used in any DELETE operations to carry out any referential integrity requirements.
Databases do not have "associations", they have relationships. A relationship is between 2 tables (relations) where one is regarded as the parent and the other is regarded as the child. The existence of a relationship does not require the parent table to store a references to particular rows in the child table, instead it requires the child table to store a reference to the parent in the form of a foreign key whose columns have a logical link to corresponding columns in the primary key in the parent table. This is also known as a "one-to-many" relationship because the parent can have many related rows on the child table, but the child can only link back to a single row on the parent table. In an Entity-Relationship Diagram (ERD) this is often depicted as shown in Figure 4:
Note that the column names used in the child's foreign key need not be the same as the names used in the parent's primary key, but the types and sizes of each column in the foreign key must be the same as the corresponding column in the primary key. Note also that a table can be related to any number of child tables and also to any number of parent tables.
There are certain phrases in those definitions provided in the Introduction which do not reflect the way in which parent-child relationships in a database actually work, so I ignore them as the implementations that they suggest would be incomplete and inadequate.
The phrase The member-end of an association corresponds to a property of the associated class
implies that the parent object must contain a property/variable which points to an instance of an entity on the child object. In other words it must point to a particular row, or rows, within the child table. This is not how it is done in the RADICORE framework. The parent object does not contain any objects which represent rows on a child table, nor does it hold the primary keys of any rows on the child table. All it does is provide the identities of any child tables as well as the identity of the foreign key field(s) which can be used to access the related rows in the child table. This information is held in the $child_relations array. There is also a corresponding entry in the $parent_relations array of the child entity which identifies all the parent relationships which may exist for that child entity.
The phrase allows one object instance to cause another to perform an action on its behalf
implies that in any parent-child relationship you must go through the parent object in order to access the child. This is often interpretted as meaning that you must have a method in the parent object which will allow you to access the child object. This is not the interpretation that is used in the RADICORE framework. It is possible to achieve the act of "going through" in two ways:
It would appear that most programmers are taught to do the former while I have learned the advantages of the latter. Before accessing a child table all that may be necessary is to convert the primary key of the parent into the foreign key of the child, and how and where this conversion is done is a matter for the individual programmer. I say "may" as it is possible to read from a table which has one or more parents without specifying any foreign key values. When writing to such a table it is not necessary to "go through" the parent object to provide the foreign key value as the only requirement is that a value for any non-optional foreign key column is provided. How that value is provided is a matter for the the developer and not the author of any programming principle, especially when that author has little or no knowledge of writing database applications. I do not use custom code inside a parent entity to access a child entity, instead I use generic code within a controller, such as that used in the LIST2 pattern, to access the two entities separately.
In the RADICORE framework none of my table classes contain properties which are set to instances of any child objects, which means that access to those child objects cannot be performed by calling methods on those instances. However, the existence of relationships with child tables is recorded in the $child_relations property and the existence of relationships with parent tables is recorded in the $parent_relations property. It is standard framework code that will use this metadata to instantiate and communicate with those related objects, not customised application code.
In the RADICORE framework the most common method of "going through" the parent in order to access the child is using a task which is built using the LIST2 pattern. In this pattern the Controller will first retrieve one or more rows from the parent object and display them one at a time with a scrolling area. It will extract the primary key of the current row, then it will call the getForeignKeyValues() function to convert that primary key to the foreign key of the child. It will then access the child object using the foreign key as a filter. If it is not possible to use this method to provide the value for a foreign key before the ADD screen is activated, such as when a table requires an additional foreign key, then another approach would be to use the Data Dictionary to set the Control value for that foreign key column to a POPUP button. When this is pressed at runtime it will activate a POPUP form which will allow the user to pick a row from the parent table, thus ensuring that a valid primary key is chosen.
Instead of "going through" the aggregate root I record its identity by creating a primary key on each child table which includes the primary key column of its parent table. This produces a compound or composite key.
The following types of relationship are possible:
| One-to-Many | This is where the child table has a primary key and a separate foreign key. Each parent in this type of relationship can have zero or more children, and the child can have no more than one parent. | |
| One-to-One | This is where the foreign key on the child table is exactly the same as its primary key. Each parent in this type of relationship can have no more than one child, and the child can have no more than one parent. | |
| Many-to-Many | This is often shown using the image to the right, meaning that "many of entity A can be related to many of entity B". This arrangement is not valid in a database. |  |
| Instead it has to be implemented as a pair of one-to-many relationships using an additional intersection table as shown as entity "X" in the image to the right. This intersection table then requires a separate foreign key for each of the parent tables, and a primary key which is comprised of both foreign keys in order to prevent the same combination of foreign keys from being added more than once.
Further thoughts on this type of relationship can be found at How to handle a Many-to-Many relationship - standard. |
 |
|
| Multiple | This is where a child table has more than one foreign key which pointing to the same parent table. It has two variations:
|
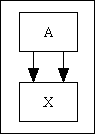 |
| Self-referencing | This is where a table is related to itself. In this case the name(s) of the column(s) in the foreign key must be different from the name(s) of the corresponding column(s) in the primary key. No row should be related to itself.
Further thoughts on this type of relationship can be found at How to handle a Many-to-Many relationship - Self-Referencing. |
 |
| Optional | This is where a row in the child table can exist without a reference to an entry in the parent table. This is done by designating each column in the foreign key as NULLable instead of NOT NULL. The relation_type on the DICT_RELATIONSHIP table should also be set to NULLABLE so that when an entry on the parent table is deleted the foreign key on all related child entries is set to NULL. |
Regardless of how each of these different types of relationship will be handled in the application, in the database they require nothing more than a link between a foreign key on the Many/Child table and the primary key on the One/Parent table. All the necessary processing is carried out by the framework by means of code in the Controller, the View and the abstract table class which is inherited by every Model (table subclass).
