This idea follows on from The Power of Component Templates which I wrote during my days working with the UNIFACE language.
Transaction Patterns are totally unrelated to and different from Design Patterns. Design Patterns are nothing but outline descriptions of solutions without any code to implement them. You have to provide your own implementations, and it is possible to implement the same pattern many times, each with different code. Design patterns have limited scope in that they can only provide small fragments of a complete program. Transaction Patterns, on the other hand, are different in that they actually provide pre-written components which are reusable out of the box. It is actually possible to build a functioning transaction by saying combine Pattern X with Model Y to produce Transaction Z
. It may only be able to perform basic validation, but it is very easy to add in custom logic for unique business rules later. Another difference is that Design Patterns are invisible from the outside as you cannot tell what patterns are embedded in the code when you run the software. This is not the case with Transaction Patterns - simply by observing the structure of the screen and understanding the operations that the user can perform with it you can determine which Pattern was used.
Although each user transaction is different - it performs a particular series of operations on a particular object or group of objects - after having written hundreds of user transactions the astute observer should be able to spot some similarities between certain transactions in that the same series of operations are being performed on a different set of objects. The first step to becoming an effective programmer is the ability to isolate the similarities from the differences. The next step is then to find a way to organise the similarities into patterns which you can turn into reusable and sharable code and thus avoid the need to duplicate the similar code over and over again.
It is because these patterns were designed to assist in the building of user transactions that I gave them the name Transaction Patterns. The remainder of this article explains my thought processes on this subject in greater detail.
An application is made up of a number of components or modules, each of which allows the user to complete a user transaction (aka task or unit of work) which in the business world is known as a "business transaction". When the first computerised business systems were implemented the term "transaction" was carried forward, and was used to describe a process whether it be performed manually or electronically. The same terminology has been adopted in the database world where a database transaction is that part of a computerised transaction which updates the database. These database updates are grouped into a logical unit by surrounding them with "start transaction" and "commit" instructions. Note that the Unit of Work design pattern describes a database transaction and not a business transaction.
A user transaction is therefore a module within a computer application which allows a user to complete a unit of work known as a "business transaction", and which may also include a "database transaction".
Bear in mind that unless you are developing software which directly manipulates a real-world object, such as process control, robotics, avionics or missile guidance systems, then some of the properties and methods which apply to that real-world object may be completely irrelevant in your software representation. If, for example, you are developing an enterprise application such as Sales Order Processing which deals with entities such as Products, Customers and Orders, you are only manipulating the information about those entities and not the actual entities themselves. In pre-computer days this information was held on paper documents, but nowadays it is held in a database in the form of tables, columns and relationships. An object in the real world may have many properties and methods, but in the software representation it may only need a small subset. For example, an organisation may sell many different products with each having different properties, but all that the software may require to maintain is an identity, a description and a price. A real person may have operations such as stand, sit, walk, and run, but these operations would never be needed in an enterprise application. Regardless of the operations that can be performed on a real-world object, with a database table the only operations that can be performed are Create, Read, Update and Delete (CRUD). Following the process called data normalisation the information for an entity may need to be split across several tables, each with its own columns, constraints and relationships, and in these circumstances I personally think that it would be wiser to create a separate class for each table instead of having a single class for a collection of tables.
In a typical CRUD application there are a number of form-based transactions which allow the user to view and maintain records within a database using the standard Create, Read, Update or Delete operations. A transaction may deal with a single occurrence from a single database table or may deal with several occurrences from several database tables. It may only read from the database, or it may perform a number of inserts, updates and deletes within a single operation.
Trying to describe an entire application, or the individual transactions which are contained within it in terms of the design patterns which may be used can be a pretty daunting task, similar to describing a physical structure in terms of the nuts, bolts, brackets and beams used in its construction. Design patterns are commonly used to describe individual facets of a transaction, and are primarily associated with just one of the many steps that exist between the user interface and the database. A typical combination is usually model, view, controller and data access object, but there may also be decorators, observers, helpers, singletons, mappers, facades, front controllers, page controllers, factories, proxies, et cetera, et cetera. What is needed is a method of describing a user transaction at a higher level of abstraction, to identify what it looks like and what it does rather than what low-level design patterns are used to implement the individual steps. This new type of pattern, this higher level of abstraction, is known as a transaction pattern.
A pattern can be defined as follows:
A pattern is a theme of recurring elements, events or objects, where these elements repeat in a predictable manner. It can be a template or model which can be used to generate things or parts of a thing.
