A component in a 1-Tier structure contains all the code necessary to deal with the user interface, the data validation, and all communication with the physical database. Where several components access the same data objects (files, tables or entities - whatever you want to call them) there can quite a bit of duplication. Apart from having to spend extra time in the first place to create components with similar code it also means that any subsequent changes to data objects or business rules would then require the same code changes to be replicated in what could turn out to be a large number of components.
Each new methodology always distinguishes itself by using new words for old ideas, so as I am from the ‘old school’ I use the following translation table:
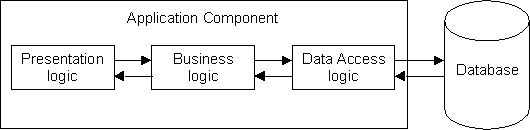
- Presentation logic = User Interface, displaying data to the user, accepting input from the user.
- Business logic = Data Validation, ensuring the data is kosher before being added to the database.
- Data Access Logic = Database Communication, accessing tables and indices, packing and unpacking data.
A component based on the 1-Tier structure can therefore be represented in shown in figure 1:
Figure 1 - The 1-Tier Structure
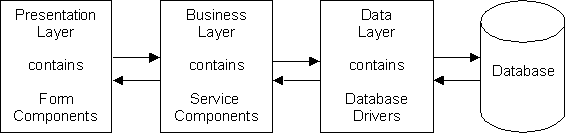
In a 2-Tier structure the logic is split into two tiers (or layers), usually done by splitting off the data access logic. This results in the structure shown in figure 2:
Figure 2 - The 2-Tier Structure
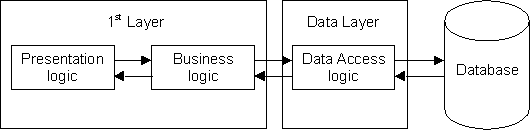
This removes all the complexities of communicating with the database to a separate layer. It should therefore be possible to switch to a different database system just by changing the contents of the data layer. Provided that the operations and signatures with the 1st layer remain consistent there should be no need to modify any component in the 1st layer.
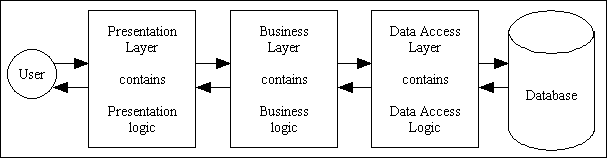
This splits each of the three logical areas into its own layer. For this structure to work effectively there should be clearly defined interfaces between each of the layers. This should then enable components in one layer to be modified without requiring changes any changes to components in other layers. One example is changing the file system from one DBMS to another, or changing the user interface from one system to another (e.g. from client/server to the web).
The main advantage of this structure over the 2-Tier system is that all business logic is contained in its own layer and is shared by many components in the presentation layer. Any changes to business rules can therefore be made in one place and be instantly available throughout the whole application.
Figure 3 - The 3-Tier Structure
- Background:
Uniface was originally designed around the 3-Schema, 2-Tier architecture.
The 3-Schema Architecture is comprised of:
- The External Schema (ES), or user’s view of the data (implemented as forms).
- The Conceptual Schema (CS), or logical view of the database structure (as referenced within forms).
- The Physical Schema (PS), or physical database structure (as referenced by the database driver).
The Physical Schema does not exist as a separate object, it is held as entity or field interface definitions within the Conceptual Schema.
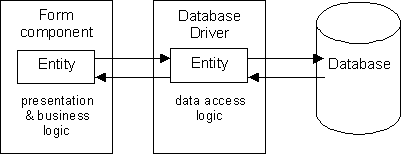
A form (ES) is built by defining which entities from the CS need to be referenced, then painting the necessary fields within the boundaries of each entity. When a <read> or <write> trigger is fired control is automatically passed to the database driver which performs the necessary action on the physical database.
This can be represented in the structure shown in figure 4:
Figure 4 - UNIFACE and the 2-Tier Structure
Since these early days (I started with version 5 in 1992) Uniface has undergone a few changes:
- The Conceptual Schema has been renamed as the Application Model.
- Forms have been split into 3 types of Component - Form components (with user dialog), Service components (without user dialog), and Report Components.
- Components can be built from component templates. Not only does this make the original construction of a component a lot quicker, but the inheritance of form-level trigger code means that certain changes can be made once in the template, then automatically included in every associated component when it is next compiled. I have been using component templates since May 1997, so I can certainly vouch for their efficacy.
- UNIFACE and the 3-Tier structure.
In order to provide a relatively painless method of splitting the business logic from the presentation logic in the form component Compuware introduced the concept of Object Services in Uniface v7.2.04. The UNIFACE view of the 3-tier structure can be represented by the structure shown in figure 5:
Figure 5 - UNIFACE and the 3-Tier Structure
Each database entity has its own object service in which all business logic can be defined. For certain one-to-many relationships it is also possible to create a single object service for both of those entities. By including the relevant business rules in each object service it means that these rules need not be replicated in any form component. Provided that the form’s access to the database is routed through the object service (there is a data access switch on each entity within each form), the rules within the object service are instantly available to the form. As an aid to performance, if several forms in the same session access the same entity at the same time, they will actually share the same object service for that entity.
As well as having the code for the various rules defined in the field or entity validation triggers within the object service itself it is also possible to move this code into a separate component which is activated from the object service. I have tried both approaches with success.