Note that it is possible for a foreign key to exist without a foreign key constraint, in which case all referential integrity must be carried out within the program code.
Prior to switching to PHP I had developed many applications and had dealt with hundreds of tables and relationships, so I knew what had to be done and how to do it. When I saw the code samples written by OO "experts" what immediately struck me was that their solutions were totally different, more convoluted and more complicated than mine. It became quite obvious to me that these people had no prior experience of database applications, had no experience of dealing with different kinds of relationships, but had come up with theories of how it could be done in a OO way without understanding how it had actually been done in non-OO languages. This lack of understanding led to a totally different approach:
In the RADICORE framework every relationship, regardless of its flavour, is defined in exactly the same way:
It is not necessary for a developer to insert custom code into a table class to access a related table as this is handled automatically by the framework, either in a controller script which handles related tables (such as the LIST2 pattern) or standard code within the abstract table class.
There are two ways in which the two tables in a parent-child relationship can be viewed, as shown in Figure 5 and Figure 6:
In this view, used by the LIST 2 pattern, the two tables have separate zones in the screen, and each zone is subject to its own set of method calls. A row from the Parent table is read first, and the primary key is extracted and converted into the equivalent foreign key for the Child table using the getForeignKeyValues() function which is called from within the Controller. This is then used as the $where string to read associated rows from the Child table. Note that with this pattern it is impossible to access entries on the Child table without first going through an entry on the Parent table.
In this view, which is common to all Transaction Patterns, there not a separate zone for the Parent table as the SELECT statement which is generated for the Child table will be customised to include one or more columns from the Parent table by means of an SQL JOIN. This can either be done manually by inserting code into the _cm_pre_getData() method, or you can get the framework to do this for you using the mechanism described in Using Parent Relations to construct sql JOINs. This means that all the data from both tables can be retrieved using a single call to the getData() method on the Child table.
It is precisely because I use a single $fieldarray variable to hold the table's data that I can include any number of columns from any number of tables. This avoids the restriction of only being able to display columns from a single table if I were to define each column as a separate variable with its own getter and setter.
There are some programmers who have been taught that every table should a technical or surrogate key called "ID" whose value comes from a numeric sequence. I was taught differently. If a table has a semantic or natural key which is guaranteed not to change over the lifetime of that record then it is not necessary to create an artificial key. It also avoids the overhead of creating two unique keys - one for the column called "ID" and another for the column containing the natural key.
Some programmers are also taught that a primary key should not be comprised of more than one column. I was taught differently. In a relational database a primary key can be comprised of any number of columns, but use your common sense and don't go overboard. For example, if I have a hierarchy of tables called Parent -> Child -> Grandchild I would probably use the following primary keys and foreign keys:
| Table | Primary key | Foreign key |
|---|---|---|
| Parent | parent_id | |
| Child | parent_id+child_id | parent_id (links to Parent) |
| Grandchild | parent_id+child_id+grandchild_id | parent_id+child_id (links to Child) |
An experienced SQL developer would know that in this example it would not be necessary to create an index for the foreign key as that is already covered by the leading columns in the index for the primary key.
In a real world example of Order -> Order_Item -> Order_Item_Feature
| Table | Primary key | Foreign key |
|---|---|---|
| Order | order_id | |
| Order_Item | order_id+order_item_seq_no | order_id (links to Order) |
| Order_Item_Feature | order_id+order_item_seq_no+feature_id | order_id+order_item_seq_no (links to Order_Item) |
| feature_id (links to Product_Feature) |
I am using a technical key called order_item_seq_no on the Order_Item table as it does not have a suitable natural key. While some inexperienced developer may think that product_id could be used that is not the case. It is possible for the same Order to have several Order_Item entries for the same product_id, but with a different combination of Product_Features
Whenever a user transaction is executed it does not involve code in a single module, it uses several modules, namely a Model, View, Controller and DAO, which work together in harmony, like those shown in Figure 2. While the Model contains a number of different methods it is the Controller which controls which methods are called in which sequence and with what context. This means that some of the logic for a user transaction is contained within the Controller instead of being completely within the Model. It is only after having worked on thousands of user transactions that I have been able to notice patterns of behaviour that have been repeated for different database tables, and I have managed to abstract out these patterns into a set of reusable controllers which are contained within my library of Transaction Patterns.
In my previous language, called UNIFACE, there was no separate Controller and View as these were both combined into a single component in the Presentation layer which communicated with one or more components in the Business layer. There was a separate component in the Business layer for each entity (table) in the Application Model. While each of these entities identified the table structure and the business rules they did not contain any code to deal with relationships as this was handled exclusively in the Presentation layer. If two tables were linked in a parent-child relationship then those two tables were painted in the screen, one inside the other, so that at runtime the UNIFACE software would first read the outer entity, then use the relationship details in the Application Model to convert the outer's primary key into the inner's foreign key so that it could then read the associated rows from the inner entity. This behaviour was logical and simple, so I duplicated it in my PHP code by putting the necessary code in my Controllers where it could be shared with any number of related entities instead of having to insert specific code inside each entity.
In the RADICORE framework each table has its own class, but none of these classes contains either properties or methods to deal with any relationship. Instead the existence of each relationship is identified in either the $parent_relations property or the $child_relations property of the two tables which are involved in that relationship. This information is then used by different components within the framework to deal with that relationship in the appropriate manner. Typically this involves creating a user transaction from a Transaction Pattern which has been designed specifically for that flavour of relationship. While a large number of tables can be maintained using the family of transactions shown in Form Families, others may require a different set of patterns. For example, in those cases where a child table requires the existence of a row in a parent table, because it contains one or more foreign keys, there are two possible approaches:
This pattern will use two entities - the parent (or outer) at the top with the child (or inner) below it. This pattern operates by calling the getData() method on the parent/outer entity using whatever selection criteria which was passed down from the previous screen, which is usually a LIST1. It will display only one row at a time for the parent entity from which it will extract the primary key. It then calls the getForeignKeyValues() function to construct a WHERE string for the foreign key of the child/inner entity using this primary key. This will be used to call the getData() method on the child entity to retrieve as many rows which are available to fit into the screen, subject to the user-defined page size. To create a new entry on the child table the user presses the navigation button labelled 'NEW' which will activate a task which uses the ADD2 pattern. This will then use that WHERE string to populate the relevant foreign key field(s).