So a pattern can be used to make complete duplicates of something, such as a mould in an industrial process which can reproduce copies of the same shape in large numbers. These things may be finished articles, or may need to be assembled into a finished article. It may take longer to create a pattern than to create a single article, but if you want large quantities of that article then the investment of creating a pattern provides you with the means of creating copies at a higher speed and/or lower cost.
If you need large quantities of something then it is more likely that the use of a template/pattern/mould will provide huge benefits, but even if you may only require the occasional copy, then the use of a pattern will guarantee some level of consistency with the original. If you build something from scratch each time there is the likelihood that it will be different from the original, especially if it is being built by a different person or different team. These differences may seem slight, but they could lead to problems.
Before the benefits of using a pattern can be realised there are certain obstacles that must be overcome:
If you do not overcome these obstacles then you will be forced to re-invent the wheel each and every time. In the case of software this means writing a new piece of code which does exactly the same thing as another piece of code. At best this may mean copying the original code and putting it in a different place, but at worst this may mean writing a new piece of code from scratch, and this new piece of code may perform differently or produce different results. The biggest drawback is that should it become necessary to change a piece of code then that change must be applied to all the copies of that piece of code, and it may be a difficult process to identify where all those copies exist. If software is written well there is no duplication of code, instead a piece of logic is built into a reusable module so that whenever that logic is required it is referenced from that module. Because there is only ever one copy of this code it means that changes need only be made to that single copy, and all the references to the module will automatically use the latest version.
This leads to the following questions:
As mentioned previously a CRUD application is used to maintain the contents of a database, and as a database may contain a large number of tables there may be transactions which do similar things but to different tables. This can lead to the following situation:
That phrase "does exactly the same thing" should trigger in your mind that there is something in common between these two transactions, and you should immediately be asking yourself "how much of the code in transaction #1 can I reuse in transaction #2?"
An inexperienced programmer may say that very little is reusable because each piece of code has a different set of object names hard-coded into it, but a wiser programmer will be able to see where that code can be converted into a subroutine which will accept a list of object names as parameters. That single subroutine can then be referenced any number of times with different lists to carry out that common processing on different objects.
Rather than look at the inside of a transaction, the code, for areas of commonality, a different approach would be to look at it from the outside, the user interface. As the same effect can be achieved by any number of variations in the code, looking at the code may result in the situation where you cannot see the wood for the trees, you cannot see "the big picture". If you look carefully at a transaction, any transaction, you should be able to describe it in terms of the following:
Another way to look at it is as follows:
With these characteristics it is possible to have transactions with the following combinations:
Each transaction pattern is therefore geared towards performing one or more pre-determined operations on one or more database tables, but the identities of these tables are not supplied until run time. Each pattern will also output its results in a particular format such as HTML, PDF, CSV, or even produce no output at all.
It has been my experience that a particular transaction pattern can be described in terms of its structure and behaviour, and it can be turned into a working transaction by adding in the missing ingredient, which is the content. Using the subroutine analogy, the pattern (structure and behaviour) can be regarded as a subroutine and the content (list of data names) can be regarded as its parameters. The reason for separating structure from behaviour it is to make it possible for different patterns to share the same structure but to have different behaviour.
When the different transactions are compared the differences can be expressed in nothing more than a few table/column names, so everything else can be deemed to be part of the "pattern" for this kind of transaction. If it is part of a pattern then why should the description of that pattern be duplicated in every transaction specification? Why should the code which supports that pattern be duplicated within individual transactions? By defining all this structure and behaviour into a series of reusable patterns it becomes possible to cut out an enormous amount of duplicate effort simply by referring to a central pattern.
There are basically just two ways in which data can be displayed - the List View and the Detail View. While some screens deal with a single database table there are some, such as the LIST2 pattern, which deal with several. In this case the top zone(s) will be shown using the Detail View while the bottom zone will be displayed using the List View.
The structure of each HTML document is defined in a separate XSL stylesheet. There are just twelve reusable XSL stylesheets in the entire framework.
This will list multiple rows from a single database table horizontally across the page. The top row will contain column labels while the following rows will contain the values for those columns.