- Implementation of Object Services.
Compuware have made the process of creating and using object services very, very easy. The procedure is as follows:
- For each entity within the application model use the pulldown menu to select Edit, Generate Object Service. You will be prompted for a name - a default is provided, but you may override if you wish.
- Click the ‘OK’ button and the object service will automatically be created from a component template (supplied by Compuware), and the component name will be loaded into the screen.
- Change the Default Data Access from ‘DBMS Path’ to ‘Object Service’.
- Provided that the Data Access is not changed within any form component, when it is next compiled it will switch all access of that entity to the nominated object service.
For existing form components that were assembled in a 2-tier structure the only change that needs to be made to any code is to move the business logic from the form into the relevant object service. No code needs to be changed in the form in order to communicate with an object service - it is totally transparent. As soon as any database trigger is fired on an entity where the Data Access flag has been set to ‘Object Service’ Uniface will automatically route all activity through that object service.
- Validation via Object Services
The main difference with using business rules in object services is that field validation in the form is limited to declarative checking only. All other validation can only be performed when the <STORE> trigger is fired. This appears to be a backward step (it reminds me of my days using a block mode user interface with green screens), but it emulates the behavior of forms that are deployed on the web. Forms which are constructed in this fashion will therefore not need massive conversion before being enabled for the web.
If the idea of data validation ‘en bloc’ is not acceptable in a client/server environment there is a method of combining the advantages of object services with the immediacy of field-by-field validation:
- First, create a new operation in the object service that contains an occurrence parameter and an optional fieldname parameter. If the field name is provided then perform the
validatefieldcommand, otherwise perform thevalidateocccommand. - Second, create a global proc which activates the new operation. This would be used in your code as follows:
In a field’s <LEAVE FIELD> or <VALIDATE FIELD> trigger:
call VLDF_OBJSVC($entname, $fieldname)
In an entity’s <LEAVE MOD OCC> or <VALIDATE OCC> trigger:
call VLDF_OBJSVC($entname, "")
This then gives you the ability to perform field-by-field validation without having the code embedded in the form. I have produced some working examples of this, so if you would like a copy of my code please contact me using the e-mail address at the foot of this document.
- First, create a new operation in the object service that contains an occurrence parameter and an optional fieldname parameter. If the field name is provided then perform the
The name implies a structure which contains ‘N’ number of tiers where ‘N’ is a variable number. This is usually achieved by taking a component in one of the standard layers of the 3-Tier structure and breaking it down into subcomponents, each performing a specific low-level task.
For example, the designers of a project with which I am currently acquainted (sadly) has broken down each of the initial three layers into something which resembles the structure shown in figure 6:
Figure 6 - Splitting 3 layers into ‘N’ layers
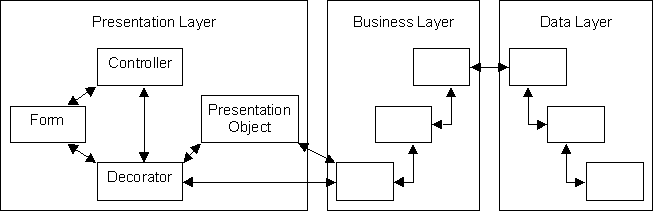
The function of each of these components is described in the following table:
| Form | Interacts with the user. Uses the Decorator to read and write all data. |
| Controller | Controls the flow of a use case, navigating from one form to another in the correct sequence. |
| Decorator | Interface between the presentation layer and the business layer. Obtains data for a form and distributes data from a form when database updates are required. |
| Presentation Object | Presentation logic for a use case. Used for logic which is specific to a use case rather than a business object. |
| Business Component Interface | One per domain or logical group of entities. |
| Business Object | Business object for a logical entity. Contains all the business rules for that entity. |
| Business Service Bridge | Business component to business component interface. |
| View | An indexed list of keys for an object. |
| Translator | Translation between the logical data layer and the physical data layer. |
| Cache | Holds business data for a use case. |
| Data Service | Performs physical database IO. |
The resulting structure may appeal to academics, theoreticians and exponents of the latest fashionable methodologies, but it falls down in one serious respect - it takes far too long to develop usable software. After a team of 6 people spent 6 months in prototyping, the time came to build the first real use case. It consisted of two simple screens - one to enter selection criteria and a second to list the results, using a single database table. It took the team 2 weeks. Notice I said ‘team’ (6 people) and not ‘developer’ (single person), giving a total of 12 man-weeks for a simple two-screen use case. Six months later the level of productivity has increased - it still takes 2 weeks per use case, but now with just a single developer.
Having spent a life time in a commercial environment where productivity was always the prime consideration I am used to constructing working transactions in hours and days, not weeks and months. To put things in perspective the last project I worked on (albeit an in-house project) required 50 forms accessing 19 database tables with 18 relationships. Using my own ready-made infrastructure and development standards I designed it in one week, then built and tested it in four weeks. That’s an average of 2.5 forms per day, but on good days I peaked at six.
I do not consider the level of productivity from this new N-Tier architecture to be acceptable, and I don’t think that many paying customers would either. The architects of this structure spent too much time in bending UNIFACE to fit their particular interpretation of the rules. This dogmatic approach diverted their attention from the real purpose of software development, which is to turn user requirements into usable software as quickly as possible. This ‘politically correct’ structure just will not succeed in a competitive market place.