This is used when the value for the foreign key is not passed down from the previous screen, in which case the user must supply it manually. Instead of using a textbox control on the HTML form a popup button ![]() will be shown instead. The user presses this button in order to activate a separate POPUP form which will display a list of entries from the parent/foreign table and wait for the user to select one and press the CHOOSE button. This will cause the primary key of the selected entry to be passed back to the ADD2 screen where it will be used to populate the foreign key fields.
will be shown instead. The user presses this button in order to activate a separate POPUP form which will display a list of entries from the parent/foreign table and wait for the user to select one and press the CHOOSE button. This will cause the primary key of the selected entry to be passed back to the ADD2 screen where it will be used to populate the foreign key fields.
Note that there are several different patterns which may be used to deal with many-to-many relationships.
Referential integrity checks the validity of the link between the foreign key and the associated primary key in order to ensure that data integrity is maintained. In the RADICORE framework's Data Dictionary each relationship has a type column which specifies how the relationship is to be treated when deleting entries from the parent/senior table. This has the following options:
If a foreign key constraint has been defined within the DBMS then the framework will do nothing and allow the DBMS to take the necessary action.
While foreign key constraints are processed by the DBMS during insert, update and delete operations, they are totally ignored when performing a SELECT query. However, the RADICORE framework can utilise the contents of the $parent_relations array to automatically retrieve columns from a foreign/parent table during a getData() operation. This is described in Using Parent Relations to construct sql JOINs.
Martin Fowler defines an aggregate as follows:
Aggregate is a pattern in Domain-Driven Design. A DDD aggregate is a cluster of domain objects that can be treated as a single unit. An example may be an order and its line-items, these will be separate objects, but it's useful to treat the order (together with its line items) as a single aggregate.
An aggregate will have one of its component objects be the aggregate root. Any references from outside the aggregate should only go to the aggregate root. The root can thus ensure the integrity of the aggregate as a whole.
Aggregates are the basic element of transfer of data storage - you request to load or save whole aggregates. Transactions should not cross aggregate boundaries.
While I agree that the components of an aggregate are separate objects, just like those shown in Figure 7 and Figure 8, I do not agree that the components of the aggregate should be accessed through an aggregate root. This concept does not exist in the database, and has never existed in any software which I have worked on in the last 40 years. No table in a database has any special operations to deal with related tables, so I do not see any reason to put any special methods in any table class to deal with those relationships. It is an alien and artificial concept which does not exist in my universe. I cannot see any advantages of going through an aggregate root, only disadvantages. When retrieving data from two tables there are only two options:
The way that I deal with relationships is through standard code which is built into components in my framework. OO theorists like to over-complicate matters with the following distinctions:
In relational theory it is much simpler than that. A relationship between two tables is signified by one table having a foreign key which points to the primary key of the other table. All accessing is performed using the standard CRUD operations. A composition is achieved by setting all the foreign key fields to NOT NULL, in which case the child row must always contain a reference to a row that exists on the parent table. By setting the type in Referential Integrity to CASCADE all the child records will be deleted when the parent is deleted. An aggregation is achieved by setting all the foreign key fields to NULLable, in which case the child row either contains a reference to a row on the parent table or it does not contain a reference at all. By setting the type in Referential Integrity to NULLIFY all the child records will be updated when the parent is deleted.
In my experience this thing called an object aggregation is nothing more than a collection of parent-child relationships which can be arranged into a hierarchy which could be several levels deep, such as parent-child-grandchild-greatgrandchild-whatever. Two types are supported in the RADICORE framework:
A Composition implies that the contained class cannot exist independently of the container. If the container is destroyed, the child is also destroyed. This is represented in a database by having a separate table for each child, and each row in the child table has a foreign key, which is set to NOT NULL, which relates it to a row in its parent table. Thus a child row cannot be created without providing a value for that foreign key.
Figure 7 - an aggregate ORDER object (a fixed hierarchy)
")
In this hierarchy none of the rows in a child table in any relationship can exist without a corresponding row in the parent table. If a parent is deleted then all of its children must be deleted. Each of the objects in the above diagram is a separate "entity" with separate structures and separate rules, therefore each will have its own class. Note that while each table class knows of the existence of any immediate parent or child tables, it has no knowledge of any other tables which may be related to those parent or child tables.
This collection of tables is joined together to form a fixed hierarchical structure. An inexperienced person would look at this collection and immediately think that it is so unique that it requires a special non-repeatable solution. However, a more experienced person, one who has been trained to look for repeating patterns which can be turned into reusable code, should to able to see something which is quite obvious - this collection contains ten pairs of tables which are joined in a one-to-many/parent-child relationship, and every such relationship will always be handled in exactly the same way. No row can exist in the child table unless it contains a foreign key which contains the primary key of a row in the parent table, and the RADICORE framework has a standard method for dealing with foreign keys. This means that I can deal with this collection of tables by creating 66 tasks which use the following Transaction Patterns:
It is the use of the ADD2 pattern which ensures that no child record can be created without a reference to its parent record.
The only time I would want to read all the data from all of these tables would be if I wanted to produce a printable copy of the entire order, in which case I would construct a task based on the OUTPUT3 pattern.