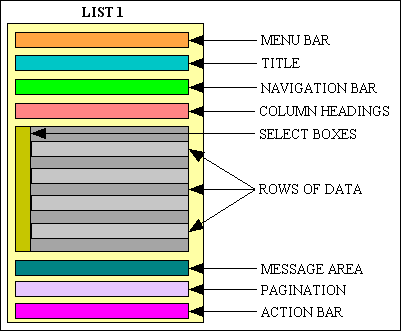
Each of these areas can be described as follows:
| Menu bar | A series of buttons or links which allows the user to jump to any part of the system. If an option which is selected is a menu the current list of options is replaced with a new list. If the selected option is a transaction then that transaction is activated, which causes the remainder of the screen to change. |
| Title | A brief description of the current transaction. |
| Navigation Bar | A series of buttons or links, with a different set for each transaction, which allow the user to jump to a related transaction and to pass context to it. This usually means that the user can select one or more rows from the data area, then pass the identity of these rows to a related transaction for further processing. |
| Column Headings | A label which provides a heading above each column of data in the rows immediately beneath it. Each label is defined as a button or link which, when pressed, will cause the data to be re-fetched and sorted on that column, toggling between ascending and descending sequence. |
| Select Boxes | A checkbox in front of each row of data which allows one or more rows to be selected before pressing a navigation button to pass that selection to another transaction. |
| Rows of Data | Each horizontal line shows data from a different record (row) in the database, and is limited to a subset of the available columns (fields) which can fit onto a single line. The number of lines is usually limited to what can reasonably be viewed at a single time, perhaps 10 or 20 or so, and is referred to as a "page" of data. Alternate rows will be shown in different colours. |
| Message Area | An area which will be used to display any warnings or messages. |
| Pagination Area | A large volume of data is broken down into smaller "pages" which are displayed one page at a time. The pagination area contains links which allow the user to move backwards or forwards through the available pages. |
| Action Bar | A series of buttons which perform actions at the transaction level, not at the individual row level, such as CLOSE to terminate the transaction or RESET to set any sorting or selection criteria to their initial values. |
This will display a single row vertically down the page with column labels on the left in front of values on the right.
")
Each of these areas can be described as follows:
| Menu bar | This will show the menu options which led to this screen. |
| Title | This is supplied at runtime. |
| Navigation Bar | This is usually empty for this type of function, but may contain buttons which will allow the user to select other functions which show more details related to the current occurrence. |
| Data Area | As this area is for a single occurrence the data will be shown vertically, one field per line, with data on the right and labels on the left. |
| Message Area | This will contain any messages or instructions. |
| Scrolling Area | This will provide options to scroll forwards and backwards through the selected items. |
| Action Bar | One or more buttons which will perform an action such as CLOSE, COPY or PASTE. |
While an XSL stylesheet dictates the structure of the resulting HTML document the way in which that document behaves is dictated by the Page Controller which performs one or more operations on one or more database tables. Each Controller performs a specific set of operations, and these operations can be performed on any table in the application.
| LIST/BROWSE | List multiple rows from that database table, with the ability to scroll through the rows one page at a time. There is no SUBMIT button as this function cannot update the database. |
| SEARCH | Show a screen containing empty fields into which the user can type search criteria. Pressing the SUBMIT button will return to the LIST screen which then refreshes itself using that criteria. |
| INSERT | Show a screen containing empty fields into which the user can type new values. Pressing the SUBMIT button will send that data to the server which will then add that record to the database before returning to the LIST screen which will refresh itself. |
| UPDATE | Show a screen containing current values for the selected record and allow the user to change any values. Pressing the SUBMIT button will send that data to the server which will then update that record in the database before returning to the LIST screen which will refresh itself. |
| DELETE | Show a screen containing current values for the selected record. Pressing the SUBMIT button will send a request to the server which will then delete that record before returning to the LIST screen which will refresh itself. |
| ENQUIRE | Show a screen containing current values for the selected record. There is no SUBMIT button as this function cannot update the database. |
In order to produce an HTML document the application data is extracted from the table object(s) and copied to an XML document and then transformed into HTML using an XSL stylesheet. No stylesheet contains any information regarding what application data is to be displayed on the screen as this information is supplied in a screen structure file whose contents are then copied to the screen structure element in the XML document. This is the mechanism by which a stylesheet can be used to display data from any table in the application.
For more details please refer to Reusable XSL Stylesheets and Templates
This file is initially created by the framework, but can be amended by the developer.
<?php $structure['xsl_file'] = 'std.detail1.xsl'; $structure['tables']['main'] = 'person'; $structure['main']['columns'][] = array('width' => 150); $structure['main']['columns'][] = array('width' => '*'); $structure['main']['fields'][] = array('person_id' => 'ID'); $structure['main']['fields'][] = array('first_name' => 'First Name'); $structure['main']['fields'][] = array('last_name' => 'Last Name'); $structure['main']['fields'][] = array('initials' => 'Initials'); $structure['main']['fields'][] = array('nat_ins_no' => 'Nat. Ins. No.'); $structure['main']['fields'][] = array('pers_type_id' => 'Person Type'); $structure['main']['fields'][] = array('star_sign' => 'Star Sign'); $structure['main']['fields'][] = array('email_addr' => 'E-mail'); $structure['main']['fields'][] = array('value1' => 'Value 1'); $structure['main']['fields'][] = array('value2' => 'Value 2'); $structure['main']['fields'][] = array('start_date' => 'Start Date'); $structure['main']['fields'][] = array('end_date' => 'End Date'); $structure['main']['fields'][] = array('selected' => 'Selected'); ?>
This is how the contents of the PHP file appears after it has been copied into the XML document so that it can be processed during the XSL Transformation.
<structure>
<main id="person">
<columns>
<column width="150"/>
<column width="*"/>
</columns>
<row>
<cell label="Id"/>
<cell field="person_id"/>
</row>
<row>
<cell label="First Name"/>
<cell field="first_name"/>
</row>
<row>
<cell label="Last Name"/>
<cell field="last_name"/>
</row>
<row>
<cell label="Initials"/>
<cell field="initials"/>
</row>
<row>
<cell label="Nat. Ins. No."/>
<cell field="nat_ins_no"/>
</row>
<row>
<cell label="Person Type"/>
<cell field="pers_type_id"/>
</row>
<row>
<cell label="Star Sign"/>
<cell field="star_sign"/>
</row>
<row>
<cell label="E-mail"/>
<cell field="email_addr"/>
</row>
<row>
<cell label="Value 1"/>
<cell field="value1"/>
</row>
<row>
<cell label="Value 2"/>
<cell field="value2"/>
</row>
<row>
<cell label="Start Date"/>
<cell field="start_date"/>
</row>
<row>
<cell label="End Date"/>
<cell field="end_date"/>
</row>
<row>
<cell label="Selected"/>
<cell field="selected"/>
</row>
</main>
</structure>
Being able to describe a transaction in terms of the pattern which it follows is one thing, but the biggest benefits can be obtained from the ability to implement new transactions as easily as:
Create transaction #3 by implementing pattern L1 with database table 'C'.
This means that the code which implements the pattern does not have to be generated by hand, instead an existing block of pre-written code is referenced, merged with the relevant data, and a working transaction is instantly available. But how can it be possible for patterns to be implemented in such a manner? This depends entirely on the language which is being used:
The disadvantage with the compiled option is that each transaction is actually carrying around a copy of the pattern code, so it may not be possible to incorporate subsequent changes to the pattern into any transactions without going through the generation process again. A better option would be the ability to change the pattern code and to have those changes automatically inherited by the transactions without manual intervention.
With a web application the latter option is eminently possible as each page of HTML is generated completely from scratch instead of being provided in pre-compiled form. Furthermore, by having each page generated by XSL transformations it is possible to have the page layout defined within an XSL stylesheet, and to use the same XSL stylesheet for every implementation of that pattern.
If the framework of the web application is built around the Model-View-Controller design pattern this allows the Structure-Behaviour-Content of each transaction to be defined as follows:
It is therefore possible to express each transaction pattern as a combination of View (structure) and Controller (behaviour) and a working transaction can be implemented simply by adding in a particular Model (content). If all the Views and Controllers come pre-built into the application framework, then once the Models for each database table are built the construction of individual transactions becomes no more complicated than "use this View and this Controller with this/these Model(s)". Just think how much developer effort that would save! My framework contains just 12 reusable stylesheets and 38 reusable controllers, and using these I have been able to build applications which contain thousands of transactions in a fraction of the time it would take using non-reusable modules.
The Radicore framework includes the ability to generate fully functioning application transactions using this library of transaction patterns - simply select a database table, select a pattern, press a button and all the necessary pieces will be created for you. This procedure is documented in Radicore for PHP - Tutorial in the Generate Transactions section.