The idea that I should be forced to go through the aggregate root in order to access any component within the aggregation is also handled differently. Instead of creating a class to handle the responsibilities of the aggregate root I can achieve the same effect by only allowing the LIST1 task for the root table, which is this example is ORDER-HEADER, to be accessible from a menu button. All the LIST2 tasks for each child table are only accessible from a navigation button on the parent task. This means, for example, that you would have to go through both the ORDER-HEADER and ORDER-ITEM tasks before you can access any ORDER-ITEM-FEATURE entries.
Some OO afficionados might spot that this arrangement, where the ADD1 task for the ORDER_HEADER table is totally separate from the ADD2 task for the ORDER-ITEM table, allows me to create an ORDER_HEADER record without any corresponding ORDER_ITEM records, which would technically be invalid. My logic for doing it this way is that it would be far too cumbersome for the user to enter data for the entire order using multiple screens before pressing the SUBMIT button, so I separate the data into one screen at a time so that the order can be built up incrementally. When the ORDER-HEADER record is first created it has an order_status which is set to "Pending", and while it has this status the user can make whatever additions, deletions and corrections to any part of the order as is necessary. Once the user is satisfied that all the details have been entered correctly he can change the order_status to "Complete", but this will not be allowed if there aren't any entries on the ORDER-ITEM table. Once the order comes out of the "Pending" status no further amendments will be allowed to any part of the order except to advance the status to the next value.
Note that in this particular hierarchy the only child table in any relationship which is required is the ORDER_ITEM table. All others are entirely optional. If an entry on a Parent table is deleted then all related entries on the Child table will also be deleted.
What is not shown in Figure 7 is that the ORDER-HEADER table has an additional foreign key to the CUSTOMER table, and the ORDER-ITEM table has an additional foreign key to the PRODUCT table. These are handled using a POPUP button.
An Aggregation implies that the contained class can exist independently of the container. If the container is destroyed, the child is not destroyed as it can exist independently of the parent. Martin Fowler has this to say on the subject of aggregates:
An aggregate will have one of its component objects be the aggregate root. Any references from outside the aggregate should only go to the aggregate root. The root can thus ensure the integrity of the aggregate as a whole.
This wikipedia page has this to add:
Objects outside the aggregate are allowed to hold references to the root but not to any other object of the aggregate. The aggregate root checks the consistency of changes in the aggregate.
This is not how databases work. There is no such thing as an aggregate root which controls access to every member of that aggregation. An aggregation is nothing more than a collection of one-to-many or parent-child relationships, and the only "requirement" when accessing a relationship is that you obtain the primary key of the parent so that you can convert it to the foreign key of the child.
An aggregation is represented in a database by having a single table for the entities, and a separate table to identify the relationship between one entity and another. The "entity" table does not have any foreign keys for its parents, but the "relationship" table has two foreign keys to the "entity" table, one for the parent and one for the child. This allows for a row in the "entity" table to have zero or more relationships, so at the same time it can have zero or more parents and zero or more children. It is possible to delete a row on the "relationship" table without affecting any row on the "entity" table, but a row on the "entity" table cannot be deleted without first deleting all associated rows on the "relationship" table.
Figure 8 - an aggregate BILL-OF-MATERIALS (BOM) object (an OO view)
")
While a novice may see this as a collection of one-to-many relationships a more experienced person will recognise that not only can a CAR contain an ENGINE but the same engine (by which I mean a similar engine with the same specifications, not the same physical engine with the same serial number) may be contained in several other CARS. This results in what is known as a many-to-many relationship which is implemented by introducing an intermediate intersection or link table which then produces a pair of one-to-many relationships. This means that in this particular structure each of those entities is a record on the same table (in this example it is the PRODUCT table) while the relationship between one of those records and another is a record on the intersection table (in this example it is the PRODUCT_COMPONENT table).
I have seen the structure shown above in Figure 8 in several books on the OO design process where it shows an example of an object which is composed of (or comprised of or acts as a container for) other objects to form a hierarchy which could be many levels deep. Each of these objects represents a separate class. This means that each of those classes would require built-in references to each of its immediate components. This also means that when the Car class is instantiated it also instantiates the Engine, Stereo and Door classes which, in turn, instantiates the Piston, Spark Plug, Radio, Cassette and Handle classes.
In a database application this is absolutely, emphatically, totally wrong. None of the different products has its own class, it has its own row in the same PRODUCT table, and each row in a table shares/inherits the same structure and behaviour as every other row in that table. There is nothing within the PRODUCT class which identifies a row as being either a container or being within a container - this would require the use of a separate PRODUCT_COMPONENT table to implement a many-to-many relationship, as shown in in Figure 9 below, which could then be viewed and maintained using separate tasks.
In the RADICORE framework there is no need for a developer to insert custom code into a table class to access a related table as this is handled automatically by standard code within the framework. It is only necessary to identify the existence of each relationship within the DATA DICTIONARY so that it appears in the $child_relations array of the parent and the $parent_relations array of the child.
Figure 9 - an aggregate BILL-OF-MATERIALS (BOM) object (a database view)
")
This is a pair of tables which form a many-to-many relationship where both foreign keys on the intersection (child) table refer back to the same parent table. This produces a recursive hierarchy which can extend to an unknown number of levels as each parent can have any number of children, and each of those children can also be a parent to its own collection of children, and so-on and so-on. This produces what is commonly known as a Bill Of Materials (BOM).
With this arrangement an entry on the PRODUCT table can exist without any entries on the PRODUCT_COMPONENT table, but the reverse is not true. You cannot insert an entry into the PRODUCT_COMPONENT table without specifying the identities of two different rows in the PRODUCT table. There is no logic in the PRODUCT class which deals with the contents of the PRODUCT_COMPONENT table, just two entries in the $child_relations array. Similarly there is no logic in the PRODUCT_COMPONENT class which deals with the contents of the PRODUCT table, just two entries in the $parent_relations array.
Note that in this particular hierarchy although the effect is to relate one PRODUCT to another there is no direct relationship between the PRODUCT table and itself, instead there is an indirect relationship through the PRODUCT_COMPONENT table which is known as an intersection/link table. An entry cannot exist on this Child table without corresponding entries on the Parent table. If an entry on this Child table is deleted it has no effect on the related entries in the Parent table.
In this example the PRODUCT table contains a primary key called product_id while the PRODUCT_COMPONENT table has the following structure:
| Field | Type | Description |
|---|---|---|
| product_id_snr | string | Identifies the parent (senior) product in this relationship. Links to an entry on the PRODUCT table. |
| product_id_jnr | string | Identifies the child (junior) product in this relationship. Links to an entry on the PRODUCT table. |
| quantity | number | Identifies how many of this product are required in the parent product. |
Note that product_id_snr and product_id_jnr are separate foreign keys which both link back to the same PRODUCT table. They are also combined in the primary key to ensure that the same combination is not used more than once. This forms a recursive hierarchy as it can contain more than the two levels which are indicated by the two tables.
Note also that products can be added or removed from the PRODUCT_COMPONENT table without affecting the contents of the PRODUCT table. While the PRODUCT table can be maintained with a forms family starting with a LIST1 pattern, the PRODUCT_COMPONENT table would be maintained by a forms family starting with the LIST2 pattern. This would show as its parent entity the product that was selected in the PRODUCT table's LIST1 screen, and below it would appear that product's immediate children. To see the entire hierarchy in a single screen you would create a task using the TREE2 pattern, or you could export it to a spreadsheet using the OUTPUT6 pattern.
This shows that the two tables can be handled independently of each other. The fact they they are related is built into the database structure which is then copied into the $child_relations and $parent_relations arrays of each table class. The rule that says that an entry on the PRODUCT table cannot be deleted if it has any entries on the PRODUCT_COMPONENT table is enforced by the framework using the settings in the $child_relations array. The rule that an entry cannot be added to the PRODUCT_COMPONENT table without supplying valid values for two entries from the PRODUCT table is enforced by the ADD2 task where the identity of product_id_snr is passed down from the parent entity in the LIST2 task and the identity of product_id_jnr is selected from a POPUP task.
I have been told more than once that my practice of creating a separate class for each database table is not good OO. I have been told that each entity in the real world has to have its own class, and if its data needs to be spread across multiple database tables then that is a problem with the database which can be ignored as it can be dealt with using a Object-Relational Mapper. They seem to think that objects such as ORDERS (see Figure 7) and PRODUCTS (see Figure 8) should be handled within a single class, and all associations must be handled by going through the aggregate root. As I had never been taught this nonsense I never acted upon it for the simple reason that databases do not have "associations" in the OO sense, they have relationships where the only requirement is that the child table has a foreign key which refers to the primary key of a row in the parent table. In a database I do not have to go through the parent table in order to access a child, so I never put code in the parent's class to access any of its children. If I want to show data from the parent table and a child table in the same screen then I create a task based on the LIST2 pattern which accesses those two table independently.
This means that I never read data from a table until I actually want to show it on a screen as to do otherwise would be a waste of time. I only ever read data from a table when the user actually requests a task which displays or processes data from that table. This seems sensible to me, but there are others out there who seem to think that when dealing with an aggregation every member is a property of the aggregate root and should be instantiated and loaded with data whenever that root object is created. I remember reading a newsgroup post several years ago from someone who had written an application for his school. In his database he had a group of related tables called SCHOOL, TEACHER, STUDENT, ROOM, SUBJECT and LESSON, but he was complaining that his application was taking too long to load. It turned out that when he instantiated the SCHOOL class he was also instantiating all the other classes and loading in all their data even though it wasn't actually required. No competent database programmer would ever do it this way. Nobody would ever load that much data into a single object as it would never be displayed to the user in a single screen. He needed to stop loading all his data into a single object and concentrate on building separate tasks to display the contents of each table when it was actually required, and then only reading from the database that data which can fit into a single screen. This is precisely what I had done in a similar application called a Prototype Classroom Scheduling Application which is available in the download of my RADICORE framework. You can also run it online as an option under the "PROTO" menu so you can for yourself how quick it is to display the contents of different tables.
While many people have different answers to the question What is OOP? the only definition which satisfies me is:
Object Oriented Programming means writing programs which are oriented around objects. Such programs can take advantage of Encapsulation, Inheritance and Polymorphism to increase code reuse and decrease code maintenance.
The key phrase there is increase code reuse
, so to measure the success of your OO implementation all you need to do is measure the amount of reusable code in your application. Such things as following best practices or filling your code with unnecessary design patterns count for diddly-squat if you only have tiny amounts of reusable code. Years ago I remember one of my critics (of whom there are many) questioning why I always seemed to be bragging about how much reusability there was in my framework. This person was obviously a clueless newbie who would never become a rock star programmer and forever remain as a code monkey. To those of us who have IQ's which are greater than our shoe size the benefits of having reusable code are blindingly obvious:
Being productive is the key here. If you can produce software quicker and therefore cheaper than your rivals then the more competitive you will be in the eyes of your customers. This is a lesson which I learned while working for software houses as we earned our living by writing bespoke systems for new customers, but first we had to have a bidding war against rival software houses. Being able to produce a finished product in a shorter timeframe and at a lower cost would always give us an advantage. Being slow and expensive was never a winning combination.
So exactly how much reusable code is there in the RADICORE framework? Instead of lines of code I prefer to use the number of components. Below in Figure 10, which is an expanded version of Figure 2, you will see all the possible components:
Figure 10 - Components of the RADICORE framework
")
Note: each of the boxes in the above diagram is a clickable link.
The following components are those which are built into the framework and available for instant reuse:
The following are generated from within the Data Dictionary:
The following are generated at runtime:
The following features are available when you run your application components:
Having small amounts of reusable code will only be able to save you small amounts of time, so the more you have the bigger the savings and the more productive you will be. When building the components for an enterprise application you can make great savings by utilising a framework that was specifically designed for such applications, such as RADICORE. Here are the savings you can make because of the things you don't have to do:
Some people seem to think that the way that you design an application depends on the language you will use to implement it, that designing for an OO language is totally different from designing for a procedural language. I disagree. While working for various software houses in the past I would often visit a potential client to gather the requirements for a new system which they wanted, usually to replace an old system which was becoming more of a hindrance than a help. The requirements often started with "more management reports", so we would make a list of what reports they needed and what data needed to be included in each report. From this we would start designing the database which would provide the data for each report. In the 1980s a lot of these reports were printed on paper, but nowadays they are either provided as online screens, spreadsheets or PDF documents.
Having identified the data outputs and the data storage we then had to identify the data inputs. The end result was what is known as a logical design as it existed only on paper. This contained a preliminary database design plus a list of user transactions (tasks) which will would allow the users to insert, update and display that data. Each transaction was rated on its complexity which included the number of tables it needed to access, how they would be accessed, and what business rules needed to be implemented. Part of this process was to trace each piece of data from its input, its storage and it output to ensure that we knew were it came from and where it was going. The data structures were also put through a process known as Data Normalisation to ensure that they could be access as efficiently as possible.
This logical design, still in paper form, would then be discussed with the client to ensure that it met all of their requirements. The next stage would be to produce the physical design which would identify the hardware requirements, which DBMS would be used, and the choice of development language and possibly development tools such as frameworks. The volume of data which would be input each day would be used to judge the size of the database, and the number of users who would access the system at the same time would be used to judge the size of the CPU. Database backups and archiving strategies would also add to the hardware costs. The number of transactions and their complexity could be used as a guide to the development costs. Note that the cost of building a piece of software remains the same regardless of how many times it is run, whether it be a thousand times a day or just once a month.
This design process remained the same regardless of the development language for the simple fact in a database application the most important part is the database design closely followed by the requirements of all the user transactions that will be necessary to move the data into and out of the database. It is the software itself which is the implementation detail. This means that I do not need to design the software separately using either Object-Oriented Design (OOD) or Domain-Driven Design (DDD) as everything can be built using standard patterns. By not using two incompatible design methodologies my software structure is always in sync with my database structure, so I avoid the problem known as Object-relational Impedance Mismatch which then means that I do not have to work around that problem by using that abomination of a solution called an Object-Relational Mapper (ORM). Prevention is always better than cure.
Most programmers overuse inheritance by creating deep class hierarchies and inheriting from one concrete class to create another concrete class. The practice which I followed instinctively, which was later backed up by the experts, was to only inherit from an abstract class. I knew from my previous experience that every table in the database should be treated as a separate entity, and that because every table is subject to the same CRUD operations that the code for these operations could be placed in an abstract table class so that it could then be inherited and shared by every concrete table class. The use of an abstract class then enabled the use of the Template Method Pattern so that I could place custom code inside "hook" methods within each concrete table class to override the standard processing.
The abstract table class is supplied as part of the framework, and every concrete table class which is generated from the Data Dictionary will automatically inherit from this abstract class.
The only time I ever create a subclass of a concrete table class is when I need to provide a totally different implementation in any of the "hook" methods. For example, in the DICT subsystem I have the following class files:
As far as I am concerned all the necessary design patterns have been built into my framework. I started off by using the 3-Tier Architecture, but because I ended up by splitting the presentation layer into two separate components a colleague pointed out that this was also an implementation of the MVC design pattern. This resulted in a four-part structure which is shown in Aren't the MVC and 3-Tier architectures the same thing? The four components are as follows:
All the public methods in the abstract table class implement the Template Method Pattern which include "hook" methods so that custom logic can easily be added to each concrete table class.
Every concrete table class follows exactly the same pattern, so it can be constructed by the framework and not by the developer. As each of these classes represents a different database table it can use that table's details which already exist in the database schema. Each class file can be generated by the framework's Data Dictionary in two simples steps:
If a table's structure ever changes all that needs to be done is to repeat the import and export process which will cause the structure file to be recreated. The class file will not be overwritten as it may have been modified to include code in customisable "hook" methods. The customisable methods will need to be changed manually, but only if these mention any of the changed columns.
Each class represents a different database table, and as each table is subject to exactly the same operations as every other table all the common methods and properties have been predefined in the abstract table class. These are the methods used by each Controller to communicate with each Model.
Because all the data, both incoming and outgoing, is held in an array of variables called $fieldarray, which is defined in the abstract table class, I don't have to spend time in defining a separate variable for each column, nor do I have to build a separate getter and setter for each column.
I do not need to define a separate method for each user transaction as every transaction follows the same pattern in that it performs one or more CRUD operations on one or more tables, so it is the Controller's job to call the relevant method on the relevant Model. Each user transaction has its own component script in the file system, and it is this tiny script which identifies which Model(s) are to be used with which Controller for that transaction.
Each table class contains standard code which is inherited from the abstract class, and while this is sufficient to handle the transfer of data from the User Interface (UI) to the database and back again, and the primary validation to ensure that for inserts and updates each value is compatible the column definition in the database, it may be necessary to add custom code at different points in the processing cycle. This can be done by inserting the relevant code into the "hook" methods which have been built into the abstract class but which can be copied into each table class.
The primary validation requirements for each column in a table are defined in the $fieldspec array which is made available in the <table>.dict.inc file which is exported from the Data Dictionary. All user input comes in as an associative array, such as $_POST, where the column values are keyed by the column name. The abstract table class then uses a standard validation class to verify that each of the values in the data array matches that column's specifications in the specifications array.
Secondary validation can be carried out by adding custom code into the relevant "hook" methods.
This topic is discussed further in How NOT to validate data.
Object associations are nothing more than relationships where each relationship involves a foreign key on a child table which refers to the primary key on a parent table. Dealing with each relationship does not require extra code in any Model, it requires standard code in a Controller which deals with the two entities and handles the movement of the parent's primary key to the child's foreign key. This is why I created the LIST2 pattern.
Object aggregations are nothing more than a hierarchy of parent-child relationships, so it is easier to deal with each pair of tables in a separate user transaction instead of having custom code to deal with the entire collection of relationships.
A large number of programmers seem to think that each Model class needs its own Controller simply because each Model is given its own unique set of method names, which include the setters and getters for all the individual table columns. This means that the Model is tightly coupled to the Controller and the Controller is tightly coupled to the Model. This means that neither can be reused with other objects which indicates a deficiency in the design. I have cured this deficiency by making the communication between Controllers and Models to be as loosely coupled as is physically possible by having each Model use the same set of methods and by eliminating the use of getters and setters. This means that by using the power of polymorphism I can use any Controller with any Model.
Each Controller performs a fixed set of operations on a fixed number of Models and produces a different View, as described in Transaction Patterns, and by using the power of Dependency Injection the same Controller can perform the same set of operations on whatever Model it is told to use.
I decided from the outset that instead of building each HTML document from scratch for each user transaction that it would be better to use a template engine as I had already noticed a repeating pattern of structures with the only different being the content. I had already become familiar with the use of XML and XSL, and having proved to myself that both could be used easily with PHP I stuck with that as my templating engine. I started with a separate XSL stylesheet for each screen, but after several cycles of refactoring I managed to produce a small library of reusable XSL stylesheets which could be used for any screen in the application. While the same template can be used to display the data from different Models, the different data names are supplied at runtime using a separate screen structure script. The contents of this small script, which can be modified by the developer, are copied into the XML document so that they can be processed by the XSL stylesheet during the transformation process.
The construction of the XML document is common to all web pages so can be supplied in a single reusable object. The only variables required at runtime are supplied by the screen structure script. This is built by the framework when the user transaction is generated from the Data Dictionary, but it can be amended by the developer to customise the screen when required.
All the following areas in a web page are automatically supplied by and handled by the framework:
If you have to write such code yourself then you know what a burden it can be. Now imagine not having to write such code to achieve all this functionality.
Anyone who has written SQL queries for any length of time will tell you that they all follow a standard pattern with the only differences being the table and column names. While default SQL queries for INSERTs, UPDATEs and DELETEs are built automatically by the framework it is possible to customise the SELECT query by inserting code into the _cm_pre_getData() method which is one of the "hook" methods. The different parts of the query are then sent to the Data Access Object (DAO) where they will be assembled and sent to the selected DBMS using the relevant API.
Note also that there is a simple process to retrieve columns from a parent table by automatically adding JOINs to SELECT queries.
I have seen such a thing proposed more than once, such as in Decoupling models from the database: Data Access Object pattern in PHP, and I am always surprised, even shocked, that so-called "professional" programmers can come up with such convoluted and complicated solutions. In my mind that is the total opposite of what should actually happen. In my methodology I *DO NOT* have a separate DAO for each table, I only have a separate DAO for each DBMS (MySQL, Postgresql, Oracle and SQL Server) where each can handle any table that exists. If you understand SQL you should realise that there are only four operations that can be performed on a database table - create, read, update and delete - so why would I duplicate those operations for each table when I can have a single object to handle any table?
Some people question the necessity of having a swappable DAO as once chosen the application's DBMS is rarely changed. The words "once chosen" should provide a clue - the framework supports a number of DBMS engines, so its users are able to make their choice before they start development.
I have seen the instructions provided in other PHP frameworks for building new transactions, and I am amazed at how much effort is required. Too much manual effort, not enough automation.
In the RADICORE framework each user transaction requires the services of number of components - a Controller, one or more Models, and a View. Each Controller performs a particular set of operations on its Model(s) and is tied to a particular screen structure which is produced by a particular XSL stylesheet, with all the possible combinations described in my library of Transaction Patterns. Building a new transaction requires the following simple steps:
I started off by performing these tasks by hand, but this grew rather tedious over time so I decided to automate it by add some new functions to the Data Dictionary:
This function will then generate the relevant scripts and update the relevant tables in the MENU database. The new tasks are then available to be run. You can alter the screen layout by amending the screen structure file, and if necessary you can add "hook" methods to the table class file in order to apply additional business rules.
The only "difficulty" with this approach is deciding which Transaction Pattern to use in the first place, but as the framework download contains lots of samples this should become easier with experience.
In my early programming days there were no frameworks we could use, so everything had to be hard-coded and built from scratch. Once I had built my first framework with its own database this enabled these options to become more dynamic as they could be driven from the contents of various database tables. For example:
This is discussed further in A Role-Based Access Control (RBAC) system.
Other security features which are built into the framework are documented in The RADICORE Security Model.
It was common practice in my early programming days for all the menu screens to be hard-coded, which meant that they had to be designed and built up front, and any changes required that code to be amended. When I created my first framework in the 1980s I made the switch to a system of dynamic menus.
Each user transaction has its own record on the TASK table which then allows it to be added to either the MENU table or NAVIGATION-BUTTON table. The MENU table is used to create whatever menu structure is appropriate for your organisation.
When the contents of these two tables are displayed on the screen any tasks which are not accessible to the current user will be filtered out.
Using the RADICORE framework I am able to build new user transactions in minutes rather than hours because of my library of Transaction Patterns which provide all the boilerplate code which is necessary to put data into and get data out of the database. This leaves me with nothing to do but insert business logic into the pre-defined "hook" methods. It should therefore follow that when an analyst comes to write a detailed program specification for a programmer to follow that it should not be necessary to describe all that sharable boilerplate code as this never changes. It also has its own documentation. The description of each Transaction Pattern covers such things as the look and feel of any screens or reports and how the program should behave. All that should be necessary should be as follows:
Years ago I read a complaint from some novice programmer who said that OOP is not suitable for database applications and that changing a table's structure was a complicated and long-winded process as it involved changing method signatures and as well as all the places which called those signatures. In the 20 years that I have been building database applications using the OO capabilities provided by PHP I have never had such a problem, so I can only conclude that the problem does not lie with PHP or the principles of OOP but instead lies with the complainant's inability to make effective use of those capabilities.
I have been told time and time again by my critics that my methods are rubbish because I am not following "best practices", but I contend that the truth is the complete opposite, that my methods are superior simply because I do NOT follow those practices because I have found practices which are demonstrably better. I develop database applications where the software structure is always synchronised with the database structure, so I don't need to waste time with any Object-Relational Mappers. Instead I use my Data Dictionary to construct both the table class file and the table structure file. If I ever change a table's structure all I need to do is to re-import that table's structure into my Data Dictionary and then re-export that structure to replace the table structure file. I only ever have to amend code within a table class if an affected column is mentioned in any "hook" method. If I need to amend an HTML screen all I do is amend a screen structure file.
Before I switched to using PHP in 2002 I had 20 years of previous experience in designing and building enterprise applications, and this experience had taught me several valuable lessons. My one and only attempt at using UNIFACE to build a web application, which was designed by so-called "professionals" using all the latest "proper" and "fashionable" techniques, had turned out to be a complete disaster, so I decided to switch to a more suitable language. I chose PHP mainly because it was tailor-made for building web-based database applications instead of having internet capabilities bolted on as an afterthought. I liked the look of the code samples which I saw as they were simple, direct and effective. Another reason was that I could download all the necessary software - the PHP language itself, the MySQL database and the Apache web server - for free and install it on my home computer.
I did not go on any professional courses run by "experts", and I was not aware of any "best practices", so I started with the online PHP manual which taught me how to create classes, how to instantiate and use objects, and how to use inheritance to share code. I also used some online tutorials and bought several books to see examples of how the functionality provided by PHP could be brought together to build useful applications. I saw some ideas that I liked, some that I did not, and I experimented with new ideas of my own. I coupled this new found knowledge with what I had observed in the previous 20 years and used it to create my own PHP implementation. Judging by the amount of reusable code which I had produced and the corresponding increase in productivity I thought that my switch to using OOP with PHP had been a success,
As I had drawn inspiration from others who had published articles on the internet I decided to return the favour by publishing the results of some of my experiments on my own website in 2003. Some of the early articles were also published on the ZEND website, but one was rejected on the grounds that "real OO programmers don't do it that way". I started a thread in the comp.lang.php newsgroup in Google Groups in which I asked other PHPers their opinion, and the majority response was that everything I did was wrong and my code was an unmaintainable mess because I wasn't following "best practices". I gave up trying to argue my case in that newsgroup, so I published a response on my website in What is/is not considered to be good OO programming. This was followed a year later by In the world of OOP am I Hero or Heretic?
When I started researching these "best practices" to see if they could improve my code I quickly realised that they were actually no-to-best practices which would do nothing but reduce the amount of reusable code and thus destroy the purpose of using OOP in the first place. Apart from the fact that some of these practices and principles were written specifically for compiled and strictly-typed languages, which PHP is not, some of the interpretations of these principles were so bad I had to wonder how their perpetrators could possibly remain employed in this profession.
As far as I am concerned a practice can only be called "best" when it produces the best results. In the context of OOP that can be measured by the amount of reusable code you have at your disposal and the amount of code you DON'T have to write to get the job done. The less code you have to write then the quicker (and cheaper) you can get the job done. This is what makes you more productive and more attractive than your competitors who take twice as long and charge twice the price. If you look at the four major components of every user transaction in Figure 2 you should have noticed by now that NONE of those has to be designed and built by the developer who uses the RADICORE framework. The Controllers, Views and DAOs are pre-written and built into the framework while the Models are generated by the framework. These will already contain all the standard code which is inherited from an abstract class, which means that the only code left for the developer to write is for the business rules which can be inserted into the various pre-defined "hook" methods.
If you think that my claims of greater productivity are at best exaggerated or at worst a bare-faced lie then you should take this challenge. If you cannot achieve within five minutes with YOUR methods what I can achieve within five minutes with MY methods, all without writing a single line of code, then I shall conclude that any criticisms which you keep throwing in my direction are not worth the toilet paper on which they are written and that you are talking out of the wrong end of your alimentary canal. Instead of simply claiming that your methods are superior to mine I challenge you to prove it.
Here endeth the lesson. Don't applaud, just throw money.
The following articles describe aspects of my framework:
The following articles express my heretical views on the topic of OOP:
These are reasons why I consider some ideas on how to do OOP "properly" to be complete rubbish:
Here are my views on changes to the PHP language and Backwards Compatibility:
The following are responses to criticisms of my methods:
Here are some miscellaneous articles:
| 08 Mar 2026 | Amended Object Associations to state that I never have pointers in the parent entity which identify related rows in the child entity. |
| 06 Jun 2025 | Added Avoid premature abstractions. |
| 17 Nov 2024 | Replaced "Data Abstraction results in a concrete class" with Data Abstraction results in shared variables. |
| 27 Jul 2024 | Added Choosing a primary key
Amended the descriptions in Object Composition and Object Aggregation to be more explicit. |
| 07 Apr 2024 | Added A single class for an Aggregation is a mistake |
| 18 Oct 2023 | Added I don't need to waste time writing detailed program specifications
Added I don't need to waste time changing method signatures after changing a table's structure |
| 02 Oct 2023 | Added What is an "entity"?
Added Identifying areas of reusability Added NOT following the "rules" of OOP Added How much reusable code is best? Added How much time can be saved? |
| 11 Mar 2023 | Added Reusable Controllers |
| 04 Feb 2023 | Added Reusable Views |