By using transaction patterns it is possible to gain the following advantages:
Some people seem to think that these transaction patterns are very limited in scope and are unable to deal with anything other than the most simple of circumstances. That just shows that they have not examined the wide range of transactions which are built into the Radicore framework to see how they are implemented. Every single transaction is built from a pattern, and some transactions which are built from the same pattern do entirely different things, so how is this possible?
The first thing that is required is an understanding of how a pattern works. A pattern is a combination of a reusable controller and view which acts upon an undefined model. A small number of patterns do not produce visible output, so do not have a view. Each controller calls a different preset series of methods on a model whose identity is not provided until it is incorporated into an actual transaction. The controller and view, because they are unchangeable, contain those functions and features that do not vary between different implementations of the same pattern, which means that any transaction-specific behaviour must be built into the model.
When a controller calls a method on a model this method, which is defined within the abstract table class from which each individual database table subclass is extended, is simply the first in a chain of methods which are called to carry out the required processing. This "chain" of methods, which is pictured in UML diagrams for the Radicore Development Infrastructure, contains some dummy customisable methods which are identified by their "_cm_" prefix. For each operation there is usually a "_cm_pre_whatever" method which is called before the event, and a "_cm_post_whatever" method which is called after the event. Each of these customisable methods is defined in the abstract table class as an empty stub, so by default they do absolutely nothing. However, any one of these empty stubs can be copied into a database table subclass and filled with code, in which case that code will be executed instead of the empty stub. So, by placing customised code into an otherwise empty stub, it is possible for any transaction to execute code which is not contained within the controller. This customisable code may either be executed instead of or in addition to the standard code, so the possibilities are endless.
Take, for example, the following requirement:- the user selects an entry from the ARTICLE table, then presses a button to send an e-mail about that article to all registered users. How can this be done if there is no "send e-mail" pattern? The answer is to modify the custom methods for the UPDATE 1 pattern as follows:
_cm_initialise() method which sets all the fields in the update screen to NOEDIT. This means that the user cannot amend any values, but still has a SUBMIT button. This method can also generate a message to the effect "Press SUBMIT to send an e-mail"._cm_post_getData() method which examines the selected entry to ensure that the EMAIL_SENT field is FALSE to ensure that the same e-mail is not sent more than once._cm_pre_updateRecord() method which reads the table of registered users to obtain their e-mail addresses, constructs and sends an e-mail, then sets the EMAIL_SENT field to TRUE. The following call to _dml_updateRecord() will update the database.Another transaction which has a different level of complexity is the IMPORT COLUMNS function in the data dictionary. For a given table name it will obtain the current details from the database schema, then issue the necessary INSERT, UPDATE and DELETE statements to keep the dictionary database synchronised. This is achieved by modifying the custom methods for the ADD 4 pattern as follows:
_cm_getInitialDataMultiple() method which gets the current column details from the database schema, then the current column details from the dictionary database. It compares the two and constructs three arrays - one for records to be inserted, one for records to be updated, and one for records to be deleted. The first array will automatically be processed by the standard insertMultiple() method while the others must be stored for later processing._cm_post_insertMultiple() method which will be automatically executed after the standard insertMultiple() method. This then takes the other two arrays created previously and passes them manually to the deleteMultiple() and updateMultiple() methods. Note that any or all of these arrays can be empty without causing an error - an empty array simply causes that processing to be skipped.In a similar vein is the EXPORT TABLE function which takes all the details for a given database table from the dictionary and creates two non-database files. This is achieved by modifying the custom methods for the UPDATE 4 pattern as follows:
_cm_post_getData() method which takes the selected table name, retrieves the relevant data and writes it out to the non-database files. This returns an empty array so that the subsequent call to the updateMultiple() method does not have to do anything.As you can see this arrangement of standard and customisable methods in each model object leads to endless possibilities, so how can this be described as inflexible?
Some people seem to think that transaction patterns do not exist for the simple reason that the Gang of Four did not write about them. In my opinion such people fall into one of two categories:
If transaction patterns do not exist then how come I can not only describe them in great detail but also build the means to implement them? Twice. In two different languages.
If you do not believe that transaction patterns actually exist then I dare you to take this challenge:
If you notice a difference would you possibly concede that maybe, just maybe, there might be something in what I have to say?
| 17 Jan 2025 | Added Structure, Behaviour and Content. |
| 18 Oct 2006 | Amended Making transaction patterns easy to implement by adding a reference to Radicore Tutorial - Generate Transactions. |
| 28 May 2006 | Added How flexible are Transaction Patterns